Hadoop2.x实战:Eclipse本地开发环境搭建与本地运行wordcount实例
林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
摘要:本文主要讲了如何在windows上通过eclipse来远程运行hadoop应用程序
hadoop版本:2.7.2
hadoop安装系统:ubuntu14.04
eclipse版本:luna
eclipse安装系统:window64
一、开发环境配置
1、windows下载源码
到http://hadoop.apache.org/releases.html 下载源码如下:
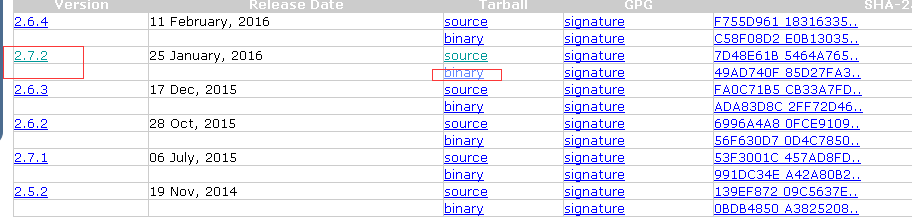
解压后放在一个地方:
2、安装hadoop-eclipse-plugin-2.7.2.jar(具体版本视你的hadoop版本而定)
下载地址:http://download.csdn.net/detail/tondayong1981/9432425
首先把hadoop-eclipse-plugin-2.7.2.jar(具体版本视你的hadoop版本而定)放到eclipse安装目录的plugins文件夹中,如果重新打开eclipse后看到有如下视图,则说明你的hadoop插件已经安装成功了:
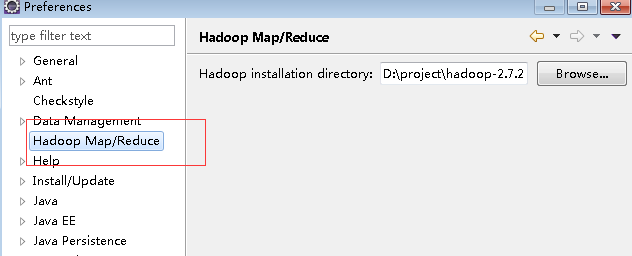
其中的“hadoop installation directory”配置项用于指向你的hadoop安装目录(就是上一步的hadoop解压后的目录),在windows下你只需要把下载到的hadoop-2.7.2.tar.gz包解压到某个位置,然后指向这个位置即可。
3、配置连接参数
选择windwos->show view->others
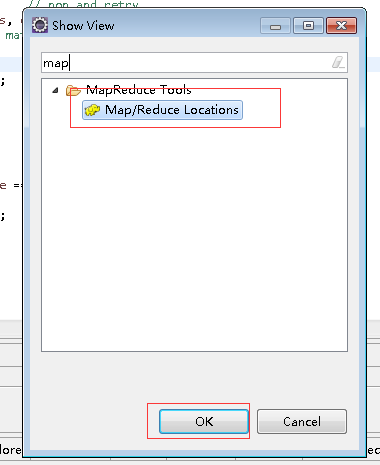
确定后在弹出的窗口中选择map/reduce locations,然后右键New Hadoop location
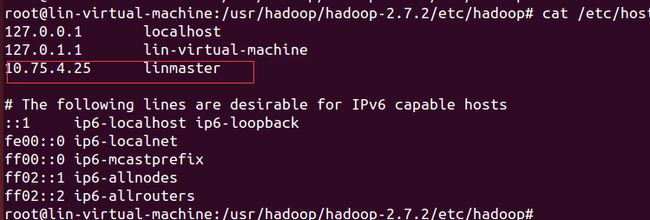
注意,这里的linmaster指代的是linux的地址:
