大数据应用的多层次概率数据结构设计和实现
以下内容为个人写报告用来整理思路,不是篇完成的博文,谢谢!
摘要
在某些特定的应用场景下,由于Count-Min Sketch的统计特性,造成的数据误差会比较大,针对这一问题,我们采用array of Count-Min Sketches来进行实验提高效率与数据的精度。本课题主要面向大数据集应用,研究基于概率数据结构上这些融合的计算精度、性能,上下界数学表达,课题将面向大数据集在不同的应用场景下,设计实现合理的Count-Min Sketch 或array of Count-Min Sketches,以理论分析和实验检验方案的合理性,具有理论研究价值和应用前景。
本课题主要研究基于概率数据结构,针对不同的应用场景来合理的设计array of Count-MinSketches,在提高大数据应用的性能问题的同时提高Count-Min Sketch的精度问题。
立项依据
互联网时代,一些原理简单,但使用广泛的应用,面对大数据时,性能成为一个极大挑战。像网站统计独立访客(unique visitor),用户对网站的访问量,销量排名靠前的商品或店铺,一定销量范围的某商品,商品是否已上架等查询,可以抽象为对应的大数据计算----**基数(势)估计(Cardinality Estimation)**、**频度估计(Frequency Estimation)**、**Top-k 元素计算(Heavy Hitters)**、**Range Query**,**Membership Query**。这类大数据计算,在某些应用场景下,没必要要求百分百精确,可以基于概率数据结构进行设计和实现,获取时空性能的提升。本课题主要研究基于概率数据结构,针对不同的应用场景来合理的设计**array of Count-Min Sketches**,在提高大数据应用的性能问题的同时提高Count-Min Sketch的精度问题。
使用概率数据结构处理大数据的算法一些应用,算法和数据结构都比较确定,但针对一些特定的应用,使用单一的概率数据结构处理大数据在带来性能提升的同时会带来较大的精度损失,在面对这些特定的应用场景时,如何更好地进行性能与精度的平衡,都面临一些挑战,使用多层次的概率数据结构可以在提高大数据应用性能问题的同时进一步提高单一概率数据结构的精度问题。本课题主要面向大数据集的不同应用场景,基于概率数据结构或多层次概率数据结构设计相应的算法。例如基于签到数据的常见应用,比如兴趣区域统计、位置推荐等,均可以通过上述基本大数据应用实现。
研究内容
面向签到数据Heavy Hitters查询的Count-Min Sketch设计与实现
面向签到数据的Range Query的array of Count-Min Sketches设计与实现
面向签到数据的Frequency Estimation的array of Count-Min Sketches设计与实现。
研究目标
面向签到大数据查询的不同应用下的高时空效率概率数据结构以及层次概率数据结构的设计和实现,是实验证明可行的。
面向签到大数据的概率数据结构以及多层次概率数据结构的时空分析,是理论证明高效的。
针对不同的应用场景设计合理的概率数据结构保证处理签到数据集时精度和性能的平衡性。
拟解决的关键科学问题:
针对不同的应用场景设计合理的Count-Min Sketch和array of Count-Min Sketches结构保证精度和性能的平衡性,及其应用在签到大数据上的适用性问题。
研究过程记录
2017/12/9 基数估计
一、基数估计Cardinality Estimation
解读Cardinality Estimation算法(第一部分:基本概念)
基数的定义
简单来说,基数(cardinality,也译作势),是指一个集合(这里的集合允许存在重复元素,与集合论对集合严格的定义略有不同,如不做特殊说明,本文中提到的集合均允许存在重复元素)中不同元素的个数。
传统的基数计数实现
1. 基于B树的基数计数
2. 基于bitmap的基数计数
为了克服B树不能高效合并的问题,一种替代方案是使用bitmap表示集合。也就是使用一个很长的bit数组表示集合,将bit位顺序编号,bit为1表示此编号在集合中,为0表示不在集合中。例如“00100110”表示集合 {2,5,6}。bitmap中1的数量就是这个集合的基数。
显然,与B树不同bitmap可以高效的进行合并,只需进行按位或(or)运算就可以,而位运算在计算机中的运算效率是很高的。但是bitmap方式也有自己的问题,就是内存使用问题。
