JavaScript的执行原理
JS是一门脚本语言,不需要编译,边解释边执行,所以在性能上比不上C/C++这样的编译型语言。JS的执行引擎有好多种,这些解析引擎大都存在于浏览器内核之中,比如:
Chrome : webkit/blink : V8
FireFox: Gecko : SpiderMonkey
Safari : webkit : JavaScriptCore
IE : Trident : ChakraJS不一定非要在浏览器中运行,只要有JS引擎即可,最典型的比如NodeJS,采用了谷歌的v8引擎,使得JS完全脱离浏览器运行。
浏览器显示HTML
不同的浏览器对HTML的解析过程不太相同,这里介绍一下webkit的渲染过程:
构建DOM树、构建Render树,布局Render树,绘制Render树。

浏览器在解析HTML文件的时候,“自上而下”加在,加载的过程中进行解析渲染。在解析过程中,如果遇到请求外部资源,如图片、CSS、iconfot等,这些请求过程是异步的,不会影响HTML文档的继续加载和解析。
解析过程中,浏览器首先会解析HTML文件构造DOM树,然后解析CSS文件构建渲染树,渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕。这个过程非常复杂,涉及到两个概念:reflow 和 repaint。
DOM节点中各个元素都是盒模型,要求浏览器去计算位置大小等,这个过程是reflow,当盒子模型位置、大小、其他属性如颜色,字体确定之后,浏览器便开始绘制内容,这个过程叫做repaint。
页面首次加载的时候,两个过程都会发生,这两个过程都很消耗性能,尤其是reflow,如果优化的不好,会造成很坏的用户体验。所以,我们要尽量减少reflow和repaint。尽量合并一些过程,比如要改变某个元素的多个属性。有三个方法:
ele.style.width = '100px';
ele.style.height = '200px';
ele.style.color = 'red';ele.style.cssText = ';width:'+100+'px;height:'+200+'px;color:red';.cls {
width:100px;
height:200px;
color:red;
}
ele.addClass('cls');这三种方法,明显我们不要采用第一种,因为每一句都会造成浏览器重绘,很消耗性能。第二种第三种就很好,合并之后,一次性渲染。
JS的执行
先上一幅图:

当文档加载过程中遇到JS文件,HTML文档会立马挂起渲染的线程(加载解析渲染同步进行),挂起后,要等到JS文件加载完而且解析执行完之后,才恢复HTML文档的渲染线程。为啥?因为JS可能会修改DOM结构,最明显的例子就是document.write,一句让你前功尽弃。这也就意味着:在JS执行完成之前,后续所有资源的下载都可能没有必要没有意义,这也就是JS阻塞后续资源下载的根本原因,所以,开发过程中,经常把JS代码放到HTML文档末尾。
JS的解析是由浏览器的JS解析引擎完成的。JS是单线程运行,换言之:同一个时间只做一件事,所有的任务都得排队,前面一个任务结束,后面一个任务才能开始。所以,当遇到很耗费时间的任务,比如I/O读写等,需要一种机制可以先执行后面的任务。这就有了同步和异步。
JS的执行机制就是一个主线程 + 一个任务队列。同步任务就是放在主线程上执行的任务,异步任务就是放在任务队列的任务。所有的同步任务都在主线程执行,这构成了一个执行栈,异步任务有了运行结果会在任务队列中放置一个事件,比如定时2秒,到2秒后才能放进任务队列(callback放进任务队列,而不是setTimeout函数放进队列)。脚本运行时,先依次运行执行栈,然后从队列中提取事件来运行任务队列中的任务,这个过程是不断重复的。所以叫事件循环(Event Loop)。
以setTimeout来说明JS事件执行机制
console.log(1);
setTimeout('console.log(2)', 1000);//引擎会将字串转为代码
console.log(3);运行:1 3 2
代码做一下升级:
<script type="text/javascript">
console.log(1);
setTimeout(function() {console.log(2);}, 300);
setTimeout(function() {console.log(3);}, 400);
for (var i = 0; i < 1000; i++) {
console.log(4)
}
setTimeout(function() {console.log(5);}, 100);
script>我们先来看看什么是Event Loop
Event Loop
因为JS是单线程的,这是从JS引擎的角度来看的,所谓的单线程就是指在JS引擎中负责解释和执行JS代码的线程只有一个:主线程。
除了主线程,还存在其他线程。例如:处理ajax请求的线程,处理DOM事件的线程,定时器,读写文件的线程(Node.JS)等。这里以setTimeout()为例:当代码中调用setTimeout()时,注册的延时方法交由浏览器内核的某个模块来处理(webkit是webcore模块),当到达设置的时间,这个延时方法被添加到任务队列里,这个过程由浏览器其他模块处理,与执行引擎主线程独立,执行引擎在主线程的方法执行完毕之后,达到空闲时,会从任务队列中顺序取出任务来执行,这个过程是个不断循环的过程:称为事件循环模型。
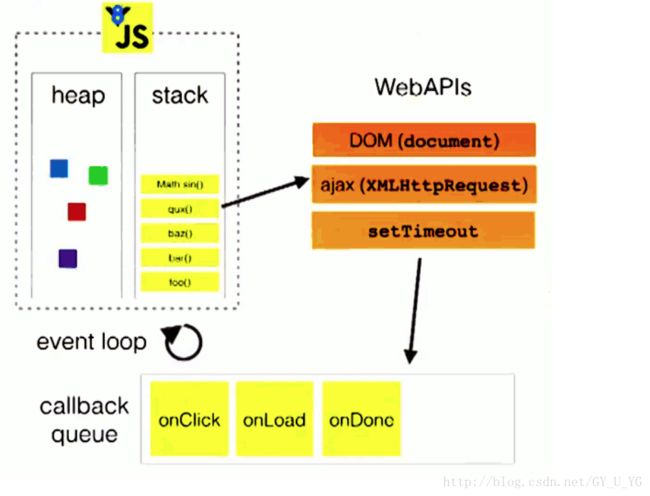