其对应的关系在:C:\Windows\System32\drivers\etc\hosts
# Copyright (c) 1993-2009 Microsoft Corp.
#
# This is a sample HOSTS file used by Microsoft TCP/IP for Windows.
#
# This file contains the mappings of IP addresses to host names. Each
# entry should be kept on an individual line. The IP address should
# be placed in the first column followed by the corresponding host name.
# The IP address and the host name should be separated by at least one
# space.
#
# Additionally, comments (such as these) may be inserted on individual
# lines or following the machine name denoted by a '#' symbol.
#
# For example:
#
# 102.54.94.97 rhino.acme.com # source server
# 38.25.63.10 x.acme.com # x client host
# localhost name resolution is handled within DNS itself.
#127.0.0.1 localhost
#10.75.4.22 localhost
10.75.4.25 linmaster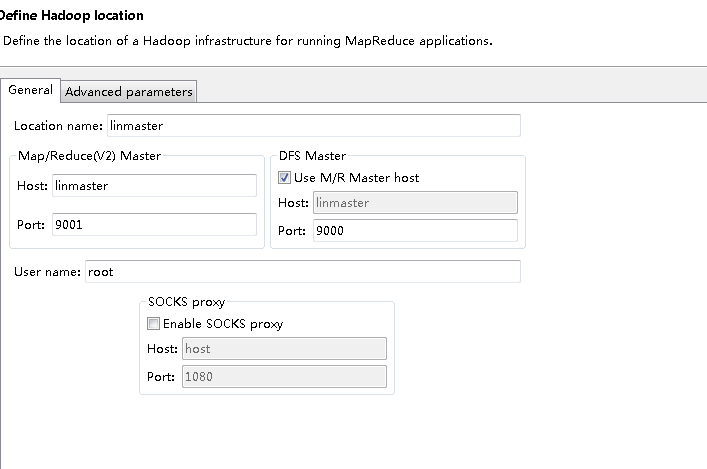
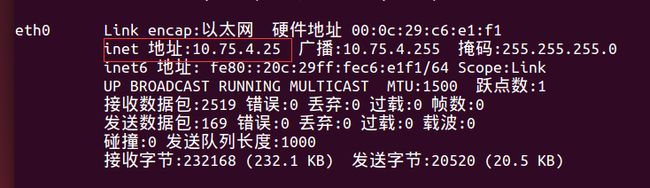
一定在注意,这里的地址一定要和linux上的一样
在ubuntu中输入ifconfig
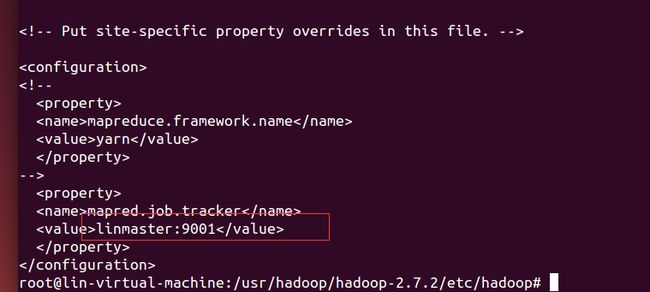
其中Map/Reduce Master配置和 mapred-site.xml相关(注意linmaster指定IP地址,要在etc/hosts中配置)
DFS master配置和linux上的core-site.xml 相关(注意linmaster指定IP地址,要在etc/hosts中配置)

IP地址和名称映射配置
vi /etc/hosts 就可以添加 了
上面全部设置好了之后。先启动hadoop。然后在Eclipse资源管理器中,点击DFS Locations就可展开,说明连接成功。

二、本地运行hadoop应用
1、创建一个maven项目,引入jar,POM.XML如下
4.0.0
com.func
axc
0.0.1-SNAPSHOT
axc-hadoop
org.apache.hadoop
hadoop-common
2.2.0
org.apache.hadoop
hadoop-hdfs
2.2.0
org.apache.hadoop
hadoop-client
2.2.0
junit
junit
3.8.1
test
jdk.tools
jdk.tools
1.6
system
${JAVA_HOME}/lib/tools.jar
编写一个wordCount程序:
首先将hadoop安装在linux上的etc/hadoop下的文件放入到工程中。一定要注意是从你安装有Hadoop的linux机器 上拷贝下来的!
