ISLR第五章-重采样方法
5 重采样方法
In this chapter, we discuss two of the most commonly used resampling methods, cross-validation(交叉验证) and the bootstrap(自助法).
The process
of evaluating a model’s performance is known as model assessment(模型评估), whereas
the process of selecting the proper level of flexibility for a model is known as
model selection(模型选择).
5.1 Cross-Validation
In this section, we instead consider a class of methods that estimate the
test error rate by holding out a subset of the training observations from the
fitting process, and then applying the statistical learning method to those
held out observations.
5.1.1 The Validation Set Approach
随机分为两部分
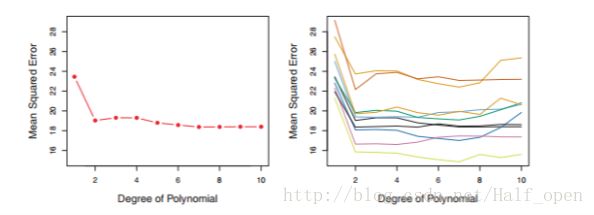
从左图可以看出,当由1次变为2次时,均方差减少明显,之后次数再增加均方差减少不明显,甚至还有上升。
从右图可以看出,不同验证集的选择对均方差影响很大。
优点:原理简单,便于实施
缺点:
- 由于验证集选择的不同,测试错误率的波动很大
- 只有一部分数据被用于训练拟合模型,测试错误率可能被高估
5.1.2 Leave-One-Out Cross-Validation(LOOCV)

n个测试数据,取其中一个当验证集,剩下的n-1做为训练集。
最多可重复拟合模型n次。
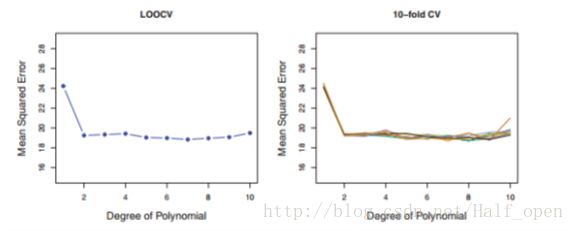
克服了The Validation Set Approach的缺点,但这个方法计算量很大。
用最小二乘法来拟合模型时,LOOCV所用时间可以缩减到和只拟合一个模型相同??
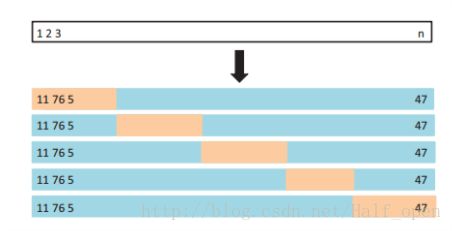
5.1.3 k-Fold Cross-Validation
把观测集随机分成大小差不多一致的组,取一组做为验证集。LOOCV是k=n时的一个特例。
LOOCV has higher variance, but lower bias, than k-fold CV
5.2 The Bootstrap
The bootstrap is a widely applicable and extremely powerful statistical tool that can be used to quantify the uncertainty associated with a given estimator or statistical learning method.
我的理解是有放回地随机抽样。比如1,2,3要抽出5个样本可以是1 2 2 3 3,抽出三个可以是1 2 2。
这里举了一个例子,对两个收益分别为X和Y的资产进行投资,X占 α ,Y占 1−α ,所以我们希望找出一个 α ,使得 Var(αX+(1−α)Y) 最小。这个 α 值为
其中, σ2Y=Var(Y),σ2X=Var(X),σXY=Cor(X,Y)
证明过程如下:
f(α)=Var(αX+(1−α)Y)
=Var(αX)+Var((1−α)Y)+2Cor(αX,(1−α)Y)
=α2Var(X)+(1−α)2Var(Y)+2α(1−α)Cov(X,Y)
=σ2Xα2+σ2Y(1−α)2+2σXY(−α2+α)
求导可得
0=df(α)dα
0=2σ2Xα−2σ2Y(1−α)+2σXY(−2α+1)
0=σ2Xα−σ2Y(1−α)+σXY(−2α+1)
0=(σ2X+σ2Y−2σXY)α−σ2Y+σXY
α=σ2Y−σXYσ2X+σ2Y−2σXY
5.3 实验
5.3.1 The Validation Set Approach
library(ISLR )
set.seed(1)
train = sample(392,196) # 产生0-392范围内,196个数据
lm.fit = lm(mpg~horsepower, data=Auto, subset = train)
attach(Auto) # 把mpg变量加入当前环境
#mpg
mean ((mpg-predict(lm.fit ,Auto))[- train ]^2)
#[1] 26.14142
lm.fit2=lm(mpg~poly( horsepower ,2) ,data=Auto , subset =train )
mean ((mpg - predict (lm.fit2 ,Auto ))[- train ]^2)
#[1] 19.82259
lm.fit3=lm(mpg~poly( horsepower ,3) ,data=Auto , subset =train )
mean ((mpg - predict (lm.fit3 ,Auto ))[- train ]^2)
#[1] 19.78252
#更改随机种子,重新进行实验,会得到不同的结果
set.seed(2)
train = sample(392,196)
lm.fit = lm(mpg~horsepower, data=Auto, subset = train)
attach(Auto)
mean ((mpg-predict(lm.fit ,Auto))[- train ]^2)
#[1] 23.29559
lm.fit2=lm(mpg~poly( horsepower ,2) ,data=Auto , subset =train )
mean ((mpg - predict (lm.fit2 ,Auto ))[- train ]^2)
#[1] 18.90124
lm.fit3=lm(mpg~poly( horsepower ,3) ,data=Auto , subset =train )
mean ((mpg - predict (lm.fit3 ,Auto ))[- train ]^2)
#[1] 19.2574
5.3.2 Leave-One-Out Cross-Validation
library(boot)
glm.fit = glm(mpg~horsepower, data=Auto)
cv.err = cv.glm(Auto, glm.fit)
cv.err$delta
#[1] 24.23151 24.23114
cv.error = rep(0,5) # 生成一个长度为5,全为0的数组
# 这个循环需要运行一段时间
for(i in 1:5)
{
glm.fit = glm(mpg~poly(horsepower,i), data=Auto)
cv.error[i]=cv.glm(Auto, glm.fit)$delta[1]
}
cv.error
#[1] 24.23151 19.24821 19.33498 19.42443 19.033215.3.3 k-Fold Cross-Validation
library(ISLR)
library(boot)
set.seed(17)
