python爬虫实战(四):selenium爬虫抓取阿里巴巴采购批发商品
一、前言
本编教程是通过selenium爬取阿里巴巴采购批发网址的商品数据信息,并保存到mongo。为什么用selenium呢,是因为网站大多数不再是静态网站,而是有诸如Ajax请求的动态网站,如果接口好分析是个静态接口,那么还是用不着selenium,但是像淘宝这类的网站我们不好分析它的接口,因为接口是动态变化的。
github:https://github.com/FanShuixing/git_webspider/commit/e939ab29dd531384955050f9bef8615b1022c7ff
二、学习资料(感谢分享)
Ajax:[Python3网络爬虫开发实战] 6-Ajax数据爬取
selenium: Python3网络爬虫开发实战] 7-动态渲染页面爬取
pyquery: [Python3网络爬虫开发实战] 4.3-使用pyquery
MongoDB:[Python3网络爬虫开发实战] 5.3.1-MongoDB存储
三、开始爬取
1、先分析目标网址,为什么选择selenium
在搜索中输入女装,用F12查看源码,看看网页显示的内容是不是Ajax。点击Network,选择下面的XHR,按F5刷新页面,下滑浏览器商品页面

只有两个Ajax请求,而且Preview里面并没有代码。瞬间感觉天上掉馅饼了,难道是静态网页没有其他数据请求吗?如果是这样直接弄个pyquery解析网页就是了
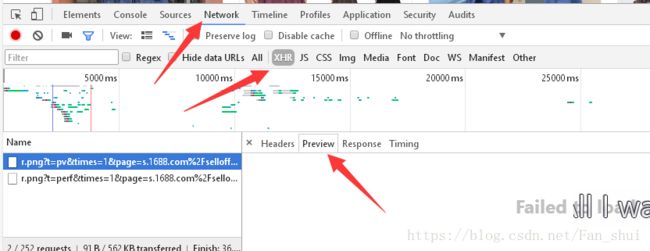
然而事实并不是这样,下滑的时候都能感觉到,静态网页是一次性请求完毕,而这个下滑的时候,明显有新的数据请求,于是再看了一下JS中,果然有数据
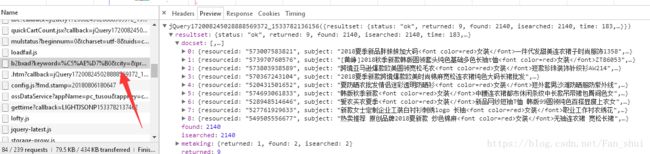
如果只是用单纯的requests.get()是得不到异步请求的数据
2、selenium自动化测试,可见即可爬
from selenium import webdriver
browser=webdriver.Chrome()
def crawle():
url='https://www.1688.com/'
browser.get(url=url)
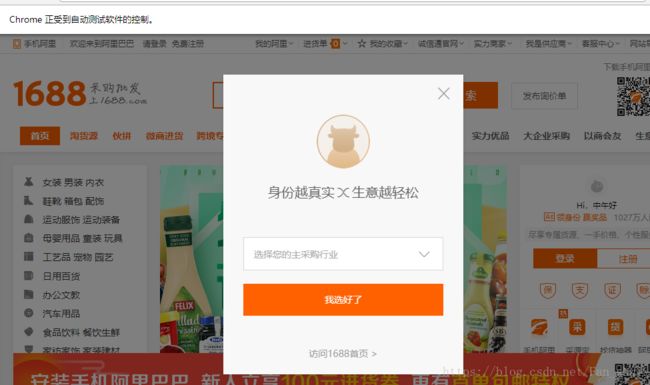
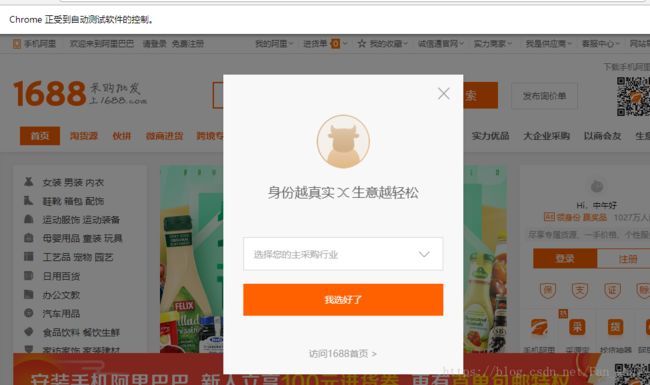
crawle()运行后就产生了上图,这个弹出来的框我们要叉掉,可以选择点击“访问1688首页”。为了定位“访问1688首页”这个元素,右键检查,可查看元素
from selenium import webdriver
browser=webdriver.Chrome()
def crawle():
url='https://www.1688.com/'
browser.get(url=url)
button=browser.find_element_by_class_name('identity-cancel')
button.click()
crawle()可以发现上图的框没见了(selenium中元素的定位很重要,有很多,开篇学习资料selenium中有详细讲解)
接下来需要在搜索框中输入我们想查询的数据,如女装,然后点击搜索。我们需要做的就是
1、定位搜素框
2、向搜素框中传入数据
3、定位搜素按钮,并点击
from selenium import webdriver
browser=webdriver.Chrome()
def crawle():
url='https://www.1688.com/'
browser.get(url=url)
#叉掉首页弹出大框
button=browser.find_element_by_class_name('identity-cancel')
button.click()
#定位搜索框
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys('女装')
#定位搜索按钮
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
crawle()运行后会跳转页面,如下图,新的页面中又有框图,继续叉掉它
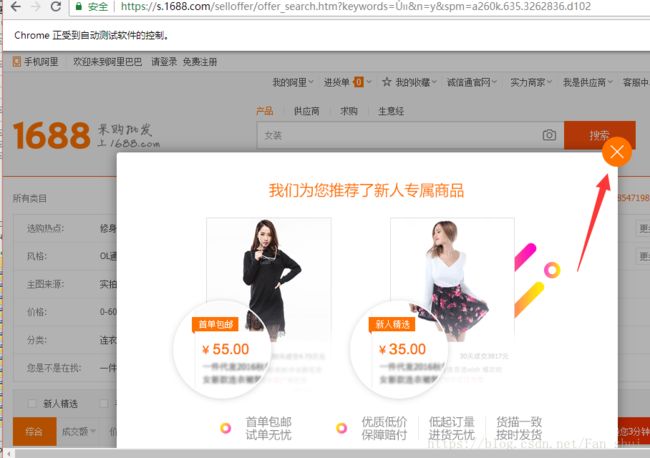
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()接下来我想按照成交量排序,所以定位到成交量,并单击这个元素
#定位成交量
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()第一个函数:
from selenium import webdriver
browser=webdriver.Chrome()
def crawle():
url='https://www.1688.com/'
browser.get(url=url)
#叉掉首页弹出大框
button=browser.find_element_by_class_name('identity-cancel')
button.click()
#定位搜索框
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys('女装')
#定位搜索按钮
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
#叉掉框图
