面试问题汇总
1.jdk1.6,jdk1.7,jdk1.8的区别
1.1 JDK1.7多语言支持
这里的多语言不是指中文英文之类的语言,而是说Java7的虚拟机对多种动态程序语言增加了支持,比如:Rubby、 Python等等。对这些动态语言的支持极大地扩展了Java虚拟机的能力。
Java7通过多种特性来增强开发效率。
提供了新的垃圾回收机制(G1)来降低垃圾回收的负载和增强垃圾回收的效果。
1.2 可以catch多个异常
try {
testthrows();
} catch (IOException | SQLException ex) {
throw ex;
}
1.3 数字类型的下划线表示 更友好的表示方式
long creditCardNumber = 1234_5678_9012_3456L;
long socialSecurityNumber = 999_99_9999L;
float pi = 3.14_15F;
long hexBytes = 0xFF_EC_DE_5E;
long hexWords = 0xCAFE_BABE;
long maxLong = 0x7fff_ffff_ffff_ffffL;
byte nybbles = 0b0010_0101;
long bytes = 0b11010010_01101001_10010100_10010010;
1.4 Switch语句支持string类型
2.springmvc的requestBoby和responseBoby的作用
@ResponseBody是作用在方法上的,表示该方法的返回结果直接写入 HTTP response body 中
@RequestBody是作用在形参列表上,用于将前台发送过来固定格式的数据【xml 格式或者 json等】封装为对应的 JavaBean 对象
@RequestMapping("/login.do")
@ResponseBody public Object login(@RequestBody User loginUser, HttpSession session) {
user = userService.checkLogin(loginUser);
session.setAttribute("user", user);
return new JsonResult(user);
}
3.Linux的766是什么
linux目录权限分成三部分: 777的权限是:rwxrwxrwx 其中r代表可读,w代表可写,x代码可执行。 第一个rwx表示文件拥有者的权限是可读可写可执行,第二个rwx表示和拥有者一个组的用户的权限也是可读可写可执行,第三个rwx表示其他和拥有者没有关系的用户的权限也是可读可写可执行。
766的权限是:rwxrw-rw- 可以看出除了拥有者同组或者其他用户都是没有执行权限的。而在读写的时候都必须要执行权限才能读才能写。
4. js闭包
有权访问另一个函数作用域内变量的函数都是闭包。这里 inc 函数访问了构造函数 a 里面的变量 n,所以形成了一个闭包。
function a(){
var n = 0;
function inc() {
n++;
console.log(n);
}
inc();
inc();
}
a(); //控制台输出1,再输出2
总结:闭包就是一个函数引用另外一个函数的变量,因为变量被引用着所以不会被回收,因此可以用来封装一个私有变量。
5. JDBC的sql注入问题
SQL注入是利用某些系统没有对用户输入数据进行充分的验证的情况下,用户输入了恶意的SQL命令,导致数据库完成了错误的命令,或者导致数据库崩溃的方法。
如果这里传进来的是 String name = "'1' or '1'='1'";
拼接出来的SQL语句中where语句后面的条件是(select * from ATable where name='1' or '1'='1')永远都是成立。这会使Statement出现不可预料的结果。
为了解决这个问题。我们可以使用PrepareStatement。对上面没有验证的语句进行验证。
PreparedStatement继承了Statement,没有了SQL注入的问题。preparedStatement进行了预编译。
如果使用预编译语句.传入的任何内容就不会和原来的语句发生任何匹配的关系.
只要使用预编译语句,你就用不着对传入的数据做任何过虑.
而如果使用普通的statement,就要对drop等做费尽心机的判断和过虑.