JS执行引擎的主线程运行的时候,产生堆(Heap)和栈(stack)。程序中代码依次进入栈中等待执行,当调用setTimeout()方法时,即上图右边webAPIs方法,浏览器内核相应模块开始延时方法的处理,当延时方法达到触发条件时,方法被添加到用于回调的任务队列,只有执行引擎栈中的代码执行完毕,主线程才会去读取任务队列,依次执行那些满足触发条件的回调函数。
上图中的callback queue中指的是“任务队列”,也可以理解为消息队列,“消息”可以理解为:注册异步任务时添加的回调函数:
setTimeout(function() {console.log('hello');}, 1000);其中,function() {console.log(‘hello’);}就是一个消息,任务队列中保存的就是这些回调函数。
理解JS代码的执行
看一段代码:
console.log('-----start-----');
setTimeout(function() {console.log('hello');}, 200);
setTimeout(function() {console.log('world');}, 100);
console.log('-----end-------');

我们来分步进行这个问题的解答:
【主线程里面是同步任务,在执行栈中出栈即被执行,异步任务先交由相应的模块处理比如Timer模块,一定是等到达触发条件比如时间到了,callback才会被放在任务队列中,一旦执行栈中任务完成了,就会到任务队列中去执行队列中的各个callback】
1,JS执行引擎开始执行上述代码时候,会先将一个main()方法加入执行栈(参考C/C++)。首先,第一个console.log(‘—–start——’)入栈,因为这一句console.log是浏览器内核支持的普通方法,并非webAPIs涉及的方法,所以这一句立即出栈被引擎执行;
2,引擎继续往下,将setTimeout(callback, 200)添加到执行栈。因为该方法是webAPIs里的方法,属于事件循环模型中的webAPIs方法,引擎在将setTimeout()方法出栈执行时,将延时执行的函数交给了相应的模块,右边的Timer模块来处理。
3,主线程继续向下执行,紧接着将第二个定时器也交给了Timer模块,然后执行到第二个console.log(),立马出栈被引擎执行,打印——end——-
4,执行完毕后清空执行栈。但是并没有结束,在主线程执行的同时,Timer模块会检查其中的异步代码,一旦满足触发条件,就会将它添加到任务队列中。timer2只延迟了100ms,早于timer1的200ms,会早于timer2被添加到队列排头。而主线程此时处于空闲(执行栈空闲),会检查任务队列是否有待执行的任务。此时会将timer2回调中的console.log(‘world’)执行了,然后执行栈空闲后继续检查任务队列,将timer1的代码执行了,打印“hello”,清空执行栈,此时任务队列为空,执行结束,程序处理完毕,main()方法也出栈。
5,注意:不是setTimeout加入了事件队列,而是setTimeout里的回调函数加入了事件队列。
回到最初的问题
<script type="text/javascript">
console.log(1);
setTimeout(function() {console.log(2);}, 300);//timer1
setTimeout(function() {console.log(3);}, 400);//timer2
for (var i = 0; i < 10000; i++) {
console.log(4);//大约需要4000ms的时间
}
setTimeout(function() {console.log(5);}, 100);//timer3
script>
此时就很好理解了:console.log(1)入栈立马被执行,引擎遇到timer1和timer2交给内核的Timer模块,引擎继续前进,遇到10000次的循环,这是同步任务是主线程的,不管多少时间都要先执行,因为这是执行栈里的任务,执行栈里的任务没完成是不会执行任务队列里的异步callback的,哪怕超时了。执行10000次循环后继续在执行栈内前进,碰到timer3,扔给内核中的Timer模块,继续前进,遇到结束打印,立马执行。好了,现在执行栈里的同步任务完了,清闲了才到任务队列中去看看,依次取得各种callback来执行。
在这个例子中,因为一万次循环大约需要3000ms-4000ms,这个很久,在JS引擎执行这10000次循环的时候,Timer模块已经将timer1,timer2放进任务队列了,尽管timer3只有更少的100ms,但此时JS引擎还没开始执行到timer3,也就还没被扔到Timer模块,所以,你再短也没用。
问题的延伸
<script type="text/javascript">
console.log(1);
setTimeout(function() {console.log(2);}, 400);
setTimeout(function() {console.log(3);}, 300);
for (var i = 0; i < 10000; i++) {
console.log(4)
}
setTimeout(function() {console.log(5);}, 100);
console.log('--------end---------');
script>
以上,timer1和timer2延时调一下,当然还是短时的先执行,很好理解!
