《YOLOv3: An Incremental Improvement》论文解读之YOLOv3
1. yolov3实现的idea
Abstract
我们给YOLO提供一些更新! 我们做了一些小的设计更改以使其更好。 我们也训练了这个非常好的新网络。它比上次(YOLOv2)稍大一些,但更准确。它仍然很快,所以不用担心。在320×320 YOLOv3运行22.2ms,28.2 mAP,像SSD一样准确,但速度快三倍。 当我们看看以老的0.5 IOU mAP检测指标时,YOLOv3是相当不错的。 在Titan X上,它在51 ms内实现了57.9的AP50,与RetinaNet在198 ms内的57.5 AP50相当,性能相似但速度快3.8倍。与往常一样,所有代码均在https://pjreddie.com/yolo/。
1.1 边界框的预测(Bounding Box Prediction)
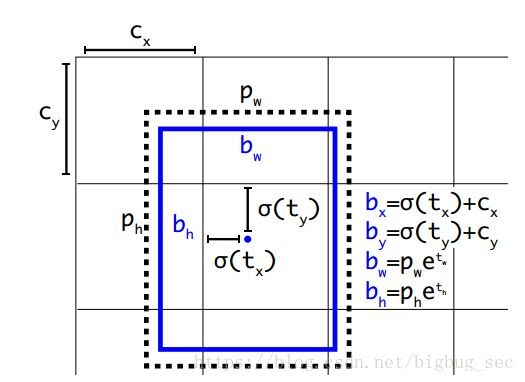
在YOLO9000之后,我们的系统使用维度聚类(dimension clusters )作为anchor boxes来预测边界框[13]。网络为每个边界框预测4个坐标,tx,ty,tw,th。 如果单元格从图像的左上角偏移(cx; cy),并且之前的边界框具有宽度和高度pw,ph,则预测对应于:
与之前yolo版本一样,yolov3的anchor boxes也是通过聚类的方法得到的。yolov3对每个bounding box预测四个坐标值(tx, ty, tw, th),对于预测的cell(一幅图划分成S×S个网格cell)根据图像左上角的偏移(cx, cy),以及之前得到bounding box的宽和高pw, ph可以对bounding box按以上的方式进行预测 。
在训练这几个坐标值的时候采用了sum of squared error loss(平方误差损失总和),因为这种方式的误差可以很快的计算出来。
yolov3对每个bounding box通过逻辑回归预测一个物体的得分,如果预测的这个bounding box与真实的边框值大部分重合且比其他所有预测的要好,那么这个值就为1.如果overlap没有达到一个阈值(yolov3中这里设定的阈值是0.5),那么这个预测的bounding box将会被忽略,也就是会显示成没有损失值。
1.2 分类(Class Prediction)
每个框预测分类,bounding box使用多标签分类(multi-label classification)。
每个框使用多标签分类来预测边界框可能包含的类。我们不使用softmax,因为我们发现它对于高性能没有必要,相反,我们只是使用独立的逻辑分类器。 在训练过程中,我们使用二元交叉熵损失来进行类别预测。(只是使用了简单的逻辑回归进行分类,采用的二值交叉熵损失(binary cross-entropy loss)。)
这个公式有助于我们转向更复杂的领域,如Open Image Dataset[5]。在这个数据集中有许多重叠的标签(如女性和人物)。使用softmax会强加了一个假设,即每个框中只有一个类别,但通常情况并非如此。多标签方法更好地模拟数据。
1.3 跨尺度的预测(Predictions Across Scales)
