从零开始,搭建 AI 音箱 Alexa 语音服务

本文来自作者 Mike 在 GitChat 上分享 「从零开始,搭建 AI 音箱 Alexa 语音服务」,「阅读原文」查看交流实录。
「文末高能」
编辑 | 哈比
一、概述

生活场景的引入: 物联网的快速发展,各种智能设备层出不穷,作为极客,家里早已安上了用 APP 控制的智能灯、智能插座,刚刚安装上的时候,还有新鲜感,久了之后,是不是会有这样的现象:
早上醒来要开灯,需要经过:
迷迷糊糊从床头柜上摸到手机
手机用指纹解锁
连接无线网络
找到对应设备的 APP
点击开灯按钮
这样的场景真的为生活带来了便利吗 ? 糟糕的体验,繁琐的过程,从而使这个产品慢慢淡出我们的生活场景 . 于是,那个物理开关的使用频次又恢复了,这或许也是智能设备不能普及的根本原因之一。
以上生活的场景有很多,根本原因是缺少了和产品对话的功能,即语音交互,所以显得不那么智能。
理想的情景:
早晨醒来时,只需要说一声: 睡醒了,然后灯自动亮起,窗帘自动打开,音乐自动响起 ….,这样的场景你还满意吗 ?
一个便利的生活场景描述正式带你进入本文的环节: 语音交互。

根据人机交互这个维度,主要划分了三个时代:
第一个时代:PC 时代。让电脑明白人类的意图,通过鼠标、键盘的方式输入让浏览器搜索获取想要的知识。
第二个时代:移动时代。Touch 称为该时代交互方式,就是 2007 年乔布斯发布的 iPhone。触摸屏的出现极大的提高了用户交互的体验,容易上手。
键盘和触摸同共构成了互联网交互方式的过去和现在。从另外一个角度说,也可以把键盘对应于 PC 时代交互方式,把触摸对应于移动时代交互方式。
正是因为用户从 PC 转移到了移动端,互联网行业才发生了那么多的变化。
第三个时代:AI 时代。语音称为该时代的交互方式,每一部手机都将能听会说,每一台家电都将能听会说,每一辆汽车都将能听会说,无人驾驶,每一个玩具都将能听会说。
语音时代,用户只需要用说话的方式给服务终端发布命令,就能得到相应的服务 . 这一产业从上世纪六十年代就已出现,但并不为普通消费者所熟知,消费者对其认知度也比较低。
近年来,随着苹果、亚马逊、谷歌、微软等公司先后推出 Siri、Echo 等智能语音服务,这一服务以及相关产业也开始被普通消费者和投资界所关注。
这里必须要提到亚马逊的 Echo 智能音箱。Echo 已经成为语音时代的一个重大创新,成为智能家庭的一个现象级应用。
由于 Echo 尚没有中文版,所以大家没有体会到它的热度,然而在美国,已经成为 “ 一款现象级的革命性产品 “。
从 2014 年 11 月正式发布到现在,亚马逊的 Echo 智能音箱超过两岁了。在这两年时间里,它从一开始随时可能夭折的 “ 新生儿 “,发展成如今市场上最为火热的智能家居产品之一。
二、国内外智能音响

随着着亚马逊 Echo 的火爆引发一连串的效应,这也是智能音箱行业的一个重要转折点。各大巨头纷纷入局,如亚马逊 Alexa、微软 Cortana、Google Assistant、苹果 Siri、三星 Bixby、等智能语音助手。
如今,这场战火也点燃了中国市场。井喷式发展的中国智音箱市场已经成为了科技巨头、传统行业厂商、创业公司博弈的竞技场,玲琅满目的智能音箱产品都奔赴在路上 !