很容易发现,bitmap的长度与集合中元素个数无关,而是与基数的上限有关。例如在上面的例子中,假如要计算上限为1亿的基数,则需要12.5M字节的bitmap,十个链接就需要125M。关键在于,这个内存使用与集合元素数量无关,即使一个链接仅仅有一个1UV,也要为其分配12.5M字节。
由此可见,虽然bitmap方式易于合并,却由于内存使用问题而无法广泛用于大数据场景。
解读Cardinality Estimation算法(第二部分:Linear Counting)
最大似然估计,就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
LC算法事实上是哈希函数加上bitmap的综合。
。LC算法虽然由于空间复杂度不够理想已经很少被单独使用,但是由于其在元素数量较少时表现非常优秀,因此常被用于弥补LogLog Counting在元素较少时误差较大的缺陷,实际上LC及其思想是组成HyperLogLog Counting和Adaptive Counting的一部分。
Linear Counting算法相较于直接映射bitmap的方法能大大节省内存(大约只需后者1/10的内存),但毕竟只是一个常系数级的降低,空间复杂度仍然为O(Nmax)O(Nmax)。
解读Cardinality Estimation算法(第三部分:LogLog Counting)
LogLog Counting却只有O(log2(log2(Nmax)))O(log2(log2(Nmax)))。例如,假设基数的上限为1亿,原始bitmap方法需要12.5M内存,而LogLog Counting只需不到1K内存(640字节)就可以在标准误差不超过4%的精度下对基数进行估计,效果可谓十分惊人。
基本算法
均匀随机化
与LC一样,在使用LLC之前需要选取一个哈希函数H应用于所有元素,然后对哈希值进行基数估计。H必须满足如下条件(定性的):1、H的结果具有很好的均匀性,也就是说无论原始集合元素的值分布如何,其哈希结果的值几乎服从均匀分布(完全服从均匀分布是不可能的,D. Knuth已经证明不可能通过一个哈希函数将一组不服从均匀分布的数据映射为绝对均匀分布,但是很多哈希函数可以生成几乎服从均匀分布的结果,这里我们忽略这种理论上的差异,认为哈希结果就是服从均匀分布)。
2、H的碰撞几乎可以忽略不计。也就是说我们认为对于不同的原始值,其哈希结果相同的概率非常小以至于可以忽略不计。
3、H的哈希结果是固定长度的。
以上对哈希函数的要求是随机化和后续概率分析的基础。后面的分析均认为是针对哈希后的均匀分布数据进行。
分桶平均
上述分析给出了LLC的基本思想,不过如果直接使用上面的单一估计量进行基数估计会由于偶然性而存在较大误差。因此,LLC采用了分桶平均的思想来消减误差。具体来说,就是将哈希空间平均分成m份,每份称之为一个桶(bucket)。对于每一个元素,其哈希值的前k比特作为桶编号,其中2k=m2k=m,而后L-k个比特作为真正用于基数估计的比特串。桶编号相同的元素被分配到同一个桶,在进行基数估计时,首先计算每个桶内元素最大的第一个“1”的位置,设为M[i],然后对这m个值取平均后再进行估计,即:
n^=21m∑M[i]n^=21m∑M[i]
这相当于物理试验中经常使用的多次试验取平均的做法,可以有效消减因偶然性带来的误差。下面举一个例子说明分桶平均怎么做。
假设H的哈希长度为16bit,分桶数m定为32。设一个元素哈希值的比特串为“0001001010001010”,由于m为32,因此前5个bit为桶编号,所以这个元素应该归入“00010”即2号桶(桶编号从0开始,最大编号为m-1),而剩下部分是“01010001010”且显然ρ(01010001010)=2ρ(01010001010)=2,所以桶编号为“00010”的元素最大的ρρ即为M[2]的值。
算法应用
误差控制在应用LLC时,主要需要考虑的是分桶数m,而这个m主要取决于误差。根据上面的误差分析,如果要将误差控制在ϵϵ之内,则:
m>(1.30ϵ)2
内存使用分析
内存使用与m的大小及哈希值得长度(或说基数上限)有关。假设H的值为32bit,由于ρmax≤32ρmax≤32,因此每个桶需要5bit空间存储这个桶的ρmaxρmax,m个桶就是5×m/85×m/8字节。例如基数上限为一亿(约227227),当分桶数m为1024时,每个桶的基数上限约为227/210=217227/210=217,而log2(log2(217))=4.09log2(log2(217))=4.09,因此每个桶需要5bit,需要字节数就是5×1024/8=6405×1024/8=640,误差为1.30/1024−−−−√=0.0406251.30/1024=0.040625,也就是约为4%。
合并
与LC不同,LLC的合并是以桶为单位而不是bit为单位,由于LLC只需记录桶的ρmaxρmax,因此合并时取相同桶编号数值最大者为合并后此桶的数值即可。