如上面的程序:state = conn.prepareStatement(sql);
第一种采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setString方法传值即可:
第二种是采用正则表达式将包含有 单引号('),分号(;) 和 注释符号(--)的语句给替换掉来防止SQL注入
6.Thread类和Runable接口
实际开发中一个多线程的操作很少使用Thread类,而是通过Runnable接口完成。
但是在使用Runnable定义的子类中没有start()方法,只有Thread类中才有。此时观察Thread类,有一个构造方法:public Thread(Runnabletarger)此构造方法接受Runnable的子类实例,也就是说可以通过Thread类来启动Runnable实现的多线程。(start()可以协调系统的资源)
Thread类是Runnable接口的子类。
7. Lru算法
Lru算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
实现:
1.新数据插入到链表头部;
2.每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3.当链表满的时候,将链表尾部的数据丢弃。
8. java常用排序算法
选择排序,插入排序,冒泡排序,希尔算法,快速排序(能手写一两个)
9 手写单例模式,哪个模式属于线程安全
特点:
1、单例类只能有一个实例。
2、单例类必须自己创建自己的唯一实例。
3、单例类必须给所有其他对象提供这一实例。
饿汉式是线程安全的,可以直接用于多线程而不会出现问题。
饿汉式和懒汉式区别:
饿汉就是在类初始化时,就把单例初始化完成,保证getInstance的时候,单例是已经存在的了。
而懒汉比较懒,只有当调用getInstance的时候,才回去初始化这个单例。
public class Singleton1 {
private Singleton1() {} //构造方法私有,防止他人初始化实例
//类加载的时候就进行自我初始化实例
private static final Singleton1 single = new Singleton1();
//静态工厂方法
public static Singleton1 getInstance() {
return single;
}
}
//懒汉式单例类.在类被调用的时候,进行初始化,需要注意,加上锁,因为多线程环境下会引发问题
public class Singletion1{
private Singletion1(){};
private Singletion1 s = null;
public sysncohized static Singletion1 getInit(){
if(s==null){
s= new Singletion1();
}
return s;
}
}
什么是线程安全?
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。简单来说,符合预期的就是安全的
10. Nginx
客户端本来可以直接通过HTTP协议访问某网站应用服务器,网站管理员可以在中间加上一个Nginx,客户端请求Nginx,Nginx请求应用服务器,然后将结果返回给客户端,此时Nginx就是反向代理服务器。
当网站访问量非常大,网站站长开心赚钱的同时,也摊上事儿了。因为网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。同时带来的好处是,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
11.设计模式
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
12.Redis多线程的安全
优点:性能和支持多种数据结构,单个value的最大限制是1GB
redis是一种单线程机制的nosql数据库,基于key-value,数据可持久化落盘。由于单线程所以redis本身并没有锁的概念,多个客户端连接并不存在竞争关系,但是利用jedis等客户端对redis进行并发访问时会出现问题。发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。
同时,单线程的天性决定,高并发对同一个键的操作会排队处理,如果并发量很大,可能造成后来的请求超时。
在远程访问redis的时候,因为网络等原因造成高并发访问延迟返回的问题。
从redis获取值N,对数值N进行边界检查,自加1,然后N写回redis中。 这种应用场景很常见,像秒杀,全局递增ID、IP访问限制等。以IP访问限制来说,恶意攻击者可能发起无限次访问,并发量比较大,分布式环境下对N的边界检查就不可靠,因为从redis读的N可能已经是脏数据。传统的加锁的做法(如java的synchronized和Lock)也没用,因为这是分布式环境,这个同步问题的救火队员也束手无策。在这危急存亡之秋,分布式锁终于有用武之地了。
分布式锁可以基于很多种方式实现,比如zookeeper、redis...。不管哪种方式,他的基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
这里主要讲如何用redis实现分布式锁。
synchronized 乐观锁,悲观锁
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
1. 版本号机制
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,如果提交的数据时,版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
举一个简单的例子:
假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 50(50(100-$50 )。
在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 20(20(100-$20 )。
操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
13.网络安全
非对称加密,HTTPS,签名
14.springboot和springMVC的异同点
15.加密
对称加密和非对称加密介绍和区别
什么是对称加密技术?
