Selenium 爬取评论数据,就是这么简单!

本文来自作者 秦子敬 在 GitChat 上分享「如何利用 Selenium 爬取评论数据?」,「阅读原文」查看交流实录
「文末高能」
编辑 | 飞鸿
一、前言
我们知道,如今的 web 网页数据很多是动态加载的,普通的爬虫只是抓取静态的网页。实用性很差,因此,我们需要使用 Selenium 来爬取动态数据。评论区的数据,大多数情况下,都需要下拉刷新才能加载出来。而 Selenium 就能帮我们很好的爬取动态数据。
在本场 Chat 中我将介绍如何用基于 Selenium 的爬虫爬取 B 站评论,并介绍如何用 Firefox 浏览器的实用插件 FirePath 协助爬虫。主要内容包括:
-
对比静态爬虫与动态爬虫
-
什么是 Selenium?Selenium 工具的安装(基于 Firefox 浏览器)
-
介绍强大的 Xpath 定位工具——FirePath 协助爬虫
-
实例操作:爬取 B 站评论
-
拓展:介绍 Tar 浏览器,实现匿名 IP 爬虫,防止 IP 封禁
二、环境搭建
(1) Windows10(有兴趣的小伙伴可以在Linux尝试)
(2)IDE:JetBrains PyCharm Community Edition 2017.1.2 x64(如果是学生、可以申请到免费版)
(3)Python2.7、pip工具
(4)Firefox浏览器(版本55.0)以及Firefox下的插件FirePath
这里介绍一下FirePath的安装。打开Firefox 按以下步骤安装:

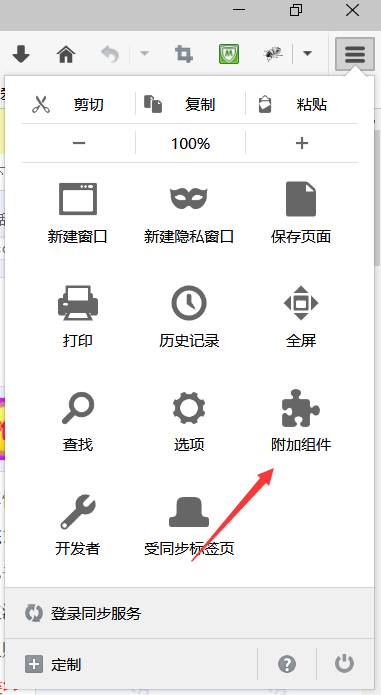
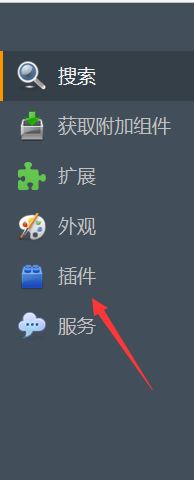
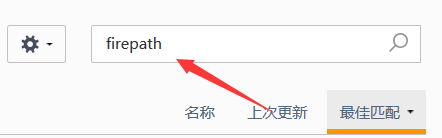

(5)Selenium版本3.5
使用Pip工具在windows的cmd命令行下
Pip install selenium

因为我这里已经装好了 所以cmd显示的输出会和你们不一样。
(6)FireFox对应的Selenium驱动程序
下载链接:驱动下载地址(https://github.com/mozilla/geckodriver/releases)
注意FireFox和Selenium版本对应 笔者在安装这个驱动的时候走了不少弯路。
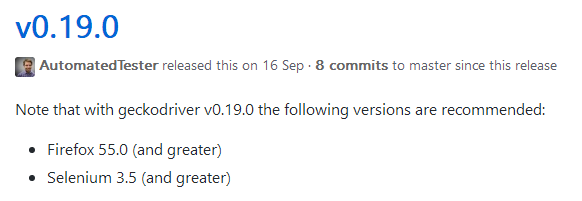
这个是笔者使用的版本。
还有以下几点一定要注意,那就是下载好的驱动程序请解压到浏览器所在文件夹目录 并且复制好路径到环境变量path。并且请把Firefox浏览器的.exe文件的路径也复制到环境变量path,把驱动文件拷贝一份放在你Python2.7的目录下。这样才能正常建立浏览器和驱动的联系。
Mac 和 linux 可以参考这篇回答(windows也有介绍):关于驱动安装失败常见解答(https://www.zhihu.com/question/49568096)
三、正文内容
1. 对比静态爬虫与动态爬虫
爬虫是什么呢?爬虫又被称为网络蜘蛛、网络机器人,是一种自动抓取万维网信息的程序或脚本。我们日常使用的搜索引擎就是通过爬虫技术实现的。我们可以使用爬虫来获取大量数据。
我们平时上网的时候,有时需要填写各种验证码,如果你观察细心,有些验证码旁边会有一行字:“我们需要验证你是不是机器人。”这就建站人用验证码的方式过滤掉一些爬虫。
其实Python也有识别验证码的库,这里给大家推荐pytesseract库,一般的验证码都能解决,有兴趣的朋友可以去了解
可以参考这篇文章:Pytesseract库识别验证码(http://www.cnblogs.com/yutingmoran/p/5984213.html)
那么,为什么建设网站的人要检测爬虫呢?你会想,不都是访问网页吗?但是,我们需要知道,使用爬虫会给网站的服务器带来不少负担,影响服务器性能。而且,爬虫并不是真正的人,不是真正的客户,这当然不被建站人喜欢。而且爬虫爬取来的数据最好不要用于商业用途,不然会遇上法律纠纷的。
