机器学习总结之----2.逻辑回归
文章目录
- 什么是逻辑回归
- 逻辑回归的代价函数
- 极大似然估计
- 利用梯度下降法求参数
我也只是在学习的过程中,相当于自己理解推导一遍做个笔记,参考了别人很多东西,文末有相关链接。
什么是逻辑回归
逻辑回归也叫做对数几率回归,但它却用来做二分类。
线性回归产生的预测值为 z = θ T x z = \theta^{T}x z=θTx,线性回归通常用来做回归。但是可以在线性回归基础上,加上性质像阶跃函数但光滑可导的sigmod函数,然后算出一个概率 p ^ \widehat{p} p 来。如果 p ^ \widehat{p} p 大于0.5,可以将它判定为一类(比如正例1),小于等于0.5判定为另一类(比如负例0)。
其中,sigmod函数(简写为 σ \sigma σ)为:
σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
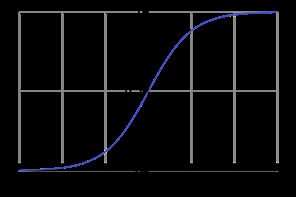
逻辑回归,在我看来就是线进行线性回归,再在它的基础上加上sigmod函数,得到一个概率值,进而判断该样本属于哪一类。计算公式如下:
p ^ = σ ( z ) = σ ( θ T ⋅ x ) = h θ ( x ) \widehat{p} = \sigma(z) = \sigma(\theta^{T}\cdot x) = h_{\theta}(x) p =σ(z)=σ(θT⋅x)=hθ(x)
其中, θ \theta θ是权重,也是我们待求参数。
根据概率值 p ^ \widehat{p} p 对样本进行分类:
y ^ = { 0 p ^ < 0.5 , 1 p ^ ≥ 0.5 \widehat{y} =\left\{\begin{matrix} 0 & \widehat{p}<0.5,\\ 1 & \widehat{p}\geq 0.5 \end{matrix}\right. y ={01p <0.5,p ≥0.5
逻辑回归的代价函数
为了使正样本得到高的概率值 p ^ \widehat{p} p (接近1好),负样本得到低的概率值 p ^ \widehat{p} p (接近0好),从而找出权重参数 θ \theta θ。设计单个样本的损失函数如下:
c ( θ ) = { − l o g ( p ^ ) y = 1 , − l o g ( 1 − p ^ ) y = 0 c(\theta) =\left\{\begin{matrix} -log(\widehat{p}) & y=1,\\ -log(1 - \widehat{p}) & y=0 \end{matrix}\right. c(θ)={−log(p )−log(1−p )y=1,y=0
对于整个数据集m个样本的损失函数如下:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( p ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − p ( i ) ) ] J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} [ y^{(i)} log(p^{(i)}) + (1-y^{(i)}) log(1-p^{(i)})] J(θ)=−m1i=1∑m[y(i)log(p(i))+(1−y(i))log(1−p(i))]
虽然没有bishijie封闭解,但因为 J ( θ ) J(\theta) J(θ)是凸函数,可以用梯度下降法求解。
极大似然估计
由以上公式,可知任何一个样本都有:
{ P ( y = 1 ∣ x ; θ ) = h θ ( x ) P ( y = 0 ∣ x ; θ ) = 1 − h θ ( x ) \left\{\begin{matrix} P(y=1|x;\theta) = h_{\theta}(x)\\ P(y=0|x;\theta) = 1 - h_{\theta}(x) \end{matrix}\right. {P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x)
整合一下:
P ( y ∣ x ; θ ) = h θ ( x ) y ( 1 − h θ ( x ) ) 1 − y P(y|x;\theta) = h_{\theta}(x) ^{y} (1 - h_{\theta}(x)) ^{1-y} P(y∣x;θ)=hθ(x)y(1−hθ(x))1−y
那么,对于所有m个样本发生的概率是:
L ( θ ) = ∏ i = 1 m P ( y ( i ) ∣ x ( i ) ; θ ) = ∏ i = 1 m h θ ( x ( i ) ) y ( i ) ( 1 − h θ ( x ( i ) ) ) 1 − y ( i ) L(\theta) = \prod_{i=1}^{m} P(y^{(i)}|x^{(i)};\theta) = \prod_{i=1}^{m} h_{\theta}(x^{(i)}) ^{y^{(i)}} (1 - h_{\theta}(x^{(i)})) ^{1-y^{(i)}} L(θ)=i=1∏mP(y(i)∣x(i);θ)=i=1∏mhθ(x(i))y(i)(1−hθ(x(i)))1−y(i)
取对数:
l ( θ ) = l o g L ( θ ) = ∑ i = 1 m [ y ( i ) l o g h θ ( x ( i ) ) + ( 1 − y ( i ) ) ( 1 − h θ ( x ( i ) ) ) ] l(\theta) = log L(\theta) = \sum_{i=1}^{m} [ y^{(i)} log h_{\theta}(x^{(i)}) + (1-y^{(i)})(1 - h_{\theta}(x^{(i)})) ] l(θ)=logL(θ)=i=1∑m[y(i)loghθ(x(i))+(1−y(i))(1−hθ(x(i)))]
得到的结果实质上和损失函数是一样的。
利用梯度下降法求参数
sigmod函数有如下性质:
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f^{'}(x) = f(x)(1-f(x)) f′(x)=f(x)(1−f(x))
J ( θ ) J(\theta) J(θ)对 θ \theta θ的第j个属性 求梯度,
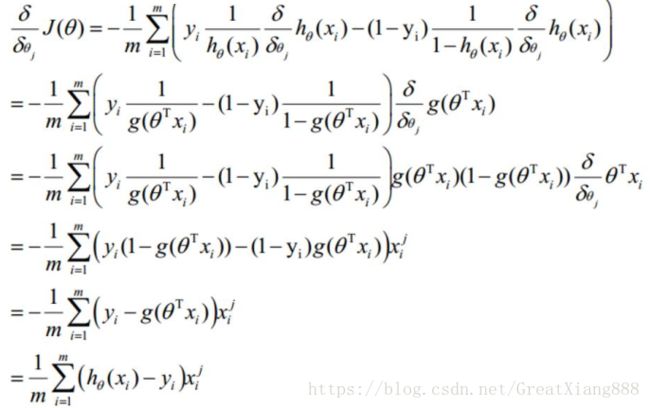
(公式实在太多了。。copy了一下)
图片中,下标i表示第i个样本,上标j表示第j维属性。(图片上下标和其他的文字刚好反过来)
最后,对 θ \theta θ的第j个属性来说,梯度下降的表达式为:
θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_{j} := \theta_{j} - \alpha \frac{1}{m} \sum_{i=1}^{m} ( h_{\theta}(x^{(i)}) - y^{(i)} )x_{j}^{(i)} θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
其中, α \alpha α是学习率,m为样本数量, x ( i ) x^{(i)} x(i)为第i个样本,是一个列向量, h θ ( x ( i ) ) h_{\theta} (x^{(i)}) hθ(x(i))是根据这个样本求得的预测概率值, y ( i ) y^{(i)} y(i)是样本的真实标签, x j ( i ) x_{j}^{(i)} xj(i)是第i个样本的第j个分量。
参考链接:
逻辑回归(logistic regression)的本质——极大似然估计
逻辑回归-爖 (很多精炼的数学推导,值得学习)
周志华. 机器学习 - 清华大学出版社, 2016