各大厂商的音响盘点,单品测评,性价比优势,各种平台已报道出很多,这里以音响的软硬件配置作为切入点,分析各大厂商的方案选型,性价比优劣势:

1. 麦克风
麦克风是智能音响很重要的环节,包括远场拾音、噪声抑制、混响去除、人声干扰抑制、声源测向、声源跟踪、阵列增益等功能,进而提高语音信号处理质量,以提高真实环境下的语音识别率。
通过对比图可以看出亚马逊 Echo、天猫精灵、小米 AI 音响、叮咚 2 代技术路线类似,使用了 6、7、8 个麦克风环形阵列,使得波束的空间区分性更强,保证声源定位和拾音效果。
谷歌 Home 和问问音响则不同,采用双麦克风方案,对麦克风的数量和阵列排列结构依赖较少,更加依赖语音增强算法,从而获得良好的拾音效果。
根据第三方测评机构,和 Echo 对比,谷歌 Home 在 3 米内的综合能力(拾音、信噪比、抗噪、抗回声)要更好。
谷歌的麦克风阵列采用的算法很有特点,他们对深度学习的应用较深,算是一种波束成型和深度学习相结合的一种形式 。
2. 处理器
亚马逊 Echo 采用 TI(德州仪器)DM3725CUS100 的芯片,主要为工业级应用,主频不高,但处理能力很强 . 功耗、性能控制的很好。
谷歌 Home 采用的是 Marvell(美满) 88DE3006 的芯片,该芯片也为工业级芯片,在通讯中应用比较多。
该芯片为 2 核,也显示了谷歌 Home 在硬件端没有太多计算能力,更多计算在云端,这样就简化了很多东西,也不需要 Codec,麦克风阵列可与主控直接相连。
天猫精灵采用的是 MTK MT8516 的语音专用芯片,这款芯片是 MTK 为智能助手打造的,主频达 1.3GHz,芯片内建 WiFi 802.11 b/g/n 和支持蓝牙 4.0,支持高达 8 通道的 TDM 麦克风阵列接口和 2 通道的 PDM 数字麦克风接口,非常适用于远场 (Far-field) 麦克风语音控制和智能音响设备,在同代中稳定性、性价比很高。
问问音响则采用的是 MTK MTK2601 芯片,面向于智能穿戴方面,1.2GHz 双核心 ARM Cortex-A7 处理器,MT2601 需要结合 MT6630 无线射频芯片,实现双频 WIFI、蓝牙 4.1 以及 ANT+ 和 FM 等功能。
叮咚 2 代采用的全志科技 R16 芯片,主要面向于智能家居方面,采用极具性价比的四核 ARM Cortex-A7 架构处理器,支持基于 Linux 的开源系统 Tina,(Tina 是全志科技全力打造的专门用于全志智能硬件平台的系统软件品牌);
支持 AirPlay、DLNA、Qplay、Airkiss、Smart Link 等多种网络应用协议;提供独特的算法、IP 包,使开发者可以专注于其自有应用和产品市场运营,降低产品开发成本,并缩短开发周期。
小米 AI 音响采用的是 Amlogic 的 A112 芯片,主要面向于智能家居方面,四核 ARM Cortex-A53 架构,8 通道 I2S 和 S /PDIF 输入和输出,具有强大的运算性能和丰富的接口,凭借四核 64 位 CPU 架构强大的计算能力,可以支持无需外部 DSP 芯片的主流远场语音识别解决方案。
卓越的音频处理能力可支持多种本地或在线高保真音乐,因此用户可随时随地欣赏音乐。
3. 扬声器发声单元
智能音响以 “智能” 出名,当下的智能音响更多的考虑是音质的选择,音质一方面受 Codec 芯片影响,另一方面也受到发音单元的影响。
亚马逊 Echo 采用的是一个高音单元、一个低音单元和一个倒相管的设计结构,保证高音的同时,也增强了低音的效果。之所以说 Echo 是智能音箱产品的典型代表,不仅仅是因为它是第一款智能音箱,更因为它在智能、音质、体积、体验上都做到了平衡。
谷歌 Home 和天猫精灵和小米 AI 和叮咚二代,在音质上稍微弱一些,仅采用了一个全频带的发音单元,通过共振鼓膜来增强一部分低音效果。
从设计结构上来看,谷歌 Home 的两片共振鼓膜也形成一种立体声效果,比其它又相对好一些。
问问音箱差异化的点在于大功率发音单元的配置,采用了 1 寸高音单元和 3 寸低音单元以及更大音腔的设计方式,功率高达 50W,从而在硬件方面提供更好的音质,这也大大提升了物料成本。
对比硬件,各家平台各有优劣势,面对不同的用户需求,需要结合软件的优化才能达到良好的体验和语音交互。
三、应用场景
1. 蓝牙音响
蓝牙技术是爱立信在 1994 年提出的,那个时候是作为 RS232 数据线的取代策略 . 蓝牙是一种无线传输技术,可以得到当多设备的短距离数据更换,如大家的智能手机,此类技术最大的长处在于无线传输,外加就是短距离,因而发射功率不需要那大,也省电。
蓝牙音箱就是将此类技术应使用有源音箱上,经过此类无线传输技术,将智能手机、平板电脑或 PC 上的数字音频传输到音箱上,就会得到无拘无束的无线音乐播放。
场景应用: 便携式音箱、离线音乐播放、 无线传输
2. 智能音响
智能音响赋予 “ 智能 “ 的功能,它的局限不止播放音乐这么简单,而是深入到生活实际的场景中去,语音直接说话下命令,代替按键、触摸屏,是人更自然的体验 . 语音控制家电,实现订餐、下单、获取资讯等各种各样的服务。
同时各大互联网巨头和科技公司都在投入大量成本,完善和改进技术,并积极投入到场景应用中。真正锁定用户真正刚性需求,深耕使用场景,或将成为未来产业致胜的关键要素。
场景应用:音乐播放、语音交互、生活助理
腾讯举办的用户开发日,体验过朋友应该已经感觉到那个神秘的方盒子力量 . 每天在使用微信、QQ 沟通交流,闲暇时在王者峡谷开黑,跳伞吃鸡的你,是否已经准备好迎接巨头将来出现在家居、交通、医疗等领域的这些形态和方式?