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()
#定位成交量
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()
crawle()3、页面如愿以偿地出来了,接下来就该抓取网页的元素了
在crawl()最后一行调用函数get_products()
接下来就在get_products()里面利用pyquery分析网页,抓取网页元素
可以发现每一个商品信息都在ul下面的li中,我们需要定位到li,然后循环访问每一个li元素。下面主要抓取产品名称title,产品销量deal,产品价格price,产品网址url
from selenium import webdriver
browser=webdriver.Chrome()
def crawle():
url='https://www.1688.com/'
browser.get(url=url)
#叉掉首页弹出大框
button=browser.find_element_by_class_name('identity-cancel')
button.click()
#定位搜索框
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys('女装')
#定位搜索按钮
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
#叉掉框图
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()
#定位成交量
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()
get_products()
from pyquery import PyQuery as pq
from bs4 import BeautifulSoup
def get_products():
html=browser.page_source
doc=pq(html)
items=doc('.sm-offer .fd-clr .sm-offer-item').items()
index=0
for item in items:
index+=1
print('*'*50)
title=item.find('.s-widget-offershopwindowtitle').text().split('\n')
title=' '.join(title)
price_a=item.find('.s-widget-offershopwindowprice').text().split('\n')
price=''.join(price_a[:2])
deal=''.join(price_a[2:])
#产品网址
text=item.find('.s-widget-offershopwindowtitle')
soup=BeautifulSoup(str(text),'lxml')
a=soup.select('.s-widget-offershopwindowtitle a')[0]
url=a['href']
print(title)
print(price)
print(deal)
print(url)
print(' (●ˇ∀ˇ●) '*5)
print('一共%d条数据'%index)
crawle()这个主要就是pyquery的运用
运行后结果如下:
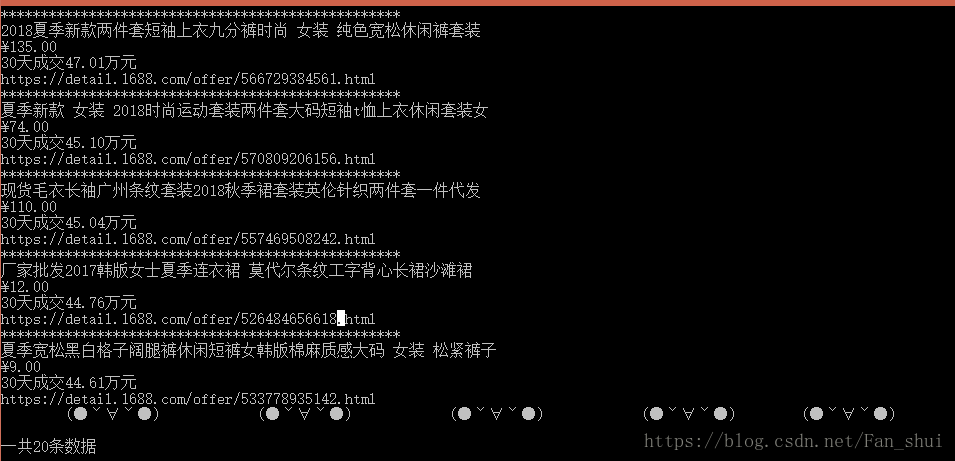
问题来了,明显这个页面中不止20条数据。我们可以自己从首页中搜索女装,再点击成交量,慢慢向下滑动页面,会察觉到有些数据是随着滑动页面产生新的数据。这说明selenium在加载网页时,并没有完全加载完返回。selenium中的显式等待和隐式等待可以解决这个问题。
显式等待:让webdriver等待满足一定条件以后再进一步执行
隐式等待:让webdriver等待一定时间后查找元素
我们选择显式等待,并且希望能够滚动页面到最底部从而使所有数据加载出来。先手动滑到页面的底端,可以发现每个li中有一个id,最后的一个id是offer60,可以发现一共就是60个店铺。
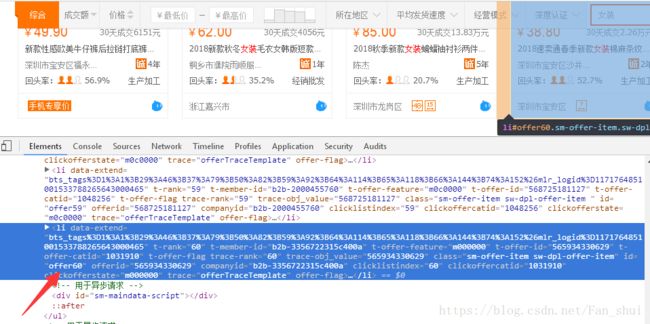
显示等待,wait会等待id为offer60的元素在15s内返回,否则报错
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
browser=webdriver.Chrome()
wait=WebDriverWait(browser,15)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
加载至页面底端:
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')修改后:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
browser=webdriver.Chrome()
wait=WebDriverWait(browser,15)
def crawle():
url='https://www.1688.com/'
browser.get(url=url)
#叉掉首页弹出大框
button=browser.find_element_by_class_name('identity-cancel')
button.click()
#定位搜索框