对称加密采用了对称密码编码技术,它的特点是文件加密和解密使用相同的密钥加密,也就是密钥也可以用作解密密钥
对称加密算法在电子商务交易过程中存在几个问题:
1、要求提供一条安全的渠道使通讯双方在首次通讯时协商一个共同的密钥。直接的面对面协商可能是不现实而且难于实施的,所以双方可能需要借助于邮件和电话等其它相对不够安全的手段来进行协商;
2、密钥的数目难于管理。因为对于每一个合作者都需要使用不同的密钥,很难适应开放社会中大量的信息交流;
3、对称加密算法一般不能提供信息完整性的鉴别。它无法验证发送者和接受者的身份;
4、对称密钥的管理和分发工作是一件具有潜在危险的和烦琐的过程。对称加密是基于共同保守秘密来实现的,采用对称加密技术的贸易双方必须保证采用的是相同的密钥,保证彼此密钥的交换是安全可靠的,同时还要设定防止密钥泄密和更改密钥的程序。
假设两个用户需要使用对称加密方法加密然后交换数据,则用户最少需要2个密钥并交换使用,如果企业内用户有n个,则整个企业共需要n×(n-1) 个密钥,密钥的生成和分发将成为企业信息部门的恶梦。
常见的对称加密算法有DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES
什么是非对称加密技术?
与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey)。
公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
非对称加密算法实现机密信息交换的基本过程是:甲方生成一对密钥并将其中的一把作为公用密钥向其它方公开;得到该公用密钥的乙方使用该密钥对机密信息进行加密后再发送给甲方;甲方再用自己保存的另一把专用密钥对加密后的信息进行解密。甲方只能用其专用密钥解密由其公用密钥加密后的任何信息。
Hash算法(摘要算法)
Hash算法特别的地方在于它是一种单向算法,用户可以通过hash算法对目标信息生成一段特定长度的唯一hash值,却不能通过这个hash值重新获得目标信息。因此Hash算法常用在不可还原的密码存储、信息完整性校验等。
先理解 公/私 钥(yue)的意思:
私钥,即 私人 的钥匙,是唯一的,所以可以用来证明来源是特定的人
公钥,即 公用 的钥匙,我可以将它给很多人(公众)。所以既然那么多人都知道,所以公钥并不能证明来源一定是特定的人
在理解 加密、签名 的作用:
加密:用于防止信息外泄(泄露给不相关的人)
签名:用于确认身份(可以类比下信用卡上的签名)
非对称加解密,私钥和公钥到底是谁来加密,谁来解密
第一种用法:公钥加密,私钥解密。---用于加解密
第二种用法:私钥签名,公钥验签。---用于签名
有点混乱,不要去硬记,总结一下:
你只要想:
既然是加密,那肯定是不希望别人知道我的消息,所以只有我才能解密,所以可得出公钥负责加密,私钥负责解密;
既然是签名,那肯定是不希望有人冒充我发消息,只有我才能发布这个签名,所以可得出私钥负责签名,公钥负责验证。
同一种道理,我在换种说法:
私钥和公钥是一对,谁都可以加解密,只是谁加密谁解密是看情景来用的:
第一种情景是签名,使用私钥加密,公钥解密,用于让所有公钥所有者验证私钥所有者的身份并且用来防止私钥所有者发布的内容被篡改.但是不用来保证内容不被他人获得。
第二种情景是加密,用公钥加密,私钥解密,用于向公钥所有者发布信息,这个信息可能被他人篡改,但是无法被他人获得。
比如加密情景:
如果甲想给乙发一个安全的保密的数据,那么应该甲乙各自有一个私钥,甲先用乙的公钥加密这段数据,再用自己的私钥加密这段加密后的数据.最后再发给乙,这样确保了内容即不会被读取,也不会被篡改.