本文主要介绍了LogLog Counting算法,相比LC其最大的优势就是内存使用极少。不过LLC也有自己的问题,就是当n不是特别大时,其估计误差过大,因此目前实际使用的基数估计算法都是基于LLC改进的算法,这些改进算法通过一定手段抑制原始LLC在n较小时偏差过大的问题。
总结:
首先对集合里的所有的element进行hash,假设hash函数服从均匀分布。
这种方案实践起来偶然因素影响太大,在小概率的情况下,带来较大的误差。所以要采取分桶平均的方法来平均误差。
class LogLogCounter {
int H // H is a design parameter, hash value的bit长度
int m = 2^k // k is a design parameter, 划分的bucket数
etype[] estimators = new etype[m] // etype is a design parameter, 预估值的类型(ex,byte), 不同rank函数的实现可以返回不同的类型
void add(value) {
hashedValue = hash(value) //产生H bits的hash value
bucket = getBits(hashedValue, 0, k) //将前k bits作为桶号
estimators[bucket] = max( //对每个bucket只保留最大的预估值
estimators[bucket],
rank( getBits(hashedValue, k, H) ) //用k到H bits来预估Cardinality
)
}
getBits(value, int start, int end) //取出从start到end的bits段
rank(value) //取出ρ(value)
}2017/12/10
**解读Cardinality Estimation算法(第四部分:HyperLogLog Counting及Adaptive Counting)**
**Adaptive Counting**
Adaptive Counting(简称AC)在“Fast and accurate traffic matrix measurement using adaptive cardinality counting”一文中被提出。其思想也非常简单直观:实际上AC只是简单将LC和LLC组合使用,根据基数量级决定是使用LC还是LLC。具体是通过分析两者的标准差,给出一个阈值,根据阈值选择使用哪种估计。
完整的AC算法如下:
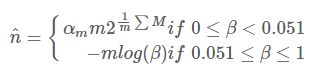
误差分析
因为AC只是LC和LLC的简单组合,所以误差分析可以依照LC和LLC进行。值得注意的是,当β<0.051β<0.051时,LLC最大的偏差不超过0.17%,因此可以近似认为是无偏的。
**HyperLogLog Counting**
基本算法
HLLC的第一个改进是使用调和平均数替代几何平均数。注意LLC是对各个桶取算数平均数,而算数平均数最终被应用到2的指数上,所以总体来看LLC取得是几何平均数。由于几何平均数对于离群值(例如这里的0)特别敏感,因此当存在离群值时,LLC的偏差就会很大,这也从另一个角度解释了为什么n不太大时LLC的效果不太好。这是因为n较小时,可能存在较多空桶,而这些特殊的离群值强烈干扰了几何平均数的稳定性。
偏差分析
根据论文中的分析结论,与LLC一样HLLC是渐近无偏估计,且其渐近标准差为:
SEhllc(n^/n)=1.04/m−−√SEhllc(n^/n)=1.04/m
因此在存储空间相同的情况下,HLLC比LLC具有更高的精度。例如,对于分桶数m为2^13(8k字节)时,LLC的标准误差为1.4%,而HLLC为1.1%。
分段偏差修正
在HLLC的论文中,作者在实现建议部分还给出了在n相对于m较小或较大时的偏差修正方案。具体来说,设E为估计值:
当E≤52mE≤52m时,使用LC进行估计。
当52m130232E>130232时,估计公式如为n^=−232log(1−E/232)n^=−232log(1−E/232)。
二、频率估计 Frequency Estimation
估计某个element的出现次数
正常的做法就是使用sorted table或者hash table, 问题当然就是空间效率
所以我们需要在牺牲一定的准确性的情况下, 优化空间效率
2.1 Frequency Estimation: Count-Min Sketch