腾讯用户开放日,我们体验了腾讯的最新科技,发现了这些秘密
四、搭建 Alexa 语音服务
1. Amazon 注册设备
1.1 账号注册
按照以下说明 注册步骤,注册一个产品,填写相关信息并创建安全配置文件,用于与 Alexa 进行通信的访问和刷新令牌。
Note:Web 设置下的允许 origin 和返回 URL 应分别为:http://localhost:3000 和 http://localhost:3000/authresponse.

1.2 信息
注册设备后,找到安全配置(Security Profile)文件下的常规(General)选项卡,并记下 clientID,clientSecret 和 deviceTypeID。后面将需要这些信息来配置 AuthServer,获取 token。
2. 安装依赖
2.1 基本工具
安装基本的配置工具:
sudo apt-get install git gcc cmake build-essential
通过 gcc -v 和 cmke -version 查看版本,符合 gcc 4.8.5 和 cmke 3.1 以上即可。
2.2 安装 libcurl 、nghttp2 、openssl
这部分搭建很重要,由于连接到 AVS 需要使用 Http2 协议,SDK 中使用 libcur 建立该连接。
源码安装 openssl:
wget https://www.openssl.org/source/old/1.0.2/openssl-1.0.2g.tar.gz tar -xzvf openssl-1.0.2g.tar.gz cd openssl-1.0.2g ./configure // 默认安装路径 /usr/local,也可以通过--prefix 指定安装路径 make sudo make install openssl version // 确认安装版本: OpenSSL 1.0.2g 1 Mar 2016
源码安装 libcurl:
wget https://curl.haxx.se/download/curl-7.50.2.tar.gz tar -xzvf curl-7.50.2.tar.gz cd curl-7.50.2 ./configure 默认安装路径 /usr/local,也可以通过--prefix 指定安装路径 make sudo make install curl --version // 确认安装版本: curl 7.50.2
源码安装 nghttp2:
安装依赖:
sudo apt install python-dev libcunit1 libevent-dev libevent-openssl libjansson-dev libspdylay-dev libjemalloc-dev cython libnghttp2-14 libnghttp2-dev
wget https://github.com/nghttp2/nghttp2/releases/download/v1.0.0/nghttp2-1.0.0.tar.gz tar -xzvf nghttp2-1.0.0.tar.gz cd nghttp2-1.0.0 ./configure make sudo make install nghttp --version // 确认安装版本: nghttp2/1.0.0
2.3 安装 SQLite
wget https://www.sqlite.org/2017/sqlite-autoconf-3210000.tar.gz tar -xzvf sqlite-autoconf-3210000.tar.gz cd sqlite-autoconf-3210000/ make sudo make install sqlite3 -version // 去人安装版本: 大于 SQLite 3.19.3
2.4 安装 PortAudio
PortAudio 是一个免费、跨平台、开源的音频 I/O 库,示例程序必须组件。
wget http://www.portaudio.com/archives/pa_stable_v190600_20161030.tgz tar xf pa_stable_v190600_20161030.tgz cd portaudio ./configure --prefix=$LOCAL_BUILD // 需要配置安装路径 make sudo make install
2.5 安装 Gstreamer
示例应用程序需要构建媒体播放器,来实现播放 MP3 文件 . 选择 GStreamer 框架来实现 . 需要安装一些依赖项:
sudo apt-get install bison flex libglib2.0-dev libasound2-dev pulseaudio libpulse-dev libfaad-dev libsoup2.4-dev libgcrypt20-dev
gstreamer-1.10.4:
wget https://gstreamer.freedesktop.org/src/gstreamer/gstreamer-1.10.4.tar.xz tar xf gstreamer-1.10.4.tar.xz cd *gstreamer*/ ./configure make -j3 sudo make install
gst-plugins-base-1.10.4:
wget https://gstreamer.freedesktop.org/src/gst-plugins-base/gst-plugins-base-1.10.4.tar.xz tar xf gst-plugins-base-1.10.4.tar.xz cd *gst-plugins-base*/ ./configure make -j3 sudo make install
gst-libav-1.10.4:
wget https://gstreamer.freedesktop.org/src/gst-libav/gst-libav-1.10.4.tar.xz tar xf gst-libav-1.10.4.tar.xz cd *gst-libav*/ ./configure make -j3 sudo make install
gst-plugins-good-1.10.4:
wget https://gstreamer.freedesktop.org/src/gst-plugins-good/gst-plugins-good-1.10.4.tar.xz tar xf gst-plugins-good-1.10.4.tar.xz cd *gst-plugins-good*/ ./configure make -j3 sudo make install
gst-plugins-bad-1.10.4:
wget https://gstreamer.freedesktop.org/src/gst-plugins-bad/gst-plugins-bad-1.10.4.tar.xz tar xf gst-plugins-bad-1.10.4.tar.xz cd *gst-plugins-bad*/ ./configure make -j3 sudo make install
Note:GStreamer 下的组件是依赖关系,需要按顺序安装。
2.6 安装 Sensory
使用 Sensory 作为唤醒词引擎来检测唤醒词 Alexa,配置之前需要安装依赖项:
sudo apt-get -y install libasound2-dev sudo apt-get -y install libatlas-base-dev sudo ldconfig
由于官方公布的引擎是只能在树莓派上运行,运行在 Linux 平台下载链接如下,有效期限一个月 . 过了有效期,唤醒将无法使用。
sensory-gitchat:链接: https://pan.baidu.com/s/1c2lQqOS 密码: uvuk
3. 构建 SDK
3.1 克隆 SDK
克隆 SDK 之前,需要熟悉 git 的操作,参考 git 快速入手指南。
git clone [email protected]:alexa/avs-device-sdk.git git checkout v1.1.0 // 切换 v1.1.0 版本
Note:官方迭代版本比较快,截止 20171210,已经更新到 v1.3 版本,该教程以 v1.1.0 版本为准。
3.2 构建 SDK
代码框架使用 cmake,创建外部编译目录。这个目录不能是源目录的子目录 .
构建 Sensory:
这是一个 cmake 命令构建 Sensory 的例子
cmake
说明:
DSENSORY_KEY_WORD_DETECTOR_LIB_PATH: 唤醒词的路径: sensory-gitchat/lib/libsnsr.a
DSENSORY_KEY_WORD_DETECTOR_INCLUDE_DIR: 头文件路径: sensory-gitchat/include
构建 MediaPlayer:
MediaPlayer 基于 GStreamer 框架,并不是默认生成,要构建 MediaPlayer 必须 CMake 指定
-DGSTREAMER_MEDIA_PLAYER=ON选项如果 GStreamer 通过源码安装,构建的时候必须 CMake 通
DCMAKE_PREFIX_PATH选项指定前缀路径
cmake
构建 PortAudio:
这是使用 PortAudio 为 C++ 构建 AVS Device SDK 的示例 CMake 命令:
cmake
说明:
DPORTAUDIO_LIB_PATH: portaudio 的 libportaudio.a 路径DPORTAUDIO_INCLUDE_DIR: portaudio 的头文件路径
3.2 更新配置文件
源代码构建成功后,用文本编辑器打开 Integration 目录下的 AlexaClientSDKConfig.json 文件,填写设备注册时候,记录下的信息:
{ "authDelegate":{ "clientSecret":"${SDK_CONFIG_CLIENT_SECRET}", "deviceSerialNumber":"${SDK_CONFIG_DEVICE_SERIAL_NUMBER}", "refreshToken":"${SDK_CONFIG_REFRESH_TOKEN}", "clientId":"${SDK_CONFIG_CLIENT_ID}", "deviceTypeId":"${SDK_CONFIG_DEVICE_TYPE_ID}" }, "alertsCapabilityAgent":{ "databaseFilePath":"${SDK_SQLITE_DATABASE_FILE_PATH}", "alarmSoundFilePath":"${SDK_ALARM_DEFAULT_SOUND_FILE_PATH}", "alarmShortSoundFilePath":"${SDK_ALARM_SHORT_SOUND_FILE_PATH}", "timerSoundFilePath":"${SDK_TIMER_DEFAULT_SOUND_FILE_PATH}", "timerShortSoundFilePath":"${SDK_TIMER_SHORT_SOUND_FILE_PATH}" } }
填写该文件确保路径中没有任何额外的字符(或空格). 该配置还包含声音文件的路径,该文件将用于播放警报(Alarms)和计时器(Timer)的声音。
您可以从以下链接,获取 “定时器和警报” 获取所需的声音文件:Alexa Voice Service UX Design Guidelines
这时,需要数据库来存储预定的警报 . 在您的配置文件中,将文件路径位置包含到要用于存储和读取警报的数据库中。如果数据库不存在,将在该位置创建一个数据库文件。
例如 /home/avs/alerts.db.