yolov3在三个(num=3)不同的尺度预测boxes,yolov3使用的特征提取模型通过FPN(feature pyramid network)网络上进行改变,最后预测得到一个3-d tensor,包含bounding box信息,对象信息以及多少个类的预测信息。论文给出是这样子的:(N×N×[3*(4+1+80)])这里的80即是80类物体。
接下来,我们从之前的两层中取得特征图(feature map),并将其上采样2倍。我们还从网络中的较早版本获取特征图,并使用element-wise addition将其与我们的上采样特征进行合并。这种方法使我们能够从早期特征映射中的上采样特征和更细粒度的信息中获得更有意义的语义信息。然后,我们再添加几个卷积层来处理这个组合的特征图,并最终预测出一个相似的张量,虽然现在是两倍的大小。
我们再次执行相同的设计来预测最终尺度的方框。因此,我们对第三种尺度的预测将从所有先前的计算中获益,并从早期的网络中获得细粒度的特征。
我们仍然使用k-means聚类来确定我们的边界框的先验。我们只是选择了9个聚类(clusters)和3个尺度(scales),然后在整个尺度上均匀分割聚类。在COCO数据集上,9个聚类是:(10×13);(16×30);(33×23);(30×61);(62×45); (59×119); (116×90); (156×198); (373×326)。
FPN结构如下:
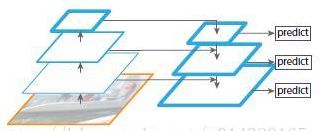
yolov3使用这样的方式使得模型可以获取到更多的语义信息,模型得到了更好的表现。
yolov3依然使用k-Means聚类来得到bounding box的先验,选择9个簇以及3个尺度,然后将这9个簇均匀的分布在这几个尺度上。
1.4 特征提取(Feature Extractor)
yolov3的特征提取模型是一个杂交的模型,它使用了yolov2,Darknet-19以及Resnet,这个模型使用了很多有良好表现的3*3和1*1的卷积层,也在后边增加了一些shortcut connection结构。最终他有53个卷积层,因此作者也把它们叫成Darknet-53。它们的结构是这样的:
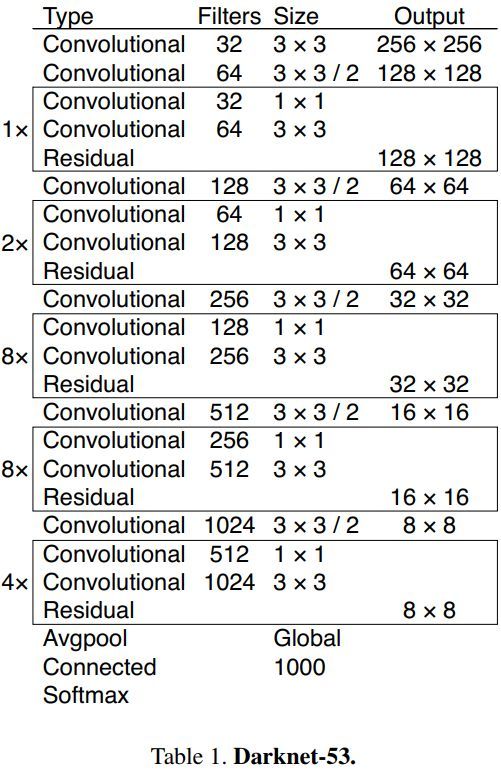
这个新网络比Darknet-19功能强大得多,而且比ResNet-101或ResNet-152更有效。以下是一些ImageNet结果:
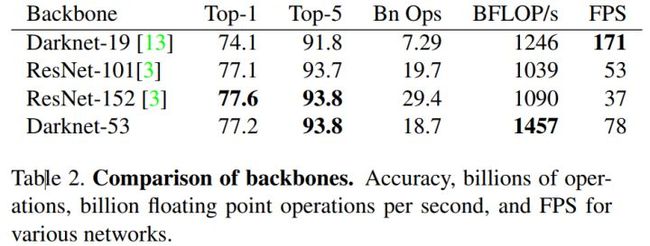
每个网络都使用相同的设置进行训练,并以256×256的单精度测试进行测试。运行时间是在Titan X上以256×256进行测量的。因此,Darknet-53可与state-of-the-art的分类器相媲美,但浮点运算更少,速度更快。Darknet-53比ResNet-101更好,速度更快1:5倍。 Darknet-53与ResNet-152具有相似的性能,速度提高2倍。
Darknet-53也可以实现每秒最高的测量浮点运算。这意味着网络结构可以更好地利用GPU,从而使其评估效率更高,速度更快。这主要是因为ResNets的层数太多,效率不高。
1.5 训练
我们仍然训练完整的图像,没有hard negative mining or any of that stuff 。我们使用多尺度训练,大量的data augmentation,batch normalization,以及所有标准的东西。我们使用Darknet神经网络框架进行训练和测试[12]。
2. yolov3做了些什么?