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys('女装')
#定位搜索按钮
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
#叉掉框图
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()
#定位成交量
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()
try:
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
get_products()
from pyquery import PyQuery as pq
from bs4 import BeautifulSoup
def get_products():
html=browser.page_source
doc=pq(html)
items=doc('.sm-offer .fd-clr .sm-offer-item').items()
index=0
for item in items:
index+=1
print('*'*50)
title=item.find('.s-widget-offershopwindowtitle').text().split('\n')
title=' '.join(title)
price_a=item.find('.s-widget-offershopwindowprice').text().split('\n')
price=''.join(price_a[:2])
deal=''.join(price_a[2:])
#产品网址
text=item.find('.s-widget-offershopwindowtitle')
soup=BeautifulSoup(str(text),'lxml')
a=soup.select('.s-widget-offershopwindowtitle a')[0]
url=a['href']
print(title)
print(price)
print(deal)
print(url)
print(' (●ˇ∀ˇ●) '*5)
print('一共%d条数据'%index)
crawle()运行后:
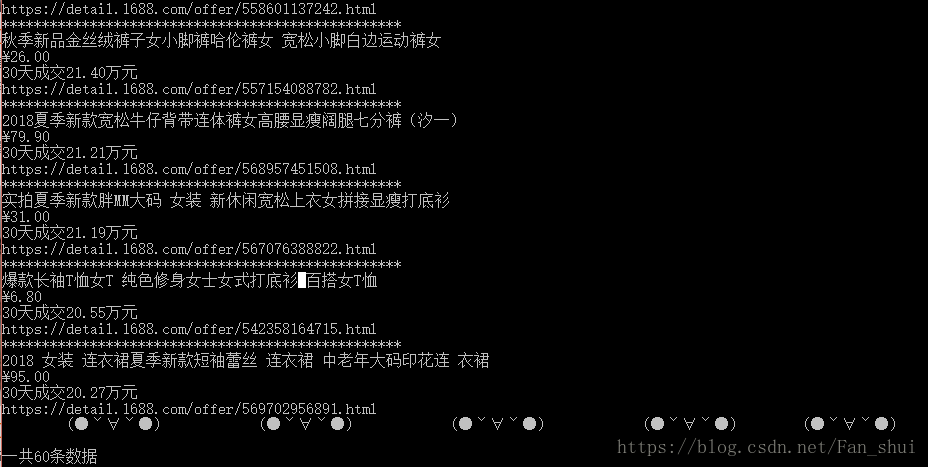
到处为止,我们已经做到了用selenium自动化打开网页,搜索我们想查找的数据,然后根据成交量排序抓取数据。
接下来,还有几点可以改善下:
1、我们想自己在cmd中输入我想查询的类别,比如女装,男装,内衣等
2、我们不止想抓取第一页的数据,想自己定义抓取好多页的数据
3、实现把数据存入到mongodb中
先实现1和2,通过定义main()
def main():
key_words=input('请输入想查询的类别:')
page=int(input('你想查询多少页的数据:'))
for key in key_words:
crawle(key,page)在crawle()中就需要添加参数key和page
def crawle(key,page):
url='https://www.1688.com/'
browser.get(url=url)
button=browser.find_element_by_class_name('identity-cancel')
button.click()
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys(key)
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()
try:
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)
if page>1:
for page in range(2,page+1):
get_more_page(key,page)当page>1时,我们执行get_more_page(),这个函数会在下图框中输入对应页数,然后跳转,并调用get_products()抓取数据
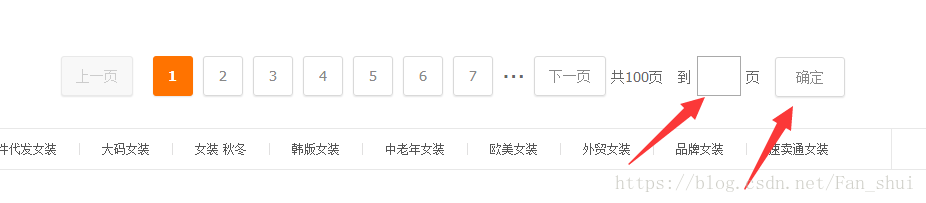
def get_more_page(key,page):
page_input=browser.find_element_by_class_name('fui-paging-input')
page_input.clear()
page_input.send_keys(page)
button=browser.find_element_by_class_name('fui-paging-btn')
button.click()
try:
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)需要注意的是,我们在最后两行实现了get_products()和save_to_mongo(), get_products()要想实现这个循环需要在get_products()中添加yield 请求
yield{
'title':title,
'deal':deal,
'price':price,
'url':url}现在,实先存储到mongodb中,用save_to_mongo()
import pymongo
client=pymongo.MongoClient()
db=client.alibaba
def save_to_mongo(item,key):
