GridFS:基于MongoDB的分布式文件存储系统
基本原理
GridFS是MongoDB之上的分布式文件系统,其利用了MongoDB的分布式存储机制并通过MongoDB来存储文件数据和文件元数据,兼具文档型数据库和文件系统的优势。GridFS是当前大数据潮流和复杂数据分析需求的产物。
简单地来说,GridFS通过将文件数据和文件元数据保存在MongoDB里来实现文件系统,通过复制(Replication)来应对故障切换、数据集成,还可以用来做读扩展、热备份或者作为离线批处理的数据源,通过分片来实现自动切分数据,实现大数据存储和负载均衡,通过数据库对集合中文档的管理和查询(包括MapReduce)实现轻量级文件系统接口和搜索与分析。
GridFS的一个基本思想就是可以将大文件分成很多块,每一块作为一个单独的文档存储,这样就能存储大文件了。由于MongoDB支持在文档中存储二进制数据,可以最大限度减小块的存储开销。GridFS使用MongoDB的复制、分片等机制来实现分布式文件存储,使用MongoDB进行管理和复杂分析。
GridFS使用两个文档来存储文件,一个用来存储文件本身的块,另外一个用来存储分块的信息和文件的元数据,默认对应的集合分别为fs.chunks和fs.files。
chunks集合:
{
"_id" : 块集合中文档包含以下属性: chunks._id: 块ID。 chunks.files_id: 对应files集合中文档的_id。 chunks.n: 块的编号,由GridFS管理,从0开始。 chunks.data: 文件数据,是 BSON二进制类型。
chunks集合使用files_id 和 n作为混合索引。 files集合:
{
"_id" : <ObjectID>,
"length" : files集合中的文档包含以下属性,应用还可以创建额外任意的属性: files._id: 唯一的文件标识,MongoDB的默认值是BSON ObjectID。 files.length: 文件的字节数大小。 files.chunkSize: 每个块的大小,默认为256KB,GridFS根据这个值将文件分成多个块。 files.uploadDate: GridFS第一次存储此文件的时间,类型为ISODate。 files.md5: 文件的md5散列值,是字符串。 files.filename: 可选。人类可读的文件名。 files.contentType: 可选。合法的文件MIME类型。 files.aliases: 可选。别名的字符串数组。 files.metadata: 可选。自定义存储的文件元数据。
可以通过mongofiles工具或者MongoDB驱动程序来使用GridFS。GridFS主要提供5种操作接口:
list: 获取文件列表
get: 获取文件
put: 写入文件
search: 根据文件名搜索文件
delete: 删除文件主要技术和架构
(1)复制
分布式存储系统一个关键的功能就是复制(Replication),通过复制来应对故障切换、数据集成,还可以用来做读扩展、热备份或者作为离线批处理的数据源。总的来说,MongoDB的复制至少需要两个服务器或者节点。其中一个是注解点,负责处理客户端请求,其他的都是从节点,负责映射主节点的数据。主节点记录在其上执行的所有操作。从节点定期轮询主节点获得这些操作,然后对自己的数据副本执行这些操作。由于和主节点执行了相同的操作,从节点就能保持与主节点的数据同步。
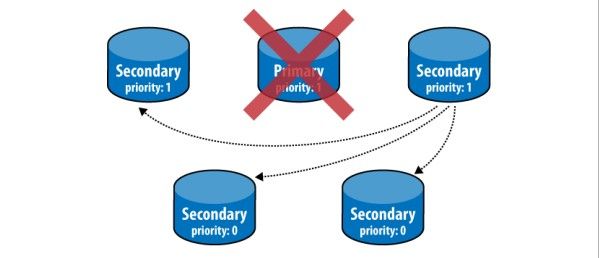
主节点的操作记录被称为oplog,其存储在一个特殊的数据库中,叫做local。oplog就在其中的oplog.$main集合里面。oplog中的每一个文档都代表主节点上执行的一个操作。文档包含的键如下:
ts: 操作的时间戳。时间戳是一种内部类型,用以跟踪操作执行的时间。由4字节的时间戳和4字节的递增计数器构成。
op: 操作类型,只有1字节代码。