也就是说:如果setTimeout加入队列的阻塞时间大于两个setTimeout执行的间隔时间,那么先加入任务队列的先执行,尽管它里面设置的时间延时更长。
<script type="text/javascript">
setTimeout(function() {console.log('我先定时的,我400ms');}, 400);
var start = new Date();
for (var i = 0; i < 5000; i++) {
console.log('这里模拟了5000次循环的耗时操作');
}
var end = new Date();
console.log('阻塞时长:' + Number(end - start) + '毫秒');
setTimeout(function() {console.log('我后定时的,我300ms');}, 300);
script>
这样描述:JS引擎遇到第一个定时器,扔给Timer模块,timer模块开始计时,JS引擎继续前进,遇到5000次循环这是同步任务在执行栈,必须硬着头皮一心一意的执行,共耗时438ms(其实在400ms的时候,Timer模块已经把timer1的callback放入了任务队列),JS引擎继续前进,遇到第二个定时器,扔给Timer模块(Timer模块开始计时)。此时,执行栈已经空了,JS引擎开始取任务队列发现timer1的callback早就在了,赶紧执行,然后再执行timer2的,尽管timer1的延时更长,但是,它先到队列,timer2虽然说很短,但是人家timer1都计完时了在等了,你timer2才开始计时。
现在把循环改短一些,5000 –> 500:
<script type="text/javascript">
setTimeout(function() {console.log('我先定时的,我400ms');}, 400);
var start = new Date();
for (var i = 0; i < 500; i++) {
console.log('这里模拟了500次循环的耗时操作');
}
var end = new Date();
console.log('阻塞时长:' + Number(end - start) + '毫秒');
setTimeout(function() {console.log('我后定时的,我300ms');}, 300);
script>
43 < 100,自己理解吧。
JS为何是单线程的
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。(在JAVA和c#中的异步均是通过多线程实现的,没有循环队列一说,直接在子线程中完成相关的操作)
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
JS是单线程的,那么他是如何是实现异步操作的
JS的异步是通过回调函数实现的,即通过任务队列,在主线程执行完当前的任务栈(所有的同步操作),主线程空闲后轮询任务队列,并将任务队列中的任务(回调函数)取出来执行。”回调函数”(callback),就是那些会被主线程挂起来的代码。异步任务必须指定回调函数,当主线程开始执行异步任务,就是执行对应的回调函数。
虽然JS是单线程的但是浏览器的内核是多线程的,在浏览器的内核中不同的异步操作由不同的浏览器内核模块调度执行,异步操作会将相关回调添加到任务队列中。而不同的异步操作添加到任务队列的时机也不同,如 onclick, setTimeout, ajax 处理的方式都不同,这些异步操作是由浏览器内核的 webcore 来执行的,webcore 包含上图中的3种 webAPI,分别是 DOM Binding、network、timer模块
onclick 由浏览器内核的 DOM Binding 模块来处理,当事件触发的时候,回调函数会立即添加到任务队列中。
setTimeout 会由浏览器内核的 timer 模块来进行延时处理,当时间到达的时候,才会将回调函数添加到任务队列中。
ajax 则会由浏览器内核的 network 模块来处理,在网络请求完成返回之后,才将回调添加到任务队列中。JS中的异步运行机制
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个”任务队列”(task queue)。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
(3)一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。