HBase HA 高可用集群搭建
导读:
本篇博客主要介绍如何搭建HBase HA 高可用集群,笔者是基于ZooKeeper 的 Hadoop HA 上搭建的,Hadoop HA 高可用集群搭建请参考博客地址:
http://blog.csdn.net/HG_Harvey/article/details/76269561
一、安装前准备
集群主机规划
| IP | 主机名 | 安装软件 | HBase地位 | 进程 |
|---|---|---|---|---|
| 192.168.242.161 | node1 | jdk/hadoop/hbase | 主Master | NameNode、DFSZKFailoverController、ResourceManager、HMaster |
| 192.168.242.162 | node2 | jdk/hadoop/hbase | 备份Master | NameNode、DFSZKFailoverController、ResourceManager、HMaster |
| 192.168.242.163 | node3 | jdk/hadoop/zookeeper/hbase | RegionServer | DataNode、NodeManager、JournalNode、QuorumPeerMain、HRegionServer |
| 192.168.242.164 | node4 | jdk/hadoop/zookeeper/hbase | RegionServer | DataNode、NodeManager、JournalNode、QuorumPeerMain、HRegionServer |
| 192.168.242.165 | node5 | jdk/hadoop/zookeeper/hbase | RegionServer | DataNode、NodeManager、JournalNode、QuorumPeerMain、HRegionServer |
安装前的环境配置,比如:配置主机名,设置IP,创建hadoop用户、SSH无密登录等,笔者在这不做介绍,如有问题请参考博客
http://blog.csdn.net/hg_harvey/article/details/72819007
HBase 官网地址:http://mirror.bit.edu.cn/apache/hbase/
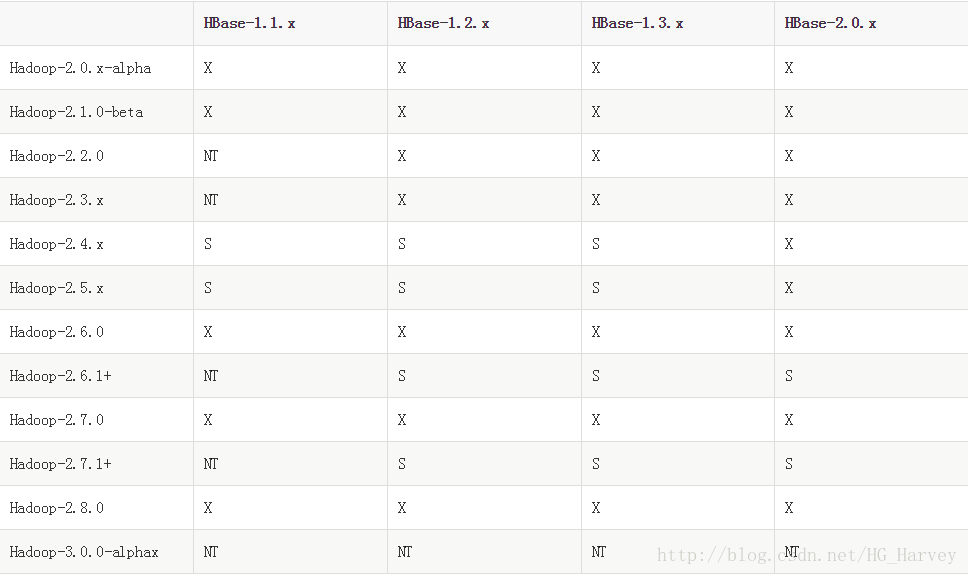
笔者使用的HBase的版本为1.2.6,你也可以使用其它版本,但要注意与hadoop 版本兼容,两者版本关系表如下
● “S” = supported(支持)
● “X” = not supported(不支持)
● “NT” = Not tested(未测试)
二、HBase 安装配置
node1、2、3、4、5分别安装配置HBase,以node1为例,其它相同
将下载的HBase 解压到 hadoop 用户目录下
$ cd /home/hadoop
$ tar -zvxf hbase-1.2.6-bin.tar.gz
$ rm -rf hbase-1.2.6-bin.tar.gz1-配置hbase-env.sh
在配置 hbase-env.sh 前先在 hbase 的安装目录下创建两个文件,如下
$ cd /home/hadoop/hbase-1.2.6/
$ mkdir logs # hbase 的日志目录
$ mkdir pids # hbase 的pids目录编辑 hbase-env.sh 文件,添加如下内容
$ cd conf/
$ vim hbase-env.sh# 配置JDK安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_131
# 配置hadoop安装路径
export HADOOP_HOME=/usr/local/hadoop
# 配置hbase日志目录
export HBASE_LOG_DIR=${HBASE_HOME}/logs
# 设置HBase的pid目录
export HBASE_PID_DIR=${HBASE_HOME}/pids
# 使用独立的zookeeper集群(默认为true,即使用hbase 的内置的zk)
export HBASE_MANAGES_ZK=false注释如下的两行内容(前面加符号‘#)
![]()
可以不注释,注释后在启动hbase时就不会出现如下图红色框中警告信息

2.配置hbase-site.xml
$ vim hbase-site.xml在 configuration 节点中添加如下内容
<property>
<name>hbase.rootdirname>
<value>hdfs://cluster/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.tmp.dirname>