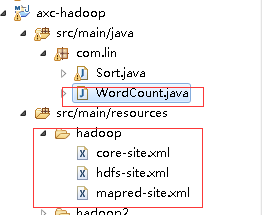
然后编写WordCount代码
package com.lin;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class WordCountMapper extends MapReduceBase implements Mapper {
private final static IntWritable one =new IntWritable(1);
private Text word =new Text();
public void map(Object key,Text value,OutputCollector output, Reporter reporter) throws IOException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word,one);//字符解析成key-value,然后再发给reducer
}
}
}
public static class WordCountReducer extends MapReduceBase implements Reducer {
private IntWritable result =new IntWritable();
public void reduce(Text key, Iteratorvalues, OutputCollector output, Reporter reporter)throws IOException {
int sum = 0;
while (values.hasNext()){//key相同的map会被发送到同一个reducer,所以通过循环来累加
sum +=values.next().get();
}
result.set(sum);
output.collect(key, result);//结果写到hdfs
}
}
public static void main(String[] args)throws Exception {
//System.setProperty("hadoop.home.dir", "D:\\project\\hadoop-2.7.2");
String input = "hdfs://linmaster:9000/input/LICENSE.txt";//要确保linux上这个文件存在
String output = "hdfs://linmaster:9000/output14/";
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("WordCount");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(WordCountMapper.class);
conf.setCombinerClass(WordCountReducer.class);
conf.setReducerClass(WordCountReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf,new Path(input));
FileOutputFormat.setOutputPath(conf,new Path(output));
JobClient.runJob(conf);
System.exit(0);
}
} 输出结果:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/D:/Java/Repository/org/slf4j/slf4j-log4j12/1.7.5/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/D:/Java/Repository/ch/qos/logback/logback-classic/1.0.13/logback-classic-1.0.13.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
16/06/19 16:12:45 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
16/06/19 16:12:45 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
16/06/19 16:12:45 INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
16/06/19 16:12:46 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
16/06/19 16:12:46 WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
16/06/19 16:12:46 INFO mapred.FileInputFormat: Total input paths to process : 1
16/06/19 16:12:46 INFO mapreduce.JobSubmitter: number of splits:1
16/06/19 16:12:46 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
16/06/19 16:12:46 INFO Configuration.deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
16/06/19 16:12:46 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/06/19 16:12:46 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
16/06/19 16:12:46 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
16/06/19 16:12:46 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
16/06/19 16:12:46 INFO Configuration.deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
16/06/19 16:12:46 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
16/06/19 16:12:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local536235441_0001
16/06/19 16:12:46 WARN conf.Configuration: file:/usr/hadoop/hadoop-2.7.2/tmp/mapred/staging/linbingwen536235441/.staging/job_local536235441_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
16/06/19 16:12:46 WARN conf.Configuration: file:/usr/hadoop/hadoop-2.7.2/tmp/mapred/staging/linbingwen536235441/.staging/job_local536235441_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
16/06/19 16:12:46 WARN conf.Configuration: file:/usr/hadoop/hadoop-2.7.2/tmp/mapred/local/localRunner/linbingwen/job_local536235441_0001/job_local536235441_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
16/06/19 16:12:46 WARN conf.Configuration: file:/usr/hadoop/hadoop-2.7.2/tmp/mapred/local/localRunner/linbingwen/job_local536235441_0001/job_local536235441_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
16/06/19 16:12:46 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
16/06/19 16:12:46 INFO mapred.LocalJobRunner: OutputCommitter set in config null
16/06/19 16:12:47 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapred.FileOutputCommitter
16/06/19 16:12:47 INFO mapreduce.Job: Running job: job_local536235441_0001
16/06/19 16:12:47 INFO mapred.LocalJobRunner: Waiting for map tasks
16/06/19 16:12:47 INFO mapred.LocalJobRunner: Starting task: attempt_local536235441_0001_m_000000_0
16/06/19 16:12:47 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
16/06/19 16:12:47 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@12e29f36
16/06/19 16:12:47 INFO mapred.MapTask: Processing split: hdfs://linmaster:9000/input/LICENSE.txt:0+15429
16/06/19 16:12:47 INFO mapred.MapTask: numReduceTasks: 1
16/06/19 16:12:47 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
16/06/19 16:12:47 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
16/06/19 16:12:47 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
16/06/19 16:12:47 INFO mapred.MapTask: soft limit at 83886080
16/06/19 16:12:47 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
16/06/19 16:12:47 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
16/06/19 16:12:47 INFO mapred.LocalJobRunner:
16/06/19 16:12:47 INFO mapred.MapTask: Starting flush of map output
16/06/19 16:12:47 INFO mapred.MapTask: Spilling map output
16/06/19 16:12:47 INFO mapred.MapTask: bufstart = 0; bufend = 22735; bufvoid = 104857600
16/06/19 16:12:47 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26205772(104823088); length = 8625/6553600
16/06/19 16:12:48 INFO mapreduce.Job: Job job_local536235441_0001 running in uber mode : false
16/06/19 16:12:48 INFO mapreduce.Job: map 0% reduce 0%
16/06/19 16:12:48 INFO mapred.MapTask: Finished spill 0
16/06/19 16:12:48 INFO mapred.Task: Task:attempt_local536235441_0001_m_000000_0 is done. And is in the process of committing
16/06/19 16:12:48 INFO mapred.LocalJobRunner: hdfs://linmaster:9000/input/LICENSE.txt:0+15429
16/06/19 16:12:48 INFO mapred.Task: Task 'attempt_local536235441_0001_m_000000_0' done.
16/06/19 16:12:48 INFO mapred.LocalJobRunner: Finishing task: attempt_local536235441_0001_m_000000_0
16/06/19 16:12:48 INFO mapred.LocalJobRunner: Map task executor complete.