#根据关键字动态存入相应的表
collection=db[key]
if item:
collection.insert(item)
print('成功存储到mongo')这个item也就是get_products()里面的yield产生的数据
整体代码:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from pyquery import PyQuery as pq
from bs4 import BeautifulSoup
browser=webdriver.Chrome()
wait=WebDriverWait(browser,15)
def crawle(key,page):
url='https://www.1688.com/'
browser.get(url=url)
button=browser.find_element_by_class_name('identity-cancel')
button.click()
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys(key)
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()
try:
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)
if page>1:
for page in range(2,page+1):
get_more_page(key,page)
def get_more_page(key,page):
page_input=browser.find_element_by_class_name('fui-paging-input')
page_input.clear()
page_input.send_keys(page)
button=browser.find_element_by_class_name('fui-paging-btn')
button.click()
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
try:
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)
def get_products():
html=browser.page_source
doc=pq(html)
items=doc('.sm-offer .fd-clr .sm-offer-item').items()
index=0
for item in items:
index+=1
print('*'*50)
title=item.find('.s-widget-offershopwindowtitle').text().split('\n')
title=' '.join(title)
price_a=item.find('.s-widget-offershopwindowprice').text().split('\n')
price=''.join(price_a[:2])
deal=''.join(price_a[2:])
#产品网址
text=item.find('.s-widget-offershopwindowtitle')
soup=BeautifulSoup(str(text),'lxml')
a=soup.select('.s-widget-offershopwindowtitle a')[0]
url=a['href']
print(title)
print(price)
print(deal)
print(url)
yield{
'title':title,
'deal':deal,
'price':price,
'url':url}
print(' (●ˇ∀ˇ●) '*5)
print('一共%d条数据'%index)
import pymongo
client=pymongo.MongoClient()
db=client.alibaba
def save_to_mongo(item,key):
#根据关键字动态存入相应的表
collection=db[key]
if item:
collection.insert(item)
print('成功存储到mongo')
def main():
key_words=input('请输入想查询的类别:').split(' ')
page=int(input('你想查询多少页的数据:'))
for key in key_words:
crawle(key,page)
main()最后运行就可以看到数据库中的数据如图

咋看之下感觉没有什么问题,但是如果我们试着把数据的页数改为两页,仔细观察控制台输出的信息就会发现两次打印出的数据都是一样的,都是第一页网页的信息,这样肯定不行
解决办法:要想解决问题,首先得知道问题出在哪里,各位小伙伴要是自己有兴趣,可以尝试着去解决,下面我写出我的建议,调试代码,观察代码运行时,chrome浏览器确实是跳转到了第二页,看我们的get_more_page()函数,里面有一个execute_script(),它会将网页滚动到最低
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)') 然而我们可以发现chrome浏览器在跳转到第二页的时候并没有将网页滑动到最底端,但是又没有报错,这说明上面这段代码执行了的,但是第二页确实没有自动滑动底端,输出的数据也确实是第一页的,所以很有可能是浏览器响应的速度比代码运行的速度快
