Spark基础之--启动local与standalone模式
我们得到编译好的spark压缩包之后,进行解压;随后进入spark文件夹,获取到spark的路径:
/home/xxx/app/spark-2.1.0-bin-2.6.0-cdh5.7.0为了后续使用方便,我建议将spark的路径添加到本地配置(~/.bash_profile)
export SPARK_HOME=/home/xxx/app/spark-2.1.0-bin-2.6.0-cdh5.7.0
export PATH=$SPARK_HOME/bin:$PATH然后使配置文件生效
source ~/.bash_profile再后直接打开spark即可进入spark的local模式
spark-shell --master local[2]
spark-shell 是“spark-2.1.0-bin-2.6.0-cdh5.7.0/bin”目录下的命令
--master 表示启动
local[x] 表示本地启动x个进程进入后结果如下:
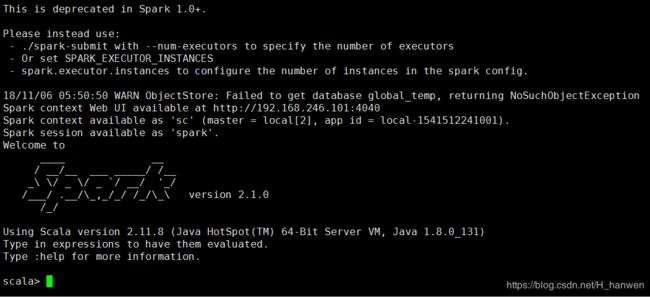
且可以通过web界面进行查看
http://hadoop01:4040若是没有将spark命令加入配置文件,那么进入目录“spark-2.1.0-bin-2.6.0-cdh5.7.0/bin”下直接执行上述命令也可以。
进入成功后可以随便写一下scala代码以验证,退出与查看帮助命令如下:
:help 查看帮助命令
:quit 退出界面
以上则为spark的local模式启动与退出
-----------------------------------------------------------华丽的分割线-----------------------------------------------------------
以下进行spark的standalone模式的启动
首先启动spark的standalone模式之前需要修改部分文件
1.修改conf目录下的“spark-env.sh”文件
SPARK_MASTER_HOST=hadoop01
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_INSTANCES=1
SPARK_MASTER_HOST master运行的机器,可以写hostname,也可以写ip地址
SPARK_WORKER_CORES 核心数
SPARK_WORKER_MEMORY 内存大小
SPARK_WORKER_INSTANCES worker的数量2.建议到sbin目录下修改文件“spark-config.sh”,添上Java的路径
不然后面可能会报错
JAVA_HOME is not set
3.启动spark服务(到sbin目录下):
./start-all.sh然后会打印两份日志文件:

这两份日志分别是master和worker的日志存储路径,查看后找到spark的web界面:
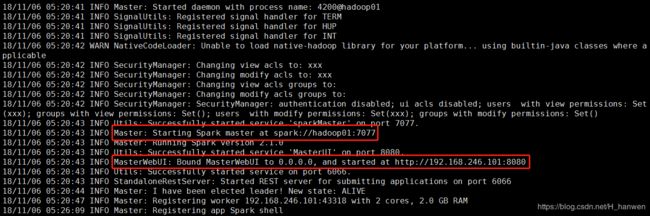
其中
Master: Starting Spark master at spark://hadoop01:7077
--表示master运行的机器,后面启动任务会用到
MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://192.168.246.101:8080
--WebUI则表示在web界面查看spark打开web界面可以看到workers,cores,memory均是我们之前在“spark-env.sh”中配置的信息

随后打开spark客户端,与之前的本地模式没有区别:
spark-shell --master spark://hadoop01:7077
这里的spark路径既可以在log日志中查看,也可以在之前的Web页面查看到随后可以在web页面查看到具体的信息,当再开一个窗口时,web页面也会发生相应的转变,具体情况可以自己查看~