3.3 安装
填写完 JSON 文件,并重新检查之后,进入终端的构建目录并运行 “make”。
make -j3 make install
3.4 运行 AuthServer
编译完成后,需要为设备获刷新令牌,需要运行 AuthServer,一个将处理令牌交换的本地服务器将实现它:
python AuthServer/AuthServer.py
如果您在这里遇到错误,访问 http://127.0.0.1:3000/,将在浏览器中弹出错误,请单击以获取更多详细信息,以确保您能够返回并更正它们。
3.5 运行示例程序
确保前面每一项步骤顺利完成后,到这里可以运行示例程序,进入构建目录到 SampleApp/src 文件夹并运行以下命令:
TZ=UTC ./SampleApp
REQUIRED-absolute-path-to-config-json: AlexaClientSDKConfig.json 路径OPTIONAL-absolute-path-to-wake-word-engine-folder-enclosing-model-files: sensory 唤醒词模型路径: sensory-gitchat/alexa.snsr
然后将弹出命令行界面。因为你设置了一个唤醒字引擎,因此你需要做的只是说 “Alexa”,即可进行对话。确保电脑的麦克风、喇叭处于打开状态。
五、语音服务开发指南
近年来国内外各大巨头同时发力争夺未来人工智能时代的语音入口,甚至亚马逊和阿里率先不惜代价开启了补贴大战 . 这些全球剧透的激烈竞争,将对未来十年产生极其重要的影响。
同时,这也是技术人员职业快速发展的机会。这里以语音为核心,介绍声学模型、信号处理、语音识别开发平台、结构等相关知识框图,每一个方面都需要时间去实践,可以结合自己现有知识进行拓展。
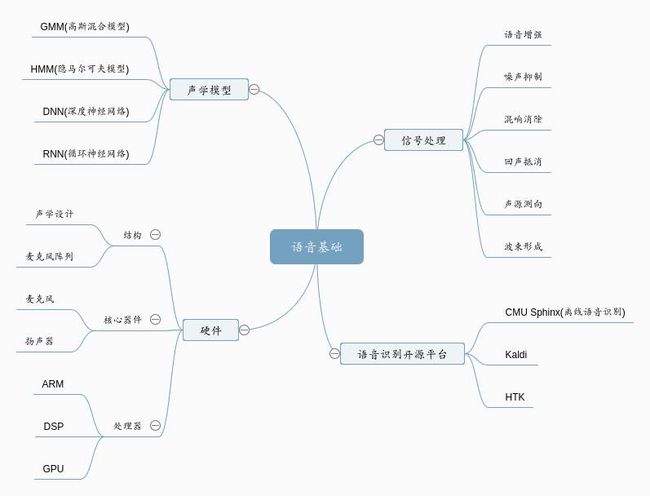
框图只做参考,部分细节需要结合实际情况去分析。
六、参考
语音智能 OS:国内 40 多家语音开发平台,做中国版 Alexa 的滋味是怎样的 ?
在和「小爱同学」相处数日后,我发现语音智能把 IoT 盘活了
这是一个智能音箱的超级全家桶,亚马逊、Google、苹果等巨头都被装在了里头
Echo Alexa 使用指南
Alexa Voice Service
七、反馈
搭建 Alexa 语音服务涉及的知识点比较多,搭建过程中遇到问题请按照以下格式描述清楚,发送至邮箱: [email protected] 。
格式要求:
[GitChat 用户名 ] : xxx
[操作系统版本 ] : 如 Ubuntu 16.04.2 LTS
[问题描述] : 搭建过程中出错的详细记录,文字、图片
近期热文
《修改订单金额!?0.01 元购买 iPhoneX?》
《让你一场 Chat 学会 Git》
《接口测试工具 Postman 使用实践》
《如何基于 Redis 构建应用程序组件》
《深度学习在摄影技术中的应用与发展》
《这样做,你的面试成功率将达到 90%》
《如何用 TensorFlow 让一切看起来更美?》

「阅读原文」看交流实录,你想知道的都在这里