0692-5.16.1-外部客户端跨网段访问Hadoop集群方式(续)
Fayson的github: https://github.com/fayson/cdhproject
推荐关注微信公众号:“Hadoop实操”,ID:gh_c4c535955d0f
1 文档编写目的
在生产环境的CDH集群中,为了分开集群对网络的使用会为集群配备两套网络(管理网段和数据网段),数据网段主要用于集群内部数据交换,一般使用万兆网络以确保集群内数据传输性能,管理网段主要用于集群管理,一般使用千兆网络。一般情况下在集群外进行集群管理和数据传输的都是通过千兆网络进行交互,在集群外是无法直接访问集群内的万兆网络。
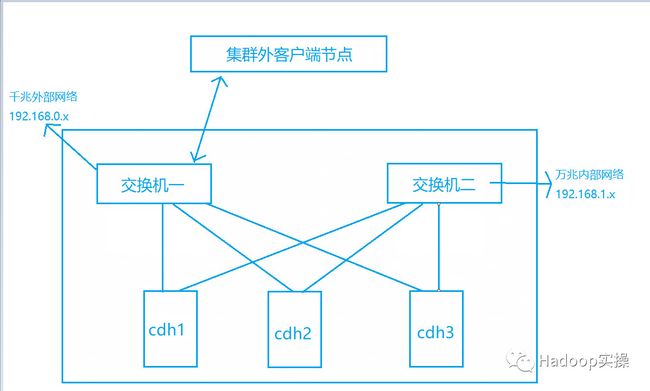
Hadoop集群使用192.168.1.x万兆网段:

在这样复杂的网络环境下,如何在集群外通过千兆网络访问集群并向Hadoop集群读写数据。Fayson在前面的文章《如何在集群外节点跨网段向HDFS写数据》介绍了基于RSET API的方式跨网段访问Hadoop集群。接下来本篇文章会详细的介绍三种方式访问Hadoop集群。
内容概述
1.使用WebHDFS访问HDFS
2.使用NFS Gateway方式
3.修改Gateway配置参数
测试环境
1.CM和CDH版本未5.16.1
2.集群未启用安全
3.OS的版本为RedHat7.2
4.使用root用户进行操作
2 修改HDFS配置
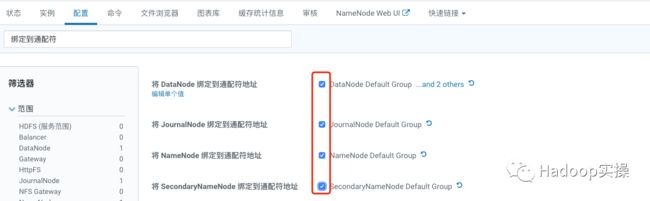
HDFS服务的各个角色端口号默认绑定的是/etc/hosts配置文件中对应的IP地址,为了能够在集群外通过千兆网络访问Hadoop集群,首先需要通过CM界面来修改HDFS各个服务端口号绑定的IP地址为0.0.0.0(即服务启动时端口会绑定到当前服务器的所有IP上),如下为修改方式:
1.登录CM进入HDFS服务的配置页面,搜索“绑定到通配符”并勾选如下选项
2.保存配置后重启HDFS服务,然后在命令行查看端口绑定情况
![]()
3 WebHDFS RSET API方式
WebHDFS是内置在HDFS中的,不需要进行额外的安装以及启动,提供了RESTful接口来操作HDFS,下面使用Java代码通过WebHDFS API来操作HDFS,具体实现方式如下:
1.在执行代码的本地机器上配置hosts映射外网的IP