什么意思呢?我们的get_more_page()是为了跳转到其它页面,在执行
button=browser.find_element_by_class_name('fui-paging-btn')
button.click()时候,浏览器确实跳转到了指定的页面,但是browser没有及时的响应到新的页面,还停留在上一个页面,这个时候执行execute_script(),执行get_products()都是在对上一个网页进行操作,所以我们打印出来的也是上一个页面的数据,我们只需要让程序缓几秒,它便能够缓过来,加入time.sleep(3)
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from pyquery import PyQuery as pq
from bs4 import BeautifulSoup
import time
browser=webdriver.Chrome()
wait=WebDriverWait(browser,15)
def crawle(key,page):
url='https://www.1688.com/'
browser.get(url=url)
button=browser.find_element_by_class_name('identity-cancel')
button.click()
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys(key)
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()
try:
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)
if page>1:
for page in range(2,page+1):
get_more_page(key,page)
def get_more_page(key,page):
page_input=browser.find_element_by_class_name('fui-paging-input')
page_input.clear()
page_input.send_keys(page)
button=browser.find_element_by_class_name('fui-paging-btn')
button.click()
time.sleep(3)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
try:
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)
def get_products():
html=browser.page_source
doc=pq(html)
items=doc('.sm-offer .fd-clr .sm-offer-item').items()
index=0
for item in items:
index+=1
print('*'*50)
title=item.find('.s-widget-offershopwindowtitle').text().split('\n')
title=' '.join(title)
price_a=item.find('.s-widget-offershopwindowprice').text().split('\n')
price=''.join(price_a[:2])
deal=''.join(price_a[2:])
#产品网址
text=item.find('.s-widget-offershopwindowtitle')
soup=BeautifulSoup(str(text),'lxml')
a=soup.select('.s-widget-offershopwindowtitle a')[0]
url=a['href']
print(title)
print(price)
print(deal)
print(url)
yield{
'title':title,
'deal':deal,
'price':price,
'url':url}
print(' (●ˇ∀ˇ●) '*5)
print('一共%d条数据'%index)
import pymongo
client=pymongo.MongoClient()
db=client.alibaba
def save_to_mongo(item,key):
#根据关键字动态存入相应的表
collection=db[key]
if item:
collection.insert(item)
print('成功存储到mongo')
def main():
key_words=input('请输入想查询的类别:').split(' ')
page=int(input('你想查询多少页的数据:'))
for key in key_words:
crawle(key,page)
main()这个时候再运行发现输出时不再是重复的内容。
然后,还是没有结束,我们的main()执行时,key_words是个列表,用空格隔开,但是我们再输入一种以上的类别时,便报错了
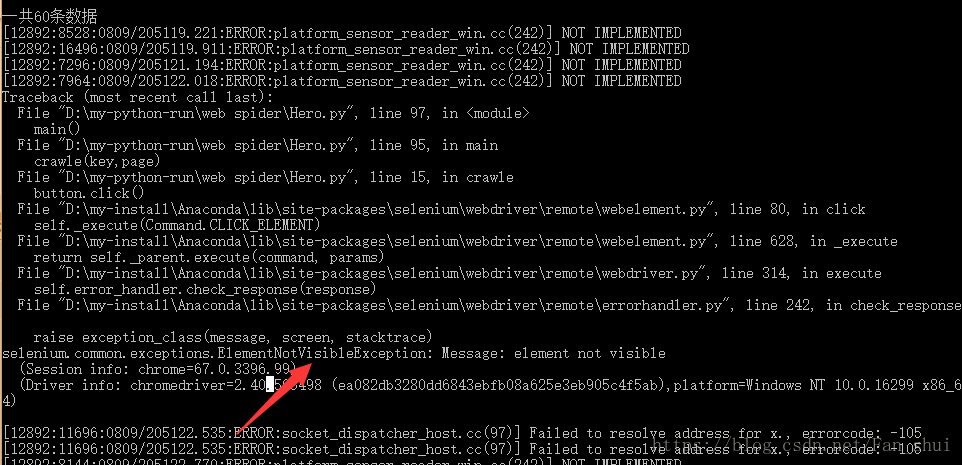
显示找不到元素,哪个元素呢?通过错误提示可以看出是找不到下图中的“访问1688首页”这个元素,chrome在运行的时候,我们可以观察到只有第一次搜索的时候才会出现下图,以后不会出现,我们只需在执行的时候加入try…except
