使用PHP的curl爬取百度搜索页相关搜索词
使用PHP获取百度搜索的第一个相关搜索词
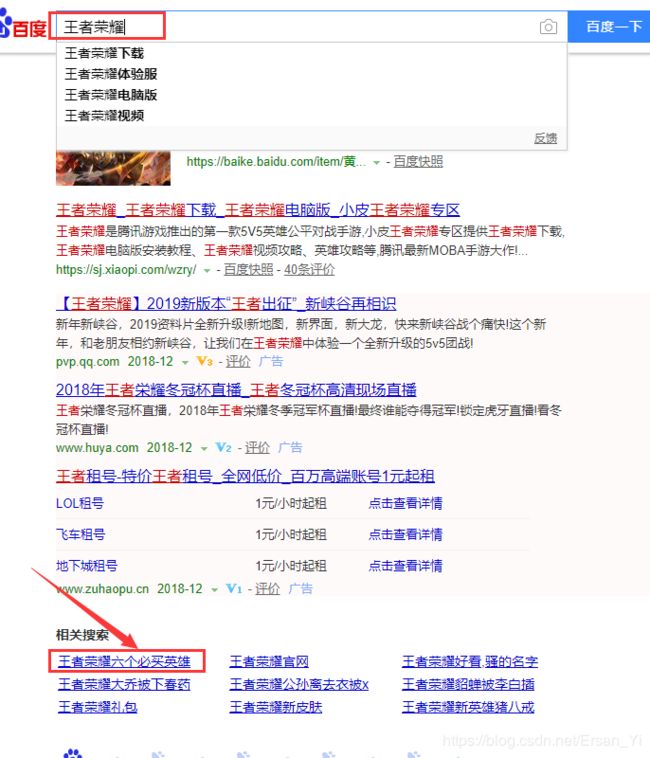
详细代码如下
$key_word = urlencode('王者荣耀');//需要对关键词进行url解析,否者部分带字符的标题会返回空
$url = 'https://www.baidu.com/s?ie=UTF-8&wd='.$key_word;
$res = curl_request($url);
$reach_word = substr($res,strpos($res, '相关搜索'),strpos($res, '')-strpos($res, '相关搜索') );//截取需要的内容
preg_match('/(.*?)<\/a>/', $reach_word,$match);//正则匹配第一个搜索词
$reach_word = @$match[1];
//curl获取百度内容
function curl_request($url, $data=null, $method='get', $https=true){
$ch = curl_init();//初始化
curl_setopt($ch, CURLOPT_URL, $url);//访问的URL
curl_setopt($ch, CURLOPT_HEADER, false);//设置不需要头信息
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);//只获取页面内容,但不输出
if($https){
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);//https请求 不验证证书
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);//https请求 不验证HOST
}
curl_setopt($ch,CURLOPT_ENCODING,'gzip');//百度返回的内容进行了gzip压缩,需要用这个设置解析
//curl模拟头部信息
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'Accept: */*',
'Accept-Encoding: gzip, deflate, br',
'Accept-Language: zh-CN,zh;q=0.9,en;q=0.8',
'Connection: keep-alive',
'Host: www.baidu.com',
'is_referer: https://www.baidu.com/',
'is_xhr: 1',
'Referer: https://www.baidu.com/',
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'X-Requested-With: XMLHttpRequest',
));
if($method == 'post'){
curl_setopt($ch, CURLOPT_POST, true);//请求方式为post请求
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);//请求数据
}
$result = curl_exec($ch);//执行请求
curl_close($ch);//关闭curl,释放资源
$result = mb_convert_encoding($result, 'utf-8', 'GBK,UTF-8,ASCII,gb2312');//百度默认编码是gb2312 这个设置转化为utf8编码
return $result;
}