故障分析:数据库一致性关闭缓慢问题诊断

想必我们大家都知道,Shutdown immediate即一致性关闭数据库,数据库下次启动不需要做实例恢复即可open数据库。那么当数据库一致性关闭出现缓慢等状况时,该怎么办呢?那我们就来一起分析一下,数据库一致性关闭缓慢问题。
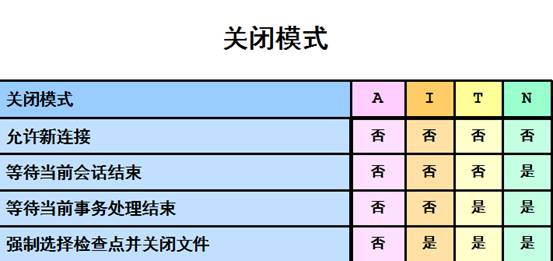
从以上图得知在shutdownimmediate关闭数据库只需要在数据库中强制选择检查点并关闭文件,不需要等待当前事物处理结束,不需要等待当前会话结束,不允许新连接。
processes still continue to beconnected to the database and do not terminate
> > > >
如果数据库在关闭的时候,有进程持续连接数据,并且不能被中断,就会造成shutdown immediate slowly或者hanging
>>>>
SMON is cleaning temp segments orperforming delayed block cleanouts
>>>>
Temp segment cleanup: 在数据库中如果有大量的sql做排序操作,pga中分配的sort_area_size太小,不能满足排序的需要时候,就会占用临时段进行排序,这些分配的临时段分区,一旦分配,直到数据库shutdown 的时候才会释放。所以当我在进行数据库关闭时,有大量的临时分区被分配需要立刻被释放,这会引起row cache 的资源竞争,从而导致数据库shutdownimmediate变慢或者hanging。
> > > >
当数据库需要以一致性关闭数据库时,如果此刻数据库中正好存在运行的大事物,这时候数据库需要对大事物进行回滚(请不要误解之前提到的知识点,之前提到shutdown immediate 不需要等待事物是指不要等待此事物提交结束,而是要对此刻所有未提交的事物进行回滚),因为大事物的回滚需要很长的时间,所以就会在执行shutdownimmediate时感觉solwly或者hanging。当然对于事物的回滚,我们可以通过设置隐藏参数来加快回滚,但是另外考虑到高速的回滚设置会引起资源竞争,这样可能会加剧shutdown immediate变慢(有的特殊情况除外)
Oracle BUG oracle的某些BUG也会导致shutdownimmedaite变慢
以下是我在mos上搜索的BUG证明BUG也会导致shutdown immediate
Bug 6512622 - SHUTDOWN IMMEDIATE hangs / OERI[3708] (文档 ID 6512622.8)
Bug 5057695: Shutdown Immediate Very Slow To CloseDatabase (文档 ID 428688.1)
Bug 23309880 - SHUTDOWN IMMEDIATE may hang on primarydatabase if DG broker is configured (文档 ID 23309880.8)
当数据库需要进行一致性关闭时,建议首先去检查下一些视图用来进行确认。
1>for large queries
select count(*) from v$session_longops where time_remaining>0;
通过以上SQL查询数据库当前环境是否存在长会话操作
2>for large transactions
select sum(used_ublk) from v$transaction;
通过以上SQL查询数据库中此时是否存在大事物操作
当我们查询出来第一个sql的值大于0或者第二个sql是一个很大的值,在执行shutdown immediate 的时候就会相对花费一个比较长的时间。
当查询出来第一个值大于0,第二个值为0时,我们可以在执行shutdown immedaite slowly时改用shutdown abort来关闭数据库,因为此时数据库中是没有事物在运行的,我们使用shutdown abort来关闭数据库,下次启动数据库很容易就会达到一致性的状态。
对于查询出来第一个值大于0,第二个值也是一个很大值的情况,shutdown abort的操作就不适用,尤其是当我们需要对数据库进行冷备份的时候,必须一致性关闭。另外如果在存在大事物时强制关闭数据库,会导致数据库在下次启动需要花费大量时间,也有可能会导致数据库不能正常open(因为有可能发生下次数据库启动时,在线日志损坏)
另外如果有大事物正在运行,我们可以通过一些脚本去评估事物回滚或者commit的操作哪个会在最短的时间执行完成,从而确认是等待当前事物提交结束执行shutdown immedaite还是rollback 事物后执行shutdown immediate。
最直接的方法当然是查看alert和trace日志了。
通过查看alter和trace日志我们就可以看到数据库shutdown immediate是否是因为数据库正在做临时段清除操作或者是一些进程持续连接数据库无法正常中断又或者是因为Oracle 的某种BUG导致的shutdown immediate slowly and hanging
如果我们发现是因为临时段清除导致的数据库无法正常关闭,也可以通过shutdown abort的方式重启数据库。
当是因为一些数据库连接无法正常终止而导致的数据库shutdown immedaite slowly and hanging,我们可以在操作系统层面采用Kill 方式终止进程之后,再采用shutdown immediate的方式关闭数据库
当是因为某些BUG导致的shutdown immediate slowly and hanging,我们可以通过查询MOS来确认数据库BUG,进而通过打补丁的方式解决问题。
当我使用shutdown immediate停止某一套数据库环境的时候,发现数据库停止hang waiting(数据库版本11.2.0.1)
首先我查看alert日志,在alter日志中发现以下信息:
Shutting down instance (immediate)
Stopping background process SMCO
Shutting down instance: further logons disabled