这个方法比较简单, 原理就是, 使用二维的hash table, w是hash table的取值空间, d是hash函数的个数 对某个element, 分别使用d个hash函数计算相应的hash值, 并在对应的bucket上递增1, 每个bucket的值称为sketch, 如图

然后在查询某个element的frequency时, 只需要取出所有d个sketch, 然后取最小的那个作为预估值, 如其名
因为为了节省空间, w*d是远小于真正的element个数的, 所以必然会出现很多的冲突, 而最小的那个应该是冲突最少的, 最精确的那个
这个方法的思路和bloom filter比较类似, 都是通过多个hash来降低冲突带来的影响
伪代码如下:
#include void add(long value)
{
for(int i=0;ivalue,i)]++;//简单的对每个nucket经行叠加
}
}
long estimateFrequency(value)
{
long minmum=MAX_VALUE;
for(int i=0;ivalue,i)]);//取最小值估计
}
return minmum;
}
hash(value,i)
{
return ((a[i]*value+b[i])mod p)mod w;//hash函数,a,b参数会变化
}
}; 优点, 简单, 空间效率显著优化
缺点, 对于大量重复的element或top的element比较准确, 但对于较少出现的element准确度比较差
实验, 对于Count-Min sketch of size 3×64, i.e. 192 counters total
Dataset1, 10k elements, about 8500 distinct values, 较少重复的数据集, 测试结果准确度很差
Dataset2, 80k elements, about 8500 distinct values, 大量重复的数据集, 测试结果准确度比较高
2.2 Frequency Estimation: Count-Mean-Min Sketch
原理也比较简单, 预估sketch上可能产生的noise
怎么预估? 很简单, 比如1000数hash到20个bucket里面, 那么在均匀分布的条件下, 一个bucket会被分配50个数 那么这里就把每个sketchCounter里面的noise减去 最终是取所有sketch的median(中位数), 而不是min
class CountMeanMinSketch {
// initialization and addition procedures as in CountMinSketch
// n is total number of added elements
long estimateFrequency(value) {
long e[] = new long[d]
for(i = 0; i < d; i++) {
sketchCounter = estimators[i][ hash(value, i) ]
noiseEstimation = (n - sketchCounter) / (w - 1)
e[i] = sketchCounter – noiseEstimator
}
return median(e)
}
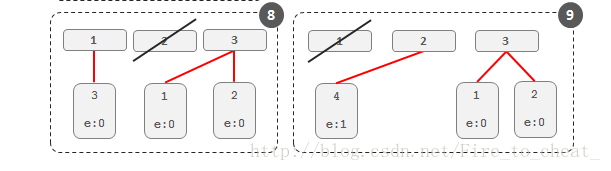
}3.2 Heavy Hitters: Stream-Summary
另外一种获取top的思路,
维护一组固定个数的slots, 比如你要求Top-10, 那么维护10个slots
当elements过来, 如果slots里面有, 就递增, 没有就替换solts中frequency最小的那个
这个算法没有讲清楚, 给的例子也太简单, 不太能理解e(maximum potential error)干吗用的, 为什么4替换3后, 3的frequency作为4的maximum potential error
我的理解是, 因为3的frequency本身就是最小的, 所以4继承3的frequency不会影响实际的排名,
这样避免3,4交替出现所带来的计数问题, 但这里的frequency就不是精确的, 3的frequency被记入4是potential error
The figure below illustrates how Stream-Summary with 3 slots works for the input stream {1,2,2,2,3,1,1,4}.
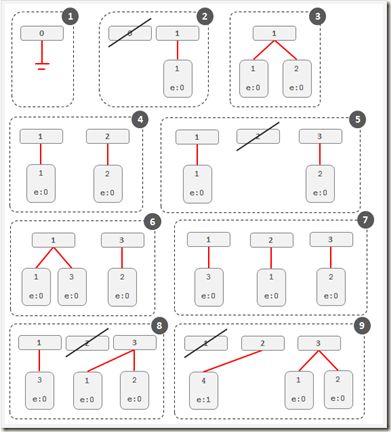
一下部分没看懂:

(讲得不够清晰,没讲清楚3是怎么被4取代的,也没说因子e是什么作用)