就说yolov2有个毛病就是对小物体的检测不敏感,关键在于它那个cell预测时导致的毛病,而如今增加了多尺度预测之后yolov3在对小物体检测方便有了好转,但是现在的毛病是对中、大size的物体表现的不是那么好,这还得需要我们去努力做。然而在论文中yolov3各种表示的还行。
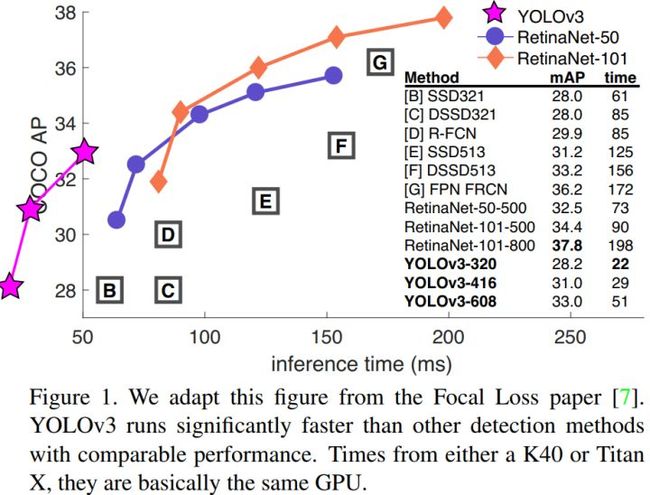
YOLOv3非常好!请参见表3。就COCO的mAP指标而言,它与SSD variants相当,但速度提高了3倍。尽管如此,它仍然比像RetinaNet这样的其他模型落后很多。
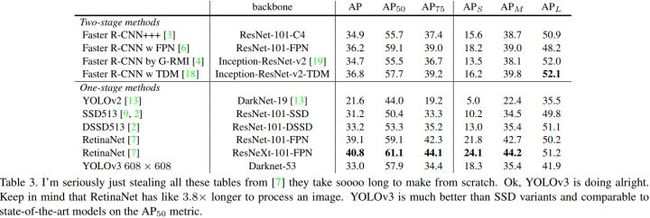
然而,当我们在IOU = 0.5(或者图表中的AP50)看到mAP的“旧”检测度量时,YOLOv3非常强大。它几乎与RetinaNet相当,并且远高于SSD variants。这表明YOLOv3是一个非常强大的检测器,擅长为目标生成像样的框(boxes)。However, performance drops significantly as the IOU threshold increases indicating YOLOv3 struggles to get the boxes perfectly aligned with the object。
在过去,YOLO在小目标的检测上表现一直不好。然而,现在我们看到了这种趋势的逆转。 随着新的多尺度预测,我们看到YOLOv3具有相对较高的APS性能。但是,它在中等和更大尺寸的物体上的表现相对较差。需要更多的研究来达到这个目的。当我们在AP50指标上绘制精确度和速度时(见图3),我们看到YOLOv3与其他检测系统相比具有显著的优势。也就是说,速度越来越快。
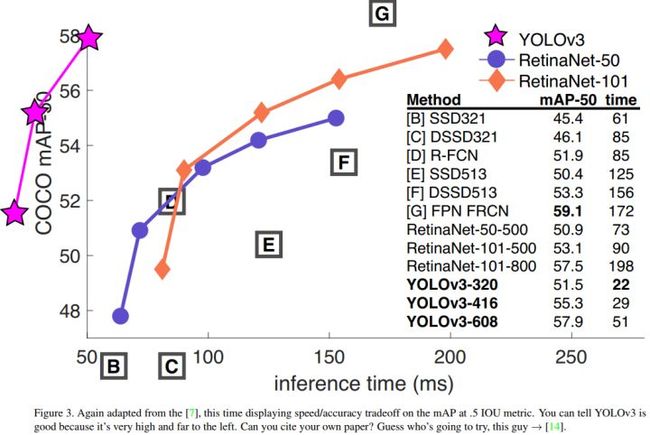
注:这个图只能用Amazing来概括!!!