ns: 执行操作的命名空间(集合名)。
o: 进一步指定要执行的操作的文档。对插入来说,就是要插入的文档。 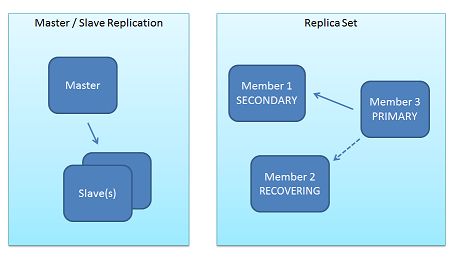
MongoDB有两种复制方式,分别为主从复制和副本集。主从复制是最常用的方式,基本的设置方式就是建立一个主节点和一个或多个从节点,每个从节点要知道主节点的地址。所有的从节点都从主节点复制内容。目前还没有能够从从节点复制的机制(菊花链),原因就是从节点并不保存自己的oplog。副本集中的活跃节点对应主节点,当活跃节点故障时,新的活跃节点由副本集中的大多数选举产生。
从节点的主要作用是作为故障恢复机制,以防主节点数据丢失或者停止服务;其他用途包括:将查询放在从节点上、用从节点做数据处理——以减轻主节点负载、提高系统性能。
(2)分片
分片(Sharding)是指将数据拆分,将其分散存放在不同的机器上的过程。将数据分散到不同机器上,不需要功能强大的大型计算机就可以存储更多的数据,处理更大的负载。MongoDB支持自动分片,可以摆脱手动分片的管理困扰。集群自动切分数据,做负载均衡。MongoDB分片的基本思想就是将集合切分成小块。这些块分散到若干片里面,每个片只负责总数据的一部分。应用程序不必知道哪片对应哪些数据,甚至不需要知道数据已经被拆分了,所以在分片之前要运行一个路由进程,该进程为mongos。这个路由器知道所有数据的存放位置,所以应用可以连接它来正常发送请求。对应用来说,它仅知道连接了一个普通的mongod,也就是说分片对于应用来说是透明的。路由器知道数据和片的对应关系,能够转发请求到正确的片上。如果请求有了回应,路由器将其手机起来回送给应用。
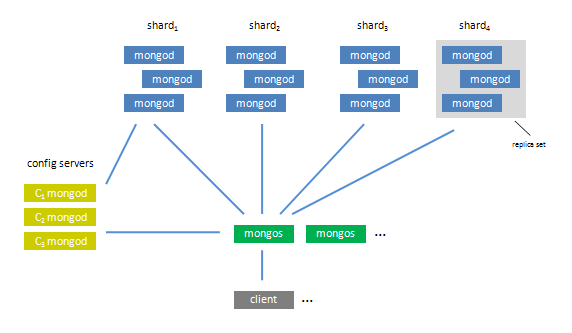
设置分片时,需要从集合里面选一个键,用该键的值作为数据划分的依据。这个键称为片键,片键的选择决定了插入操作在片之间的分布。不论片键随机跳跃还是稳定增加,片键的变化至关重要。
(3)查询和聚合
因为GridFS文件的元数据存储在files集合中,因此GridFS可以非常方便地进行文件管理,比如根据文件名、上传时间、文件大小或者自定义的文件元数据进行查询,还可以利用MapReduce做复杂数据分析。这是GridFS把传统文件系统和数据库相结合得到的众多好处之一。
对比传统文件系统的优势
分布式:GridFS是基于MongoDB的分布式文件系统,可以直接使用MongoDB Replication和Sharding机制,数据可靠性和水平扩展性都得到保证。GridFS不产生磁盘碎片,因为MongoDB分配数据文件空间时以2GB为一块。
MapReduce: 可以进行复杂管理和查询分析。
索引和缓存:元数据存储在MongoDB中,非常方便索引。并且可以对文件和文件元数据进行索引,能提高系统效率。
checksum:GridFS会为文件产生散列值,可用于校验文件以检查完整性。
开发者友好: 利用Grid可以简化需求,减小开发成本。要是已经用了MongoDB,GridFS就可以不需要使用独立文件存储架构,并且使代码和数据真正分离,方便管理(尤其是对云计算平台)。
其他:GridFS可以避免用于存储用户上传内容的文件系统出现的某些问题。例如,GridFS在同一个目录下放置大量的文件是没有任何问题的。GridFS不产生磁盘碎片,因为MongoDB分配数据文件空间时以2GB为一块。
小结
MongoDB是一个优秀的分布式基于文档的NoSQL数据库,正是基于MongoDB,GridFS才能将数据库与文件系统完美地结合在一起,兼具二者的优势。使用GridFS,开发者能在不怎么损失性能的情况下对系统进行扩展,并且极大地减小了开发成本和系统维护成本。可以预计,GridFS或者类似的分布式文件系统在未来一定会得到广泛地应用。事实上,以CloudFoundry为代表的云平台已经把MongoDB作为首选的数据库和文件管理系统了。
转自:http://creatist.cn/blog/201301/gridfs/