【强化学习】DDPG 算法实现案例
问题描述与Demo介绍
完整代码:
如果觉得不错,麻烦点颗星哦!
1.Demo介绍
在该demo中,我们将利用DDPG算法,使一个机械臂学会自己变换角度去抓“方块”,如下图,机械臂从最开始完全不知道如何去捕捉方块,到最后,每次都能精准的抓住方块。


2.算法介绍
其实理解 Deep Deterministic Policy Gradient (DDPG)最快的方法就是讲其分解开看:Deep Deterministic Policy Gradient = Deep + Deterministic Policy Gradient ,而 Deterministic Policy Gradient = Deterministic + Policy Gradient 。总体来说,DDPG = Deep + Deterministic + Policy Gradient 。
Deep,顾名思义:更深的层次,这里很容易联想到 Deep Learning ,而 Deep Learning 又与神经网络有着密切的联系,所以我把Deep理解成神经网络,用神经网络构造更深更复杂的网络结构。
Policy gradient :强化学习中经典的方法,用于处理连续动作中的筛选(不熟悉的可以看我上一篇博客)
Deterministic:众所周知,Policy gradient 输出动作概率,然后根据学到的动作的分布随机进行筛选,而 Deterministic 直接改变了动作输出过程,在连续的动作上直接输出一个动作值。
3.算法实现
算法流程:

代码框架:(下图出自:博客)
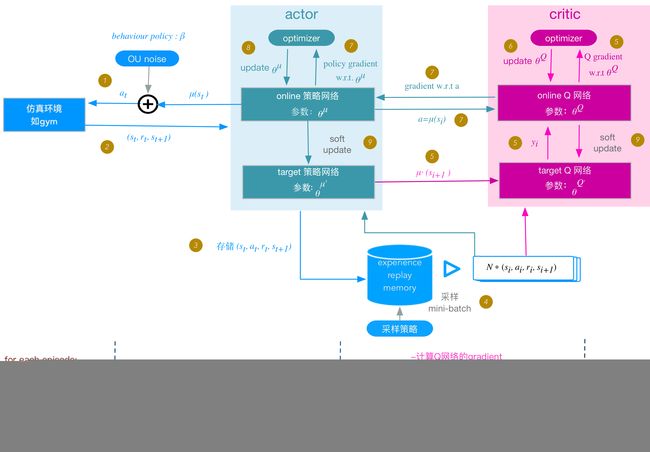
上面两个图非常重要,第一个是整体代码流程,方便我们在大脑中形成DDPG大致思想,后面一张图是具体每一步在做什么。
接下来,我们用上面两个图来一步步解释DDPG代码结构:
1. 首先,我们需要实现一个critic network和一个actor network,然后再实现一个target critic network和target actor network,并且对应初始化为相同的weights:
actor network & target actor network
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.001)
net = tf.layers.dense(s, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l1',
trainable=trainable)
net = tf.layers.dense(net, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l3',
trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound,
name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
critic network & target critic network 同理
2. 初始化replay memory buffer R
经验回放机制,解决网络片面看待问题甚至学不到东西的问题。
原理回顾: 经验回放机制是DQN那篇文章提出的,DQN 每一次根据所获得的来更新Q-value,本质就是stochastic gradient descent (SGD)。一般在用mini-batch SGD做优化时,都假设样本之间的相对独立,从而使得每个mini-batch内数据所含的噪声相互抵消,算法收敛的更快。
在这个问题中,之所以加入experience replay是因为样本是从游戏中的连续帧获得的,这与简单的reinforcement learning问题(比如maze)相比,样本的关联性大了很多,如果没有experience replay,算法在连续一段时间内基本朝着同一个方向做gradient descent,那么同样的步长下这样直接计算gradient就有可能不收敛。因此experience replay是从一个memory pool中随机选取了一些 experience,然后再求梯度,从而避免了这个问题。
class Memory(object):
def __init__(self, capacity, dims):
"""用 numpy 初始化记忆库"""
def store_transition(self, s, a, r, s_):
"""保存每次记忆在 numpy array 里"""
def sample(self, n):
"""随即从记忆库中抽取 n 个记忆进行学习"""
3. 回合循环:
在介绍回合循环之前,先介绍下UO随机过程,OU过程其实给action添加一个均值为0的OU噪声。然后这么做有什么好处呢?首先,一是增加训练的step,使得训练的更快;其次,探索效率确实更高。(想知道具体的去查看相关论文)
for each episode:
初始化UO随机过程;
for t = 1 ,do:(下面的编号与上图代码构架中的步骤相同)
1. actor 根据behavior策略选择一个行动 a t a_t at, 下达给gym执行该行动 a t a_t at .
2.gym执行 a t a_t at ,返回reward r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1;
3. actor将这个状态转换过程(transition): ( s t s_t st , a t a_t at , r t r_t rt , s t + 1 s_{t+1} st+1 ) 存入replay memory buffer R中,作为训练online网络的数据集。
4.从replay memory buffer RR中,随机采样NN个 transition 数据,作为online策略网络、 online Q网络的一个mini-batch训练数据。我们用 ( s i s_i si , a i a_i ai , r i r_i ri , s i + 1 s_{i+1} si+1 )表示mini-batch中的单个transition数据。
5.计算online Q网络的 gradient
6.update online Q: 采用Adam optimizer更新 θ Q θ^Q θQ;
7.计算策略网络的policy gradient
8.update online策略网络:采用Adam optimizer更新 θ μ θ^μ θμ;
9.soft update target网络 μ ′ μ′ μ′ 和 Q ′ Q′ Q′:
代码实现:(结合上面的步骤看十分易懂)
def train():
var = 2. # control exploration
for ep in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for t in range(MAX_EP_STEPS):
# while True:
if RENDER:
env.render()
# Added exploration noise
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), *ACTION_BOUND) # add randomness to action selection for exploration
s_, r, done = env.step(a)
M.store_transition(s, a, r, s_)
if M.pointer > MEMORY_CAPACITY:
var = max([var * .9999, VAR_MIN]) # decay the action randomness
b_M = M.sample(BATCH_SIZE)
b_s = b_M[:, :STATE_DIM]
b_a = b_M[:, STATE_DIM: STATE_DIM + ACTION_DIM]
b_r = b_M[:, -STATE_DIM - 1: -STATE_DIM]
b_s_ = b_M[:, -STATE_DIM:]
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
ep_reward += r
if t == MAX_EP_STEPS - 1 or done:
# if done:
result = '| done' if done else '| ----'
print('Ep:', ep,
result,
'| R: %i' % int(ep_reward),
'| Explore: %.2f' % var,
)
break
if os.path.isdir(path): shutil.rmtree(path)
os.mkdir(path)
ckpt_path = os.path.join('./' + MODE[n_model], 'DDPG.ckpt')
save_path = saver.save(sess, ckpt_path, write_meta_graph=False)
print("\nSave Model %s\n" % save_path)
def eval():
env.set_fps(30)
s = env.reset()
while True:
if RENDER:
env.render()
a = actor.choose_action(s)
s_, r, done = env.step(a)
s = s_