<value>/home/hadoop/hbase-1.2.6/tmpvalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>node3,node4,node5value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/home/hadoop/zookeeper-3.4.9/datavalue>
property>
<property>
<name>zookeeper.session.timeoutname>
<value>120000value>
property>
<property>
<name>hbase.regionserver.restart.on.zk.expirename>
<value>truevalue>
property>3.配置regionservers
写希望运行的全部 Regionserver,一行写一个主机名(和hadoop中的slave文件一样),这里列出的 Server 会随着集群的启动而启动,集群的停止而停止
$ vim regionservers添加如下内容
node3
node4
node5配置完成后,将上述所做的hbase安装文件及配置远程拷贝到其它节点
$ scp -r ~/hbase-1.2.6/ hadoop@node2:~/
$ scp -r ~/hbase-1.2.6/ hadoop@node3:~/
$ scp -r ~/hbase-1.2.6/ hadoop@node4:~/
$ scp -r ~/hbase-1.2.6/ hadoop@node5:~/4.配置环境变量(每个节点)
$ vim ~/bash.rc # 配置的是用户变量jdk、hadoop、zookeeper、hbase 所有环境变量如下
# Java Environment Variable
export JAVA_HOME=/usr/java/jdk1.8.0_131
# Hadoop Environment Variable
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# HBase Environment Variable
export HBASE_HOME=/home/hadoop/hbase-1.2.6
# PATH
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin$ source ~/bash.rc # 使环境变量立即生效三、集群启动关闭
hadoop + zookeeper + hbase 集群启动关闭顺序如下
启动:zookeeper、hadoop、hbase
关闭:hbase、hadoop、zookeeper
1.手动启动关闭集群
启动集群
1).启动zookeeper(node3、node4、node5)
$ zkServer.sh start2).启动journalnode(node3、node4、node5)
$ hadoop-daemon.sh start journalnode3).格式化HDFS(node1)
注意:格式化后需要把tmp目录拷贝给node2,不然node2的namenode启动不起来,第一次启动时需要格式化
$ hdfs namenode -format
$ scp -r /usr/local/hadoop/tmp hadoop@node2:/usr/local/hadoop/4).格式化ZKFC(node1)
注意:第一次启动时需要格式化
$ hdfs zkfc -formatZK5).启动HDFS(node1)
$ start-dfs.sh6).启动YARN(node1)
$ start-yarn.sh7).启动resourcemanager(node2)
node2的resourcemanager需要手动单独启动
$ yarn-daemon.sh start resourcemanager8).启动主HMaster(node1)
注意:启动hbase之前,必须保证hadoop集群和zookeeper集群是可用的
$ start-hbase.sh9).启动备份的HMaster
在任意一台选择一台你想作为备份的HMster中启动,笔者将node2作为备份的HMaster
$ hbase-daemon.sh start master集群在首次启动时麻烦一点,以后再手动启动就不需要格式化hdfs 和 zkfc,之后的启动命令,总结如下
$ zkServer.sh start # node3、node4、node5
$ start-dfs.sh # node1
$ start-yarn.sh # node1
$ yarn-daemon.sh start resourcemanager # node2
$ start-hbase.sh # node1
$ hbase-daemon.sh start master # node2关闭集群