16.Mybatis防止SQL注入
在一些安全性要求很高的应用中(比如银行软件),经常使用将SQL语句全部替换为存储过程这样的方式,来防止SQL注入。这当然是一种很安全的方式,但我们平时开发中,可能不需要这种死板的方式。
不管输入什么参数,打印出的SQL都是这样的。这是因为MyBatis启用了预编译功能,在SQL执行前,会先将上面的SQL发送给数据库进行编译;执行时,直接使用编译好的SQL,替换占位符“?”就可以了。因为SQL注入只能对编译过程起作用,所以这样的方式就很好地避免了SQL注入的问题。
【底层实现原理】MyBatis是如何做到SQL预编译的呢?其实在框架底层,是JDBC中的PreparedStatement类在起作用,PreparedStatement是我们很熟悉的Statement的子类,它的对象包含了编译好的SQL语句。这种“准备好”的方式不仅能提高安全性,而且在多次执行同一个SQL时,能够提高效率。原因是SQL已编译好,再次执行时无需再编译。
#{}:相当于JDBC中的PreparedStatement
${}:是输出变量的值
简单说,#{}是经过预编译的,是安全的;${}是未经过预编译的,仅仅是取变量的值,是非安全的,存在SQL注入。
17.HashpMap与ConcurrentHashMap的区别
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。
线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据
HashpMap不是线程安全的,ConcurrentHashMap是线程安全的
多次运行,输出的结果可能不一致。这样说明多线程修改ConcurrentHashMap中的数据,不能保证多线程同步。需要进行加锁或者其他能达到线程同步的方式配合使用。
ArrayList和Vector有什么区别?HashMap和HashTable有什么区别?StringBuilder和StringBuffer有什么区别?这些都是Java面试中常见的基础问题。面对这样的问题,回答是:ArrayList和LinkedList是非线程安全的,Vector是线程安全的;HashMap是非线程安全的,HashTable是线程安全的;StringBuilder是非线程安全的,StringBuffer是线程安全的。
非线程安全是指多线程操作同一个对象可能会出现问题。而线程安全则是多线程操作同一个对象不会有问题。
线程安全必须要使用很多synchronized关键字来同步控制,所以必然会导致性能的降低。
所以在使用的时候,如果是多个线程操作同一个对象,那么使用线程安全的Vector;否则,就使用效率更高的ArrayList。
非线程安全不等于不安全
有人在使用过程中有一个不正确的观点:我的程序是多线程的,不能使用ArrayList要使用Vector,这样才安全。
非线程安全并不是多线程环境下就不能使用。注意我上面有说到:多线程操作同一个对象。注意是同一个对象。比如最上面那个模拟,就是在主线程中new的一个ArrayList然后多个线程操作同一个ArrayList对象。
如果是每个线程中new一个ArrayList,而这个ArrayList只在这一个线程中使用,那么肯定是没问题的。
HashMap、Hashtable、ConcurrentHashMap的原理与区别
HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
HashMap
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
18.HashMap和Hashtable都实现了Map接口。主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
重要术语
1) sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
2) Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
3) 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。
19.ConcurrentHashMap具体是怎么实现线程安全的?
肯定不可能是每个方法加synchronized,那样就变成了HashTable。
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
总结ConcurrentHashMap就是一个分段的hashtable ,根据自定的hashcode算法生成的对象来获取对应hashcode的分段块进行加锁,不用整体加锁,提高了效率
HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。
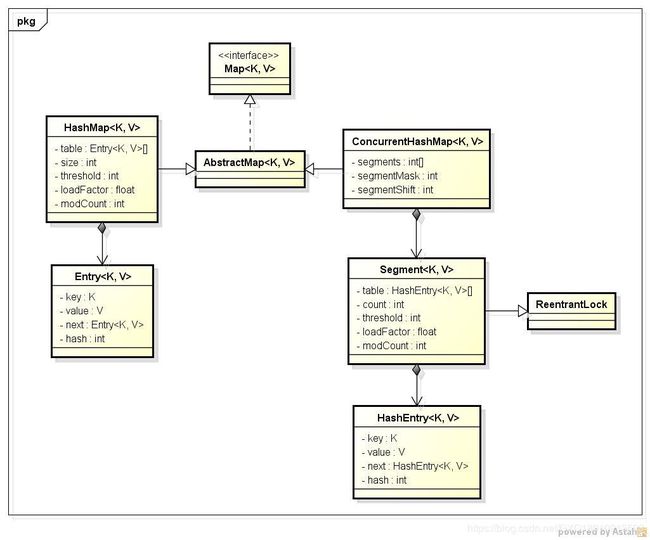
从类图中可以看出来在存储结构中ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
20.volatile变量
volatile作为java中的关键词之一,用以声明变量的值可能随时会别的线程修改,使用volatile修饰的变量会强制将修改的值立即写入主存,主存中值的更新会使缓存中的值失效(非volatile变量不具备这样的特性,非volatile变量的值会被缓存,线程A更新了这个值,线程B读取这个变量的值时可能读到的并不是是线程A更新后的值)。volatile会禁止指令重排。
适用场景
JDK中ConcurrentHashMap的Entry的value和next被声明为volatile
volatile VS synchronized
volatile不会让线程阻塞,响应速度比synchronized高,这是它的优点
链表和数组的区别在哪里?