这里有一篇文章是关于爬虫使用不当的案例:爬虫使用不当法律纠纷文章(http://www.sohu.com/a/72197083_115980)
因此,我们写爬虫的人,应该站在建站人的角度思考。尽可能在不影响服务器使用的情况下获取需要的数据。
爬虫根据爬取的数据的不同,可以分为静态的爬虫和动态的爬虫。有些网页只是一个简单的web网页,数据不会动态更新,像百度百科、csdn的博文等等,展示一个网页。单纯只有静态数据的web网页已经不多了。所以静态的爬虫实用性很差。
有些数据则不同,他是动态的,像淘宝里的评论区里的数据,b站里的评论区数据,动态加载。那么静态爬虫就不够用了。那么这时我们就需要我们的法宝—Selenium了
2. 什么是 Selenium?Selenium工具安装(基于 Firefox 浏览器)
Selenium是一个浏览器自动化测试框架。本来是作为web应用程序测试的工具。它可以直接运行在浏览器里,模仿真正的用户操作。目前支持IE、Firefox、Safari、Chrome大多数主流浏览器。以前是不用驱动的,现在如果要使用Selenium必须要安装对应浏览器的驱动。也就是说,使用Selenium,爬虫能够更像人的行为,去访问网页,从而获取到有用的信息。
有下面几点好处:一、爬虫的行为更接近人使用浏览器时的操作,降低了被服务器发现的可能。二、对于有些动态数据,比如需要用户下拉刷新才出来的数据,普通的静态爬虫是无可奈何的。
那么使用Selenium模拟用户行为,下拉滚动条就可以把隐藏的数据获取到了。
工具的安装上文已经说明,这里就不再赘述。
3. 介绍强大的 Xpath 定位工具——FirePath 协助爬虫
如果你之前写过爬虫,你就会发现,爬数据前,需要对网页的HTML进行分析。定位到需要的数据处。你也许看过不少教程里教的,使用正则表达式,通过css定位等等。还没爬到数据,就被这个网页分析手工定位数据烦死了。太繁琐了。
上帝教导我们要好好使用工具,而不是只用蛮力。要巧干。这里向大家介绍一款神器。Firefox的定位工具FirePath。
安装的方法上文已经有讲,不再赘述。下面介绍,如何使用它。
(1)打开Firefox,在插件的界面选择启用FirePath。

这里我已经启用了,所以按钮显示的是禁用。如果你是第一次使用,按钮上显示的应该是启用。
(2)在Firefox打开你需要爬取数据的网页 键盘按F12。
(3)

(4)使用鼠标在网页处点击你需要的获取的数据 比如标题,你会发现FirePath已经自动为你生成对应的xPath定位代码。
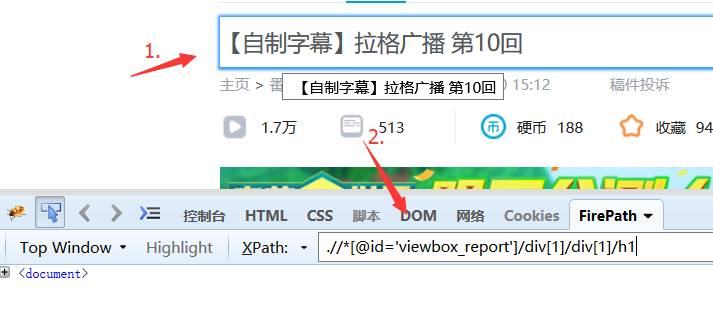
这样就不用手动分析html结构,自己写路径了。大大提高了效率。
(5)当然也可以使用其他格式的 在这里可以切换。
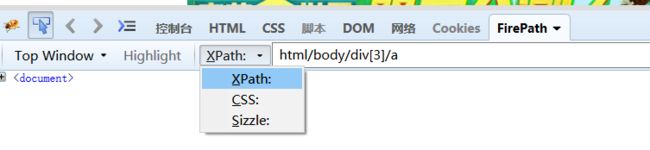
Xpath和css定位是比较好的定位方式了。
4. 实例操作:爬取 B 站评论
接下来,通过实战的方式来学习一下,具体如何Selenium去爬取B站的评论。实战以前,介绍一些要用到的方法。
(1)
fp = webdriver.Firefox() #获得基于Firefox的对象 fp.set_preference("permissions.default.stylesheet",2) fp.set_preference("permissions.default.image",2)
这个是对Selenium自动化测试的配置。可以选择不加载图片、css渲染、禁止使用Javascript目的是为了加快网页的加载。这里根据需要自由选择。第二个参数填2表示禁用。更多用法可以到Selenium官网查看文档
Selenium官网
如果进不去,代表你需要一些特殊的工具。这里不做介绍。
(2)
target = app.find_element_by_xpath(".//*[@id='recommend_report']/div[1]/span")
使用find_element_by_xpath()即通过xpath来定位参数就用FirePath获取到的xpath.当然也有其他方式定位