3. yolov3那些尝试过并没有提升表现的想法(Things We Tried That Didn’t Work)
① 想对Anchor box的x,y偏移使用线性激活方式做一个对box宽高倍数的预测,结果发现没有好的表现并且是模型不稳定。
②对anchor box的x, y使用线性的预测,而不是使用逻辑回归,实验结果发现这样做使他们模型的mAP掉了。
③使用Focal loss,测试结果还是掉mAP。(想法的确挺好的)
我们在研究YOLOv3时尝试了很多东西。很多都不起作用。这是我们可以记住的东西。
Anchor box x,y offset predictions。我们尝试使用正常anchor box预测机制,这里你使用线性激活来预测x,y offset作为box的宽度或高度的倍数。我们发现这种方法降低了模型的稳定性,并且效果不佳。
Linear x,y predictions instead of logistic。我们尝试使用线性激活来直接预测x,y offeset 而不是逻辑激活。这导致mAP下降了几个点。
Focal loss。我们尝试使用focal loss。它使得mAp降低了2个点。YOLOv3对focal loss解决的问题可能已经很强大,因为它具有单独的对象预测和条件类别预测。 因此,对于大多数例子来说,类别预测没有损失? 或者其他的东西? 我们并不完全确定。
Dual IOU thresholds and truth assignment 。Faster R-CNN在训练期间使用两个IOU阈值。如果一个预测与ground truth重叠达到0.7,它就像是一个正样本,如果达到0.3-0.7,它被忽略,如果小于0.3,这是一个负样本的例子。我们尝试了类似的策略,但无法取得好成绩。
我们非常喜欢我们目前的表述,似乎至少在局部最佳状态。有些技术可能最终会产生好的结果,也许他们只是需要一些调整来稳定训练。
4.What This All Means
YOLOv3是一个很好的检测器。速度很快,很准确。COCO平均AP介于0.5和0.95 IOU指标之间的情况并不如此。但是,对于检测度量0.5 IOU来说非常好。
为什么我们要改变指标? 最初的COCO论文只是含有这个神秘的句子:“一旦评估服务器完成,就会添加完整的评估指标的讨论”。Russakovsky等人报告说,人类很难区分IOU为0.3还是0.5。“训练人们目视检查一个IOU值为0.3的边界框,并将它与IOU 0.5区分开来是一件非常困难的事情。”[16]如果人类很难区分这种差异,那么它有多重要?
但是也许更好的问题是:“现在我们有了这些检测器(detectors),我们要做什么?”很多做这项研究的人都在Google和Facebook上。我想至少我们知道这项技术是非常好的,绝对不会被用来收集您的个人信息,并将其出售给......等等,您是说这就是它的用途?
那么其他大量资助视觉研究的人都是军人,他们从来没有做过任何可怕的事情,例如用新技术杀死很多人哦等等.....
我有很多希望,大多数使用计算机视觉的人都是做的快乐,研究了很多好的应用,比如计算一个国家公园内的斑马数量[11],或者追踪它们在它们周围徘徊时的猫[17]。但是计算机视觉已经被用于可疑的应用,作为研究人员,我们有责任至少考虑我们的工作可能会造成的伤害,并考虑如何减轻它的影响。 我们非常珍惜这个世界。(作者走心了......)
创新点
- 使用金字塔网络
- 用逻辑回归替代softmax作为分类器
- Darknet-53
不足
速度确实快了,但mAP没有明显提升,特别是IOU > 0.5时。
常见数据集和竞赛
下面我列出了一些研究者在评估新的目标检测模型时常用的数据集:
-
PASCAL VOC 2012 检测竞赛:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
-
COCO 2018 目标检测任务:http://cocodataset.org/#detection-2018
-
ImageNet 目标检测挑战赛:https://www.kaggle.com/c/imagenet-object-detection-challenge
-
Google AI Open Images——目标检测:https://www.kaggle.com/c/google-ai-open-images-object-detection-track
-
视觉遇上无人机挑战:http://www.aiskyeye.com/views/index
扩展阅读
论文
-
YOLO:https://arxiv.org/abs/1506.02640
-
YOLO9000:https://arxiv.org/abs/1612.08242
-
YOLOv3:https://arxiv.org/abs/1804.02767
-
SSD:https://arxiv.org/abs/1512.02325
-
DSSD:https://arxiv.org/abs/1701.06659(本文中没有讨论,但值得一读)
-
用于密集目标检测的焦点损失:https://arxiv.org/abs/1708.02002
-
卷积神经网络的有趣失败和 CoordConv 解决方案:https://arxiv.org/abs/1807.03247(查看有关目标检测的相关章节)以及相关视频:https://www.youtube.com/watch?v=8yFQc6elePA
讲座
-
Stanford CS 231n:第 11 讲 | 检测和分割:https://www.youtube.com/watch?v=nDPWywWRIRo&t=1967s
标注数据的工具
-
CVAT:https://github.com/opencv/cvat
相关链接
1.论文:
https://pjreddie.com/media/files/papers/YOLOv3.pdf
2.翻译
https://zhuanlan.zhihu.com/p/34945787
3.代码
https://github.com/pjreddie/darknet
4. 官网
https://pjreddie.com/darknet/yolo/
5. YouTube
https://www.youtube.com/watch?v=MPU2HistivI
6. 旧版
https://pjreddie.com/darknet/yolov2/
https://pjreddie.com/darknet/yolov1/
7. 源码分享
https://github.com/muyiguangda/darknet
8. YOLOv3在Windows下的配置(无GPU)
https://blog.csdn.net/baidu_36669549/article/details/79798587
9.知乎话题:如何评价YOLOv3: An Incremental Improvement?
10.进击的YOLOv3,目标检测网络的巅峰之作