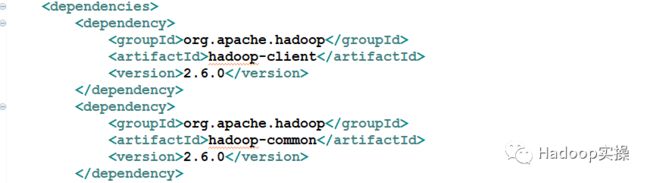
2.在工程的pom.xml配置文件中添加如下依赖
org.apache.hadoop
hadoop-client
2.6.0
org.apache.hadoop
hadoop-common
2.6.0
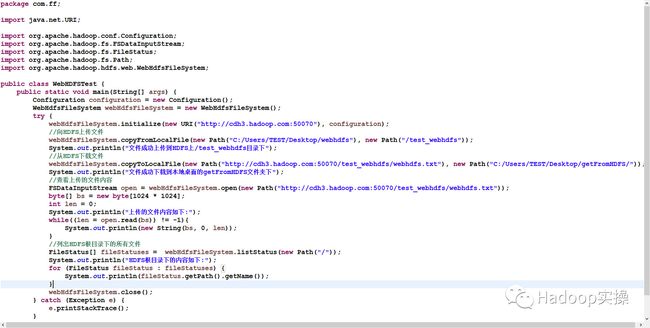
3.编写Java示例代码
package com.ff;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.web.WebHdfsFileSystem;
public class WebHDFSTest {
public static void main(String[] args) {
Configuration configuration = new Configuration();
WebHdfsFileSystem webHdfsFileSystem = new WebHdfsFileSystem();
try {
webHdfsFileSystem.initialize(new URI("http://cdh3.hadoop.com:50070"), configuration);
//向HDFS上传文件
webHdfsFileSystem.copyFromLocalFile(new Path("C:/Users/TEST/Desktop/webhdfs"), new Path("/test_webhdfs"));
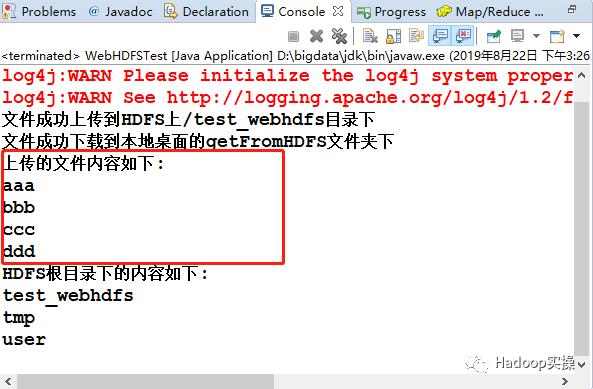
System.out.println("文件成功上传到HDFS上/test_webhdfs目录下");
//从HDFS下载文件
webHdfsFileSystem.copyToLocalFile(new Path("http://cdh3.hadoop.com:50070/test_webhdfs/webhdfs.txt"), new Path("C:/Users/TEST/Desktop/getFromHDFS/"));
System.out.println("文件成功下载到本地桌面的getFromHDFS文件夹下");
//查看上传的文件内容
FSDataInputStream open = webHdfsFileSystem.open(new Path("http://cdh3.hadoop.com:50070/test_webhdfs/webhdfs.txt"));
byte[] bs = new byte[1024 * 1024];
int len = 0;
System.out.println("上传的文件内容如下:");
while((len = open.read(bs)) != -1){
System.out.println(new String(bs, 0, len));
}
//列出HDFS根目录下的所有文件
FileStatus[] fileStatuses = webHdfsFileSystem.listStatus(new Path("/"));
System.out.println("HDFS根目录下的内容如下:");
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath().getName());
}
webHdfsFileSystem.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
4.执行代码前查看HDFS上的目录结构以及待上传的文件