16/06/19 16:12:48 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
16/06/19 16:12:48 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@6f0c29fe
16/06/19 16:12:48 INFO mapred.Merger: Merging 1 sorted segments
16/06/19 16:12:48 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 10982 bytes
16/06/19 16:12:48 INFO mapred.LocalJobRunner:
16/06/19 16:12:48 INFO mapred.Task: Task:attempt_local536235441_0001_r_000000_0 is done. And is in the process of committing
16/06/19 16:12:48 INFO mapred.LocalJobRunner:
16/06/19 16:12:48 INFO mapred.Task: Task attempt_local536235441_0001_r_000000_0 is allowed to commit now
16/06/19 16:12:48 INFO output.FileOutputCommitter: Saved output of task 'attempt_local536235441_0001_r_000000_0' to hdfs://linmaster:9000/output14/_temporary/0/task_local536235441_0001_r_000000
16/06/19 16:12:48 INFO mapred.LocalJobRunner: reduce > reduce
16/06/19 16:12:48 INFO mapred.Task: Task 'attempt_local536235441_0001_r_000000_0' done.
16/06/19 16:12:49 INFO mapreduce.Job: map 100% reduce 100%
16/06/19 16:12:49 INFO mapreduce.Job: Job job_local536235441_0001 completed successfully
16/06/19 16:12:49 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=11306
FILE: Number of bytes written=409424
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=30858
HDFS: Number of bytes written=8006
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=289
Map output records=2157
Map output bytes=22735
Map output materialized bytes=10992
Input split bytes=91
Combine input records=2157
Combine output records=755
Reduce input groups=755
Reduce shuffle bytes=0
Reduce input records=755
Reduce output records=755
Spilled Records=1510
Shuffled Maps =0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=514588672
File Input Format Counters
Bytes Read=15429
File Output Format Counters
Bytes Written=8006
三、问题及解决方法
在程序运行成功之前,你肯定会遇到如下问题:
1、
org.apache.hadoop.security.AccessControlException: Permission denied: user=linbingwen, access=WRITE, inode="/":hadoop:supergroup:drwxr-xr-x
解决办法:
在 hdfs-site.xml 添加参数:
dfs.permissions
false
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot create directory /output12/_temporary/0. Name node is in safe mode.
The reported blocks 17 has reached the threshold 0.9990 of total blocks 17. The number of live datanodes 1 has reached the minimum number 0. In safe mode extension. Safe mode will be turned off automatically in 4 seconds.
解决方法
bin/Hadoop dfsadmin -safemode leave3、
Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (无法定位登录配置)
解决方法:
C:\Windows\System32\drivers\etc 下hosts文件添加.这个要根据你linux上机器的配置不同而变化
10.75.4.25 linmaster
4、
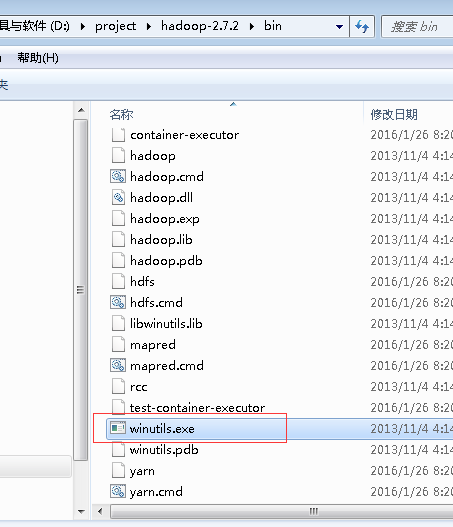
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
分析:
下载Hadoop2以上版本时,在Hadoop2的bin目录下没有winutils.exe
解决方法:
下载https://codeload.github.com/srccodes/hadoop-common-2.2.0-bin/zip/master下载hadoop-common-2.2.0-bin-master.zip,然后解压后,
把hadoop-common-2.2.0-bin-master下的bin全部复制放到我们下载的Hadoop2的binHadoop2/bin目录下。如图所示:
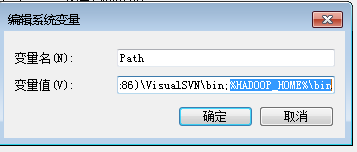
注意, 一定要重启电脑 才能生效。注意, 一定要重启电脑 才能生效。注意, 一定要重启电脑 才能生效。
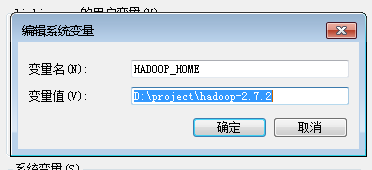
不想重启电脑可以在程序里加上:
System.setProperty("hadoop.home.dir", "E:\\Program Files\\hadoop-2.7.0");
注:E:\\Program Files\\hadoop-2.7.0是我本机解压的hadoop的路径。
5、
Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
分析:
C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
解决:
hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,笔者没有重启电脑就可以了