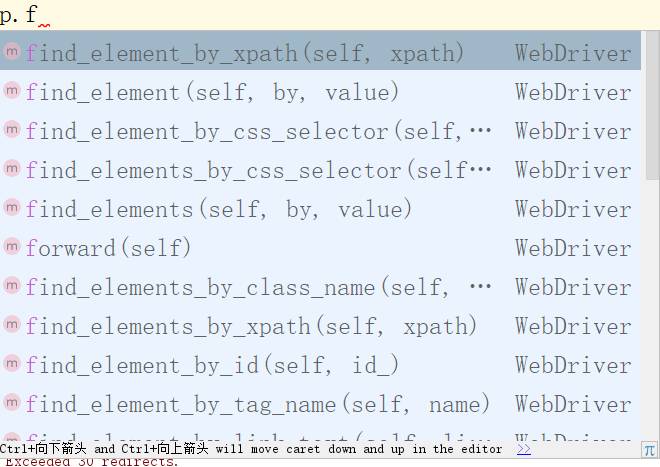
读者可以试试其他方法。
值得注意的是,find_elements_by_xpath和find_element_by_xpath一个有s一个没有。前者返回一个数组,后者返回一个元素。其他方法同理。这里推荐xpath与css两种方法,比较精准。
(3)
1.app.execute_script("arguments[0].scrollIntoView();", target)#定位到特定的元素 2.time.sleep(3)
这里执行script语句,去定位到我们要到的位置。模拟滚动条下拉。但是值得一提的是每次返回执行一次有关数据请求与返回的方法。最好暂停一会。这是让服务器有缓冲的余地。所以使用time.sleep()
我们在本次实战准备爬取B站的评论区数据、经过分析,b站的评论区数据要下拉到浏览器的一定位置评论区数据才会显示。再分析需要的数据,爬取下响应的数据。这里就不一一分析。有疑问的小伙伴,我可以在chat时给你们解答。这里贴出笔者写的代码。
1.#coding=utf-8 2.from selenium import webdriver 3.import sys 4.import time 5.from selenium.webdriver.common.keys import Keys 6.reload(sys) 7.sys.setdefaultencoding("utf-8") 8. 9. 10.app = webdriver.Firefox() 11.app.get("https://www.bilibili.com/video/av3553625/?from=search&seid=10292605247919873793") 12. 13.target = app.find_element_by_xpath(".//*[@id='recommend_report']/div[1]/span") 14.app.execute_script("arguments[0].scrollIntoView();", target)#定位到特定的元素 15.time.sleep(3) 16. 17.target2 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div[4]/span/a"); 18.app.execute_script("arguments[0].scrollIntoView();", target2) 19.time.sleep(3) 20.target2.click() 21. 22.for i in range(20): 23. if(i==7): 24. continue 25. name = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[1]/a[1]") 26. test = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/p") 27. if (i != 13 and i != 17): 28. pinglun1 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[3]/div[1]/div/div[1]/span") 29. if (i != 13 and i != 17): 30. pinglun2 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[3]/div[2]/div/div[1]/span") 31. if(i !=12 and i !=13 and i != 17): 32. pinglun3 = app.find_element_by_xpath(".