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from pyquery import PyQuery as pq
from bs4 import BeautifulSoup
import time
browser=webdriver.Chrome()
wait=WebDriverWait(browser,15)
def crawle(key,page):
url='https://www.1688.com/'
browser.get(url=url)
try:
button=browser.find_element_by_class_name('identity-cancel')
button.click()
except:
pass
input=browser.find_element_by_id('alisearch-keywords')
input.send_keys(key)
sea_button=browser.find_element_by_id('alisearch-submit')
sea_button.click()
try:
button_1=browser.find_element_by_class_name('s-overlay-close-l')
button_1.click()
except:
pass
button_deal=browser.find_elements_by_css_selector('.sm-widget-sort.fd-clr.s-widget-sortfilt li')[1]
button_deal.click()
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
try:
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)
if page>1:
for page in range(2,page+1):
get_more_page(key,page)
def get_more_page(key,page):
page_input=browser.find_element_by_class_name('fui-paging-input')
page_input.clear()
page_input.send_keys(page)
button=browser.find_element_by_class_name('fui-paging-btn')
button.click()
time.sleep(3)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
try:
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#offer60')))
except :
print('*'*30,'超时加载','*'*30,'\n\n\n')
for item in get_products():
save_to_mongo(item,key)
def get_products():
html=browser.page_source
doc=pq(html)
items=doc('.sm-offer .fd-clr .sm-offer-item').items()
index=0
for item in items:
index+=1
print('*'*50)
title=item.find('.s-widget-offershopwindowtitle').text().split('\n')
title=' '.join(title)
price_a=item.find('.s-widget-offershopwindowprice').text().split('\n')
price=''.join(price_a[:2])
deal=''.join(price_a[2:])
#产品网址
text=item.find('.s-widget-offershopwindowtitle')
soup=BeautifulSoup(str(text),'lxml')
a=soup.select('.s-widget-offershopwindowtitle a')[0]
url=a['href']
print(title)
print(price)
print(deal)
print(url)
yield{
'title':title,
'deal':deal,
'price':price,
'url':url}
print(' (●ˇ∀ˇ●) '*5)
print('一共%d条数据'%index)
import pymongo
client=pymongo.MongoClient()
db=client.alibaba
def save_to_mongo(item,key):
#根据关键字动态存入相应的表
collection=db[key]
if item:
collection.insert(item)
print('成功存储到mongo')
def main():
key_words=input('请输入想查询的类别(ps:):').split(' ')
page=int(input('你想查询多少页的数据:'))
for key in key_words:
time.sleep(3)
crawle(key,page)
main()