Stopping background process QMNC
Stopping background process MMNL
Thu Aug 05 13:28:48 2010
Background process MMNL not dead after 10 seconds
Killing background process MMNL
Stopping background process MMON
Thu Aug 05 13:29:20 2010
Background process MMON not dead after 30 seconds
Killing background process MMON
License high water mark = 1
Thu Aug 05 13:34:23 2010
Active process 12377 user 'oracle' program 'oracle@bsf14f(MMON)'
Active process 12377 user 'oracle' program 'oracle@bsf14f(MMON)'
Active process 22755 user 'oracle' program 'oracle@bsf14f(M000)'
Active process 22755 user 'oracle' program 'oracle@bsf14f(M000)'
SHUTDOWN: waiting for logins to complete.
从以上信息我们可以看到数据库shutdown 正在等待mmon和mmon的slave进程终止,数据库无法正常终止进程
查看完alert日志之后,因为无法看到更详细的信息,因此做了dump systemstate分析
从systemstate中查看到以下信息:
(latch info) wait_event=0 bits=100
holding (efd=4) 38000b808 ksuosstats global area level=8
Location from where latch is held: ksu.h LINE:12921ID:ksugetosstat:
Context saved from call: 0
state=busy [holder orapid=16] wlstate=free [value=0]
waiters [orapid (seconds since: put on list, posted, alivecheck)]:
27 (985, 1281008063, 985)
waiter count=1
Process Group: DEFAULT, pseudo proc: 0x3bf51c538
O/S info: user: oracle, term: UNKNOWN, ospid: 12379 (DEAD)
OSD pid info: Unix process pid: 12379, image: oracle@bsf14f(MMNL)
从以上信息可以看到mmnl持有latch from ksugetosstat.
另外通过操作系统命令truss进程得到以下信息:
22395: open("/dev/kstat", O_RDONLY) = 19
22395: ioctl(19, KSTAT_IOC_CHAIN_ID, 0x00000000) = 227215
22395: ioctl(19, KSTAT_IOC_READ, "kstat_headers")Err#12 ENOMEM
22395: ioctl(19, KSTAT_IOC_READ, "kstat_headers") =227215
22395: ioctl(19, KSTAT_IOC_READ, "cpu_info352") =227215
22395: ioctl(19, KSTAT_IOC_READ, "cpu_info353") =227215
22395: ioctl(19, KSTAT_IOC_READ, "cpu_info354") =227215
...
22395: close(19) = 0
22395: open("/dev/kstat", O_RDONLY) = 19
22395: ioctl(19, KSTAT_IOC_CHAIN_ID, 0x00000000) = 227215
22395: ioctl(19, KSTAT_IOC_READ, "kstat_headers")Err#12 ENOMEM
22395: ioctl(19, KSTAT_IOC_READ, "kstat_headers") =227215
22395: ioctl(19, KSTAT_IOC_READ, "sysinfo") = 227215
22395: ioctl(19, KSTAT_IOC_READ, "cpu_stat352") =227215
22395: ioctl(19, KSTAT_IOC_READ, "cpu_stat353") =227215
从以上信息我们可以看到进程从在loop。
通过得知以上信息之后怀疑是oracle 11.2.0.1的BUG,因此查询MOS,在MOS查询文档确实是因为Oracle 11.2.0.1的BUG:Bug 9132776 - AWR SNAPSHOT NOT GENERATED AFTER 11.2 UPGRADE导致,最后应用补丁 one off Patch 9132776解决。
![]()
相关阅读:
Oracle RAC DRM引起性能问题案例
如何计算Oracle Block的校验值
有关延迟块清除和一致性读
SQL性能突然降低引起的业务办理缓慢案例
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
‘2017DTC’,2017DTC大会PPT
‘DBALIFE’,“DBA的一天”海报
‘DBA04’,DBA手记4经典篇章电子书
‘INTERNALS’,Oracle RAC PPT
‘122ARCH’,Oracle 12.2体系结构图
‘2017OOW’,Oracle OpenWorld资料
‘PRELECTION’,大讲堂讲师课程资料