二者都属于一种数据结构
从逻辑结构来看
1. 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费;数组可以根据下标直接存取。
2. 链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项,非常繁琐)链表必须根据next指针找到下一个元素
从内存存储来看
1. (静态)数组从栈中分配空间, 对于程序员方便快速,但是自由度小
2. 链表从堆中分配空间, 自由度大但是申请管理比较麻烦
从上面的比较可以看出,如果需要快速访问数据,很少或不插入和删除元素,就应该用数组;相反, 如果需要经常插入和删除元素就需要用链表数据结构了。
21.注册bean的生命周期,并发
在说明前可以思考一下Servlet的生命周期:实例化,初始init,接收请求service,销毁destroy;
Spring上下文中的Bean也类似,如下
1、实例化一个Bean--也就是我们常说的new;
2、按照Spring上下文对实例化的Bean进行配置--也就是IOC注入;
3、如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String)方法,此处传递的就是Spring配置文件中Bean的id值
4、如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory(setBeanFactory(BeanFactory)传递的是Spring工厂自身(可以用这个方式来获取其它Bean,只需在Spring配置文件中配置一个普通的Bean就可以);
5、如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文(同样这个方式也可以实现步骤4的内容,但比4更好,因为ApplicationContext是BeanFactory的子接口,有更多的实现方法);
6、如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessBeforeInitialization(Object obj, String s)方法,BeanPostProcessor经常被用作是Bean内容的更改,并且由于这个是在Bean初始化结束时调用那个的方法,也可以被应用于内存或缓存技术;
7、如果Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法。
8、如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法、;
注:以上工作完成以后就可以应用这个Bean了,那这个Bean是一个Singleton的,所以一般情况下我们调用同一个id的Bean会是在内容地址相同的实例,当然在Spring配置文件中也可以配置非Singleton,这里我们不做赘述。
9、当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法;
10、最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
22.springMVC原理
23.springboot常用的注解
@SpringBootApplication
@Controller 和 @RestController
@RequestMapping
@RequestBody和@ResponseBody
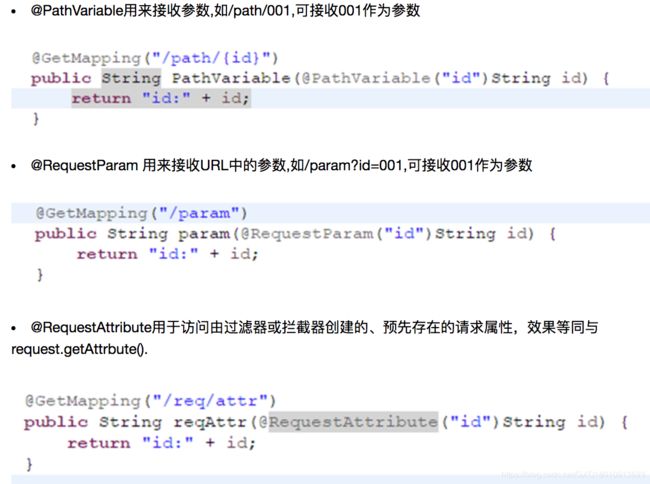
@PathVariable、@RequestParam、@RequestAttribute
@Component、@Service、@Repository