//*[@id='bbComment']/div[1]/div[4]/div["+str(i+1)+"]/div[2]/div[3]/div[3]/div/div[1]/span") 33. print ("作者:") 34. print (name.text.strip()) 35. print ("内容:") 36. print test.text.strip() 37. print ("后续:") 38. if (i != 13 and i != 17): 39. print pinglun1.text.strip() 40. if (i != 13 and i != 17): 41. print pinglun2.text.strip() 42. if (i != 12 and i != 13 and i != 17): 43. print pinglun3.text.strip() 44. print ("\n") 45. time.sleep(3) 46.app.quit()
因为有些评论区的数据是有的,有些是没有的。我们就在for循环里加了一个if判断。如果那一层的评论没有,就Continue跳过就好。
效果图如下:
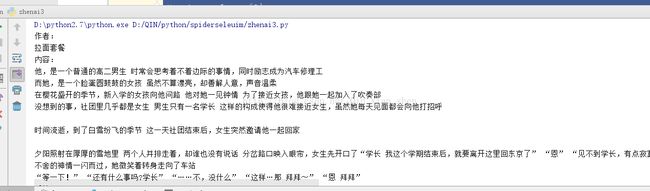
这些数据是评论区的精彩热评,我爬下了作者的用户名ID 评论内容 和这个评论的跟帖评论。加以整理。
值得一提的是,如果Selenium能做的还远远不止这些,还能模拟点击事件,键盘的输入事件。这个给大家留一个思考题,尝试使用Selenium模拟登陆B站。
提示:使用方法app.click() app.sendkey() app.clear()
参考文章:selenium自动化登陆操作(http://www.cnblogs.com/wzben/p/5024830.html)
5. 拓展:介绍 Tor 浏览器,实现匿名 IP 爬虫,防止 IP 封禁
在爬虫过程中,如果操作不当,被服务器监测到,就有可能导致自己的IP被网站封禁。在一定时间内,拒绝访问。那么有什么办法可以解决呢?
再向大家推荐一款神器,Tor浏览器。这个浏览器,据说这个浏览器本来是
美国军方用来获取信息的工具。能够匿名IP,把自己的的真实IP给隐藏。使用别人的ip。加密算法很强大。著名的比特币发明人中本聪,就是通过这个工具隐藏自己的身份,推广比特币的。
要想进一步了解。Tor浏览器。可以看一下这些文章。
-
Tor浏览器详情( http://www.cnblogs.com/likeli/p/5719230.html )
-
Tor浏览器详情( http://blog.csdn.net/whiup/article/details/52317779 )
-
Tor浏览器详情( https://www.deepdotweb.com/2014/05/23/use-tor-socks5-proxy/ )
(1)安装tor浏览器:安装tor浏览器
( http://www.theonionrouter.com/projects/torbrowser.html.en )
(2)如何配置tor浏览器:配置tor浏览器
( https://jingyan.baidu.com/article/adc815137654fbf723bf73b1.html )
(3)Python安装相应的库
Pip install pysocks Pip install stem
(4)使用方法
先打开Tor浏览器 再运行程序:
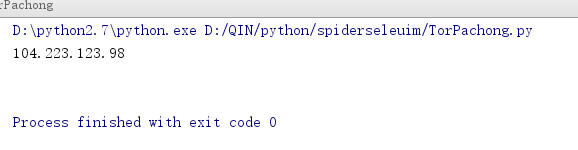
import socks import socket import requests socks.set_default_proxy(socks.SOCKS5,"127.0.0.1",9150) #9150是默认端口 socket.socket = socks.socksocket a = requests.get("http://checkip.amazonaws.com").text print a
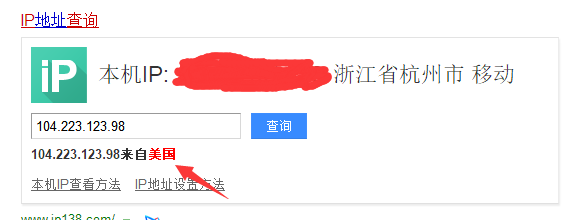
这个代码会通过访问http://checkip.amazonaws.com,得到一个ip,你会发现这不是你的真实ip,大多情况下是国外的ip:
用百度查找IP :
(5)切换IP
1.#coding=utf-8 2.from stem import Signal 3.from stem.control import Controller 4.import socket 5.import socks 6.import requests 7.import time 8.import sys 9.reload(sys) 10.sys.setdefaultencoding('utf-8') 11. 12.controller = Controller.from_port(port=9151) 13.controller.authenticate() 14.socks.set_default_proxy(socks.SOCKS5,"127.0.0.1",9150) 15.socket.socket = socks.socksocket 16. 17.total_scrappy_time = 0 18.total_changeIP_time = 0 19.for x in range(0,10): 20. a = requests.get("http://checkip.amazonaws.com").text 21. print ("第"+str(x+1)+"次IP:"+a) 22. 23. time1 = time.time() 24. a = requests.get("http://www.santostang.com/").text 25. 26. time2 = time.time() 27. total_scrappy_time = total_scrappy_time + time2-time1 28. print ("第"+str(x+1)+"次抓取花费时间:"+str(time2-time1)) 29. 30. time3 = time.time() 31. controller.signal(Signal.NEWNYM) 32. time.sleep(5) 33. time4 = time.time() 34. total_changeIP_time = total_changeIP_time + time4-time3-5 35. print ("第"+str(x+1)+"次更换IP花费时间: "+str(time4-time3-5)) 36. 37.print ("平均抓取花费时间:"+str(total_scrappy_time/10)) 38.print ("平均更换IP时间:"+str(total_changeIP_time/10))
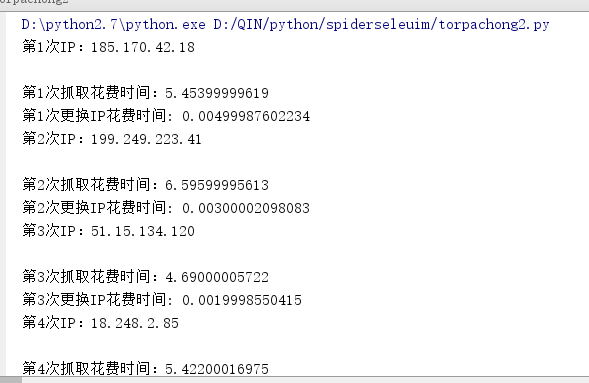
6. 可能提到到的问题
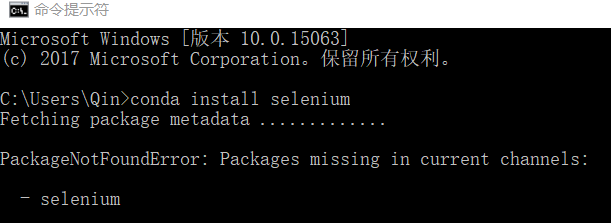
为什么使用 Python2.7而不是Python3?为什么不用更好的Anaconda而是使用pip下载工具?
笔者平时也是使用Python3的,之前想尝试在Python3下使用Selenium发现使用不了。笔者使Anaconda在命令行
Conda install selenium
会发现Anaconda没有这个库。
7. 推荐资料
-
《Python网络爬虫从入门到实践》—唐松(非常赞的一本书 17年刚刚出版)
-
《Selenium2 自动化测试实战》—虫师(推荐虫师的博文,非常不错)
有兴趣的朋友可以了解Scrapy框架,爬虫非常好用,实用。爬虫效率会得到大大提升。
8. 写在最后的话
真的真的非常感谢各位能够来参加这场chat,这是我第一次做chat,感谢各位的支持。感激不尽。如果本文能给你带来些许帮助,这真是我的荣幸。感谢。
松爱家的小秦
近期热文
《TensorFlow 人脸识别网络与对抗网络搭建》
《带你从零开始,快速学会 Matlab GUI》
《Docker 落地踩过的坑》
《如何快速入门网络基础知识(TCP/IP 和 HTTP》
《Node 企业项目大规模实践》
福利

「阅读原文」看交流实录,你想知道的都在这里