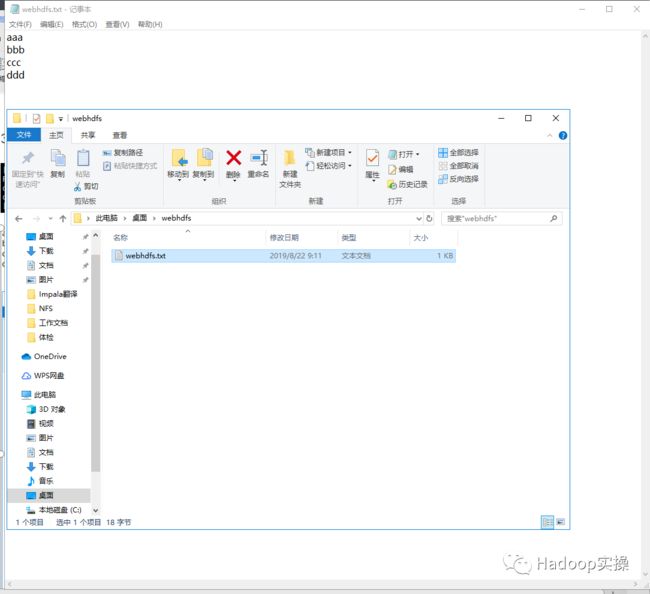
5.执行Java代码
查看上传的文件成功,内容与本地文件一致
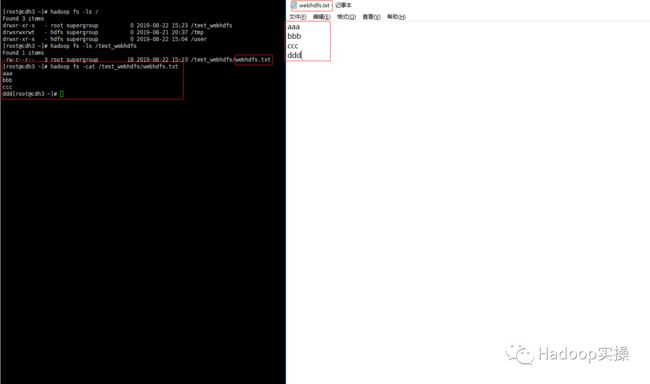
查看下载的文件,文件下载成功,且内容与HDFS上一致
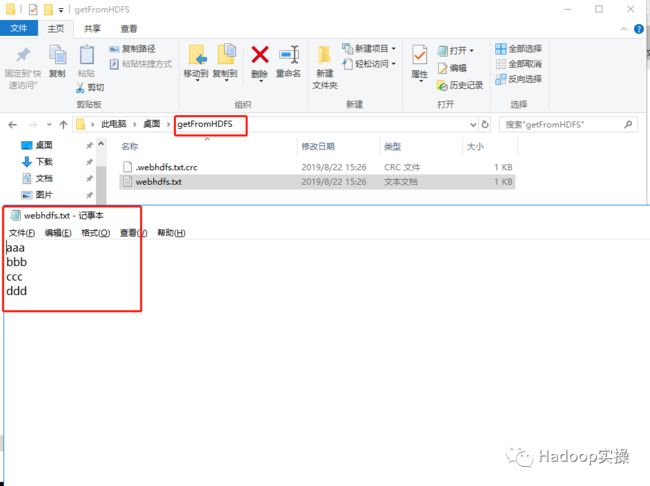
在代码控制台打印的文件内容也与上传的文件一致
4 NFS Gateway方式
首先在HDFS的实例列表中添加NFS Gateway服务,NFS Gateway允许客户端将HDFS文件系统作为本地文件系统的一部分进行挂载。将HDFS挂载到本地文件系统后,可以执行下列操作:
-
查看HDFS文件系统,和查看本地文件系统的操作一致。
-
可以向HDFS上传文件以及从HDFS上下载文件到本地文件系统。
-
通过挂载点将数据直接传输到HDFS。
-
支持文件追加,但不支持随机写入。
1.在安装NFS Gateway的节点上执行如下命令安装OS依赖服务(本文档选择安装在cdh2节点)
yum -y install nfs-utils
yum -y install rpcbind

启动rpcbind服务并添加到系统自启动列表
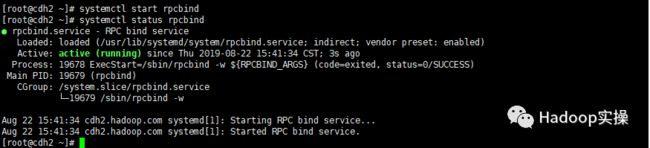
systemctl start rpcbind
systemctl status rpcbind
systemctl enable rpcbind
停止系统自带的nfs服务