这三者都是申明一个单例的bean类并纳入spring容器中,后两者其实都是继承于@Component。
- @Component 最普通的组件,可以被注入到spring容器进行管理
- @Repository 作用于持久层
- @Service 作用于业务逻辑层
24.dubbo原理
25.zookeeper的作用
1.节点选举
主节点挂了之后,从节点就会接手工作,并且,保证这个节点是唯一的,这就是首脑模式,从而保证集群的高可用
2.统一配置文件管理
只需要部署一台服务器,则可以把相同的配置文件,同步更新到其他所有服务器,比如,修改了redis统一配置
3.发布与订阅
类似消息队列MQ、amq、rmq,dubbo,发布者把数据存在znode节点上,订阅者会读取这个数据
4.分布式锁
分布式环境中,不同进程之间争夺资源,类似于多线程中的的锁
5.集群管理
集群中,保证数据的一致性
26.Redis缓存
用SETNX实现分布式锁
27.JVM优化
Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用。对垃圾回收算法有很详细的跟踪。详细说明参考这里
JProfiler:商业软件,需要付费。功能强大。详细说明参考这里
VisualVM:JDK自带,功能强大,与JProfiler类似。推荐。
如何调优:观察内存释放情况、集合类检查、对象树,配置JVM启动参数
28.数据库优化
1.索引,建立索引是数据库优化各种方案之中成本最低,见效最快的解决方案
2.分库分表分区
分库,可以按照业务分库,分流数据库并发压力,使数据库表更加有条理性,最起码更加好找吧,我们当时是把查询库和系统库(增删改比较频繁的表)分开了,这样如果有大查询,不影响系统库
分表,刚才说了,索引适合应对百万级别的数据量,千万级别数据量使用的好,勉强也能凑合,但如果是上亿级别的数据量,索引就无能为力了,因为单索引文件可能就已经上百兆或者更多了,那么,轮到我们的分表分区登场了
分表的方法有很多种
a、如果这个业务是有流程的,那么我们通常会设计一个历史表或者归档表,用来存放历史数据,这样能保证实时数据效率比较高
b、针对某一张大表,可以根据查询条件分成多张表,比如时间,我们可以将半个月或者10天的数据放到一张表里(看具体数据量,个人认为3000W是个上限,最好控制到百万级别),每过10天,我们就自动创建一张数据库表,然后将数据插入,如此,按照时间查询,就要先定位去那种表中去取数,这样,效率能够得到大幅度提升,当然,这么解决也有问题,比如跨表,需要union多张表,而且跨表没法支持索引
c、上面的方法是我们直接通过程序和数据库实现的最原始的分表解决方案,现在市面上有一些成熟的软件如mycat,也是支持分表的,我们之前从事的公司有个专门做分布式数据库的,这些产品出现跨表,可以不使用程序union了,而且还是使索引生效,但是需要对产品有一定的掌握
d、一般来讲,数据库中的大表毕竟只是一少部分,仅需要对这少部分大表进行分表就可以了,没必要小表也进行分表,增加维护开发难度
3.数据库引擎的选取
mysiam也有弱点,那就是他是表级锁,而innodb是行级锁,所以,mysiam适用于一次插入,多次查询的表,或者是读写分离中的读库中的表,而对于修改插入删除操作比较频繁的表,就很不合适了
4.数据缓存,减少实时查询的情况
5.读写分离
在数据库并发大的情况下,最好的做法就是进行横向扩展,增加机器,以提升抗并发能力,而且还兼有数据备份功能
6.选取最适用的字段属性
在可能的情况下,应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。
如果让你设计,你来说说怎么做aop
Redis 怎么保证有序不乱的
ZK 和 Dub 的负载均衡和集群怎么弄的,原理是啥