不管是否是第一次,集群的关闭都一样,命令如下
$ hbase-daemon.sh stop master # node2
$ stop-hbase.sh # node1
$ stop-dfs.sh # node1
$ stop-yarn.sh # node1
$ yarn-daemon.sh stop resourcemanager # node2
$ zkServer.sh stop # node3、node4、node52.shell 脚本启动关闭
笔者在之前的博客搭建Hadoop HA高可用集群时,为解决集群启动或关闭写了一个shell 脚本(导读中有博客地址),下面我们也将hbase 也写成加入进入
新建hbase-manage.sh 脚本文件,内容如下
#!/bin/bash
# FileName:hbase-manage.sh
# Description:hbase 集群启动关闭管理脚本
# Author:david
# 主 HMaster
main_hmaster=node1
# 备份 HMaster
bak_hmaster=node2
start_time=`date +%s`
case $1 in
# 先启动主HMaster,再启动备份HMaster
start)
ssh -t $main_hmaster << mhm1
start-hbase.sh
mhm1
ssh -t $bak_hmaster << bhm1
hbase-daemon.sh start master
bhm1
;;
# 先关闭备份HMaster,再关闭主HMaster
stop)
ssh -t $bak_hmaster << bhm2
hbase-daemon.sh stop master
bhm2
ssh -t $main_hmaster << mhm2
stop-hbase.sh
mhm2
;;
*) echo -e "Usage:sh hbase-manage.sh {start|stop} ^_^\n" && exit;;
esac
end_time=`date +%s`
elapse_time=$((${end_time}-${start_time}))
echo -e "\n$1 HBase Server takes ${elapse_time} seconds\n"修改 hadoop-ha-cluster 脚本,在集群启动、关闭、重启中加入hbase
修改前:
case $1 in
# 先启动zk,再启动hadoop
start)
sh zk-manage.sh start
sh hadoop-manage.sh start
;;
# 先关闭hadoop,在关闭zk
stop)
sh hadoop-manage.sh stop
sh zk-manage.sh stop
;;
# 先关闭hadoop,在重启zk,在启动hadoop
restart)
sh hadoop-manage.sh stop
sh zk-manage.sh restart
sh hadoop-manage.sh start
;;
# 显示进程
status)
shouJps
;;
*) echo -e "Usage: sh hadoop-ha-cluster.sh {start|stop|restart|status} ^_^\n" ;;
esac修改后:
case $1 in
# 先启动zk,再启动hadoop,再启动hbase
start)
sh zk-manage.sh start
sh hadoop-manage.sh start
sh hbase-manage.sh start
;;
# 先关闭HBase,再关闭hadoop,再关闭zk,
stop)
sh hbase-manage.sh stop
sh hadoop-manage.sh stop
sh zk-manage.sh stop
;;
restart)
# hadoop 和 zk 和 hbase 重启
sh hadoop-ha-cluster.sh stop
sh hadoop-ha-cluster.sh start
;;
# 显示进程
status)
showJps
;;
*) echo -e "Usage: sh hadoop-ha-cluster.sh {start|stop|restart|status} ^_^\n" ;;
esac使用脚本
$ sh hadoop-ha-cluster.sh start # 启动集群
$ sh hadoop-ha-cluster.sh stop # 关闭集群
$ sh hadoop-ha-cluster.sh restart # 重启集群
$ sh hadoop-ha-cluster.sh status # 查看每个节点上的进程四、测试
启动成功后,输入命令 jps 查看进程,如果和主机规划中的一致则成功,反之失败。如下
***********************************************************
当前 node1 上的进程为:
2804 DFSZKFailoverController
2503 NameNode
4263 Jps
2923 ResourceManager
3182 HMaster
***********************************************************
当前 node2 上的进程为:
2587 ResourceManager
2460 DFSZKFailoverController
2860 HMaster
4220 Jps
2381 NameNode
***********************************************************
当前 node3 上的进程为:
2388 QuorumPeerMain
2516 JournalNode
2622 NodeManager
3118 Jps
2447 DataNode
***********************************************************
当前 node4 上的进程为:
2354 QuorumPeerMain
2419 DataNode
2599 NodeManager
2488 JournalNode
3356 Jps
2799 HRegionServer
***********************************************************
当前 node5 上的进程为:
2784 HRegionServer
2582 NodeManager
2410 DataNode
3389 Jps
2351 QuorumPeerMain
2479 JournalNode
status Hadoop HA Cluster Server takes 9 seconds使用如下命令进入hbase 的shell 客户端对hbase进行操作,后续博客中会有详细介绍
$ hbase shell # 进入hbase 的 shell 客户端
$ quit # 退出,或使用exit
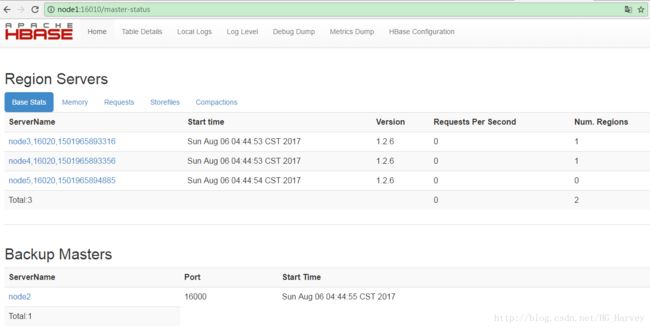
访问 web ui 页面查看hbase相关信息(http://node1:16010)
五、常见问题解决
1.替换hadoop及zookeeper jar
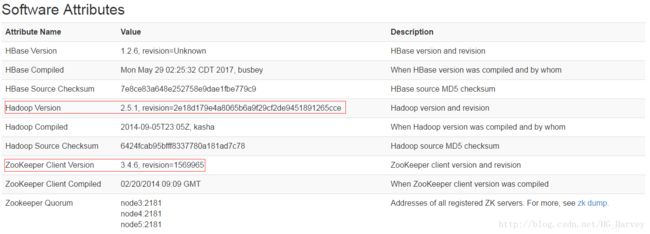
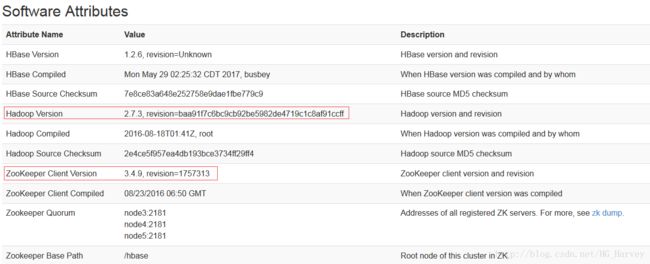
启动成功后,访问web ui 可以看到 hbase 的相关信息,如下图笔者安装的是 hadoop 2.7.3 ,zookeeper 3.4.9 ,而在hbase中使用的hadoop version 是2.5.1,zookeeper version 是3.4.6,为了保持版本一致,所以将hadoop和zookeeper的替换为我们安装的版本
hbase 依赖的 hadoop 及 zookeeper jar如下,在lib目录下
$ cd /home/hadoop/hbase-1.2.6/lib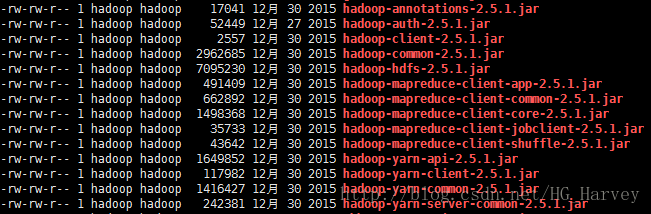
![]()
执行如下命令替换 hadoop 和 zookeeper 的 jar
$ cd /home/hadoop/hbase-1.2.6/lib/
$ mkdir jar_bak
$ mv hadoop*.jar /home/hadoop/hbase-1.2.6/lib/jar_bak/ # 备份hadoop jar
$ find /usr/local/hadoop/share/hadoop/ -name "hadoop-annotations-2.7.3.jar" | xargs -i cp {} /home/hadoop/hbase-1.2.6/lib/ # 从hadoop安装目录下查询相关2.7.3版本的jar依次拷贝到hbase的lib目录下
$ mv zookeeper-3.4.6.jar zookeeper-3.4.6.jar.bak # 备份zookeeper jar
$ cp /home/hadoop/zookeeper-3.4.9/zookeeper-3.4.9.jar /home/hadoop/hbase-1.2.6/lib/注意:在hadoop中的安装目录下并没有找到hadoop-client-2.7.3.jar,笔者是专门去下载后,然后做的替换
替换后再次访问 hbase 的web ui
2.hbase 与 hadoop jar 冲突
运行 hbase客户端,出现如下警告信息

移除hbase里的 slf4j-log4j12-1.7.5.jar 即可
$ cd /home/hadoop/hbase-1.2.6/lib/
$ mv slf4j-log4j12-1.7.5.jar slf4j-log4j12-1.7.5.jar.bak