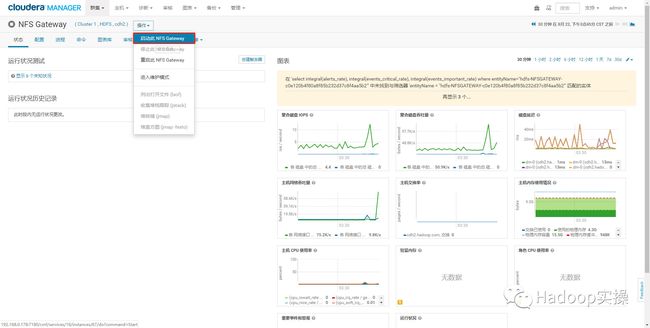
2.通过CM添加NFS Gateway角色实例
选择一个cdh2节点
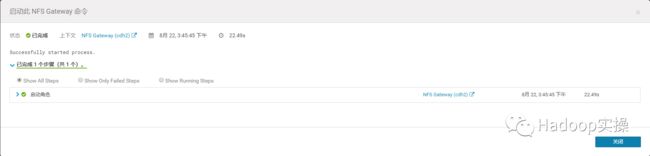
启动NFS Gateway
启动成功
3.在集群外客户端节点配置hosts文件(注意:hosts文件的IP为千兆网段IP地址

4.验证NFS Gateway是否正常运行,正常运行的结果类似下图:

验证是否挂载HDFS,应该能看到类似下图的结果:
![]()
5.在命令行执行如下命令,创建挂载点并将HDFS挂载到本地目录
mkdir /nfs
mount -t nfs -o vers=3,proto=tcp,nolock,noacl,sync cdh2.hadoop.com:/ /nfs

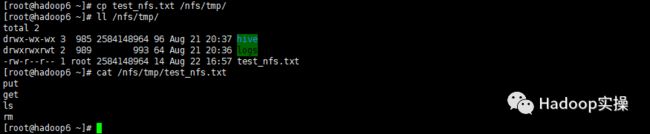
6.测试上传文件、查看文件以及删除文件
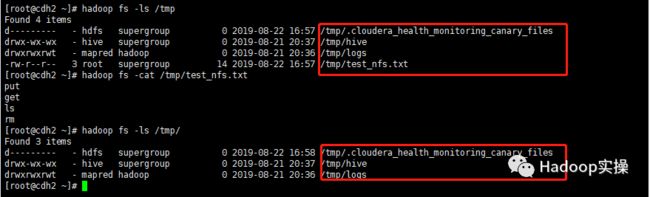
在外部客户端节点上传文件
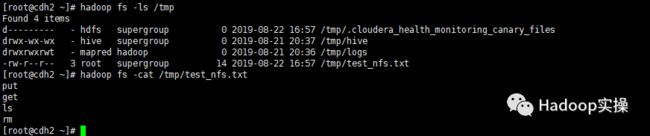
在HDFS NFS Gateway节点查看上传的文件
在外部客户端节点删除文件

在HDFS NFS Gateway节点删除文件
5 修改Gateway配置参数
1.修改Gateway配置参数前查看hadoop命令使用集群内网IP连接HDFS
在命令行设置日志打印级别
export HADOOP_ROOT_LOGGER=DEBUG,console
![]()
查看访问Datanode的方式,是用的集群内配置的hosts的IP访问的

2.修改集群外客户端节点的/etc/hadoop/conf/hdfs-site.xml配置文件,添加如下配置
dfs.client.use.datanode.hostname
true
![]()
该配置表示外部客户端访问Datanode的时候是通过主机名访问,这样就解决了NameNode返回Datanode的内网IP地址给外部客户端节点,导致外部客户端节点上传文件失败的问题,配置该参数后,在外部客户端节点的hosts文件配置好外网和IP的映射,即可解决问题。
3.执行hadoop命令向集群put数据成功且使用的为hostname访问集群50010端口


查看访问Datanode的方式,以主机名的方式访问,而不是IP

6 总结
1.由于在集群外只有192.168.0.*网段才可以访问到HDFS,所以需要确保HDFS服务(NameNode、DataNode等)绑定到通配符地址,否则会导致192.168.0.*网段无法访问HDFS服务。
2.以上三种方式访问HDFS均需要在本地配置hosts文件且IP地址为Hadoop集群的192.168.0.*网段IP。
3.使用NFS Gateway方式需要安装NFS Gateway服务并启动,在需要访问HDFS的客户端节点,执行挂载命令将HDFS文件系统挂载到本地即可。
4.相较于前两种方式通过修改Gateway客户端配置文件的方式最为简单,只需要在客户端节点的配置文件中增加dfs.client.use.datanode.hostname参数为true即可解决问题。