C语言memcpy函数的效率问题
为了方便解释,我们首先查看memcpy的源码,版本:glibc-2.8 memcpy.c
#include
#include
#include
#undef memcpy
void *
memcpy (dstpp, srcpp, len)
void *dstpp;
const void *srcpp;
size_t len;
{
unsigned long int dstp = (long int) dstpp;
unsigned long int srcp = (long int) srcpp;
/* Copy from the beginning to the end. */
/* If there not too few bytes to copy, use word copy. */
if (len >= OP_T_THRES) //OP_T_THRES=16
{
/* Copy just a few bytes to make DSTP aligned. */
len -= (-dstp) % OPSIZ; //OPSIZ=sizeof(unsigned long int)=8
BYTE_COPY_FWD (dstp, srcp, (-dstp) % OPSIZ);
/* Copy whole pages from SRCP to DSTP by virtual address manipulation,
as much as possible. */
PAGE_COPY_FWD_MAYBE (dstp, srcp, len, len);
/* Copy from SRCP to DSTP taking advantage of the known alignment of
DSTP. Number of bytes remaining is put in the third argument,
i.e. in LEN. This number may vary from machine to machine. */
WORD_COPY_FWD (dstp, srcp, len, len);
/* Fall out and copy the tail. */
}
/* There are just a few bytes to copy. Use byte memory operations. */
BYTE_COPY_FWD (dstp, srcp, len);
return dstpp;
}
libc_hidden_builtin_def (memcpy)
为了方便理解我画了简单的流程图供参考:
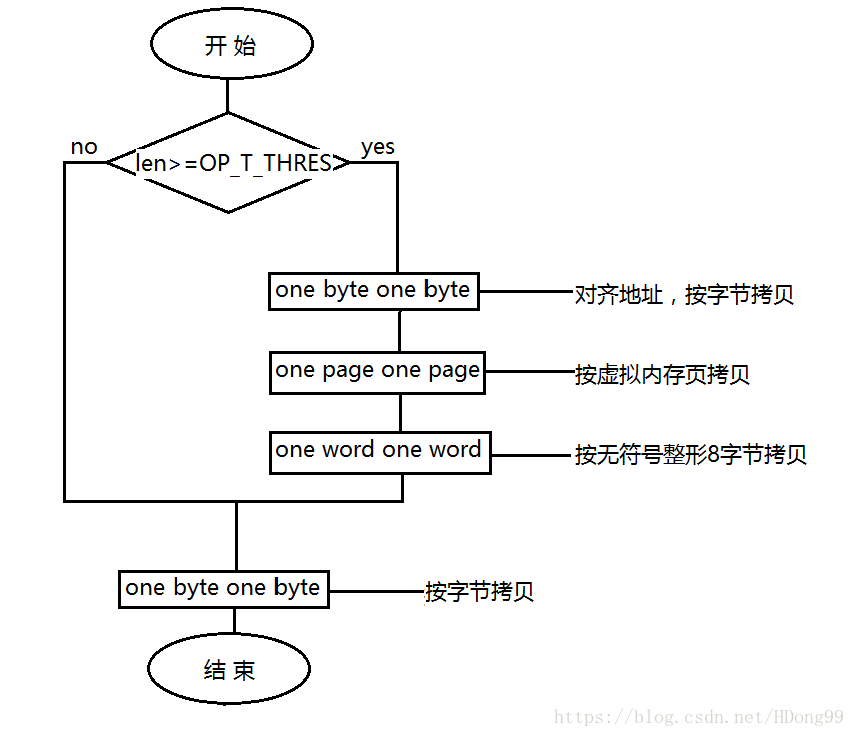
1:地址被转换成unsigned long int保存。
unsigned long int dstp = (long int) dstpp;
unsigned long int srcp = (long int) srcpp;
2:拷贝数量较小,采用 one byte one byte拷贝。
{
unsigned long int dstp = (long int) dstpp;
unsigned long int srcp = (long int) srcpp;if()
{
}
BYTE_COPY_FWD (dstp, srcp, len);return dstpp;
}
如果 len >= OP_T_THRES(OP_T_THRES在不同的系统或者平台有不同的值,通常为16或者8),那就按照if中的结构处理,否则执行BYTE_COPY_FWD (dstp, srcp, len),即按按字节拷贝
3:如果拷贝数量较大,则分情况拷贝
(1)首先内存对齐
len -= (-dstp) % OPSIZ;
BYTE_COPY_FWD (dstp, srcp, (-dstp) % OPSIZ);首先使用字节拷贝,使内存地址对齐,为虚拟内存页拷贝做准备。
(2)按虚拟内存页拷贝
PAGE_COPY_FWD_MAYBE (dstp, srcp, len, len);
加快内存拷贝的效率
(3)按8字节拷贝
WORD_COPY_FWD (dstp, srcp, len, len);
扫除剩余的大块字节
(4)剩余部分退出了if()语句,按照字节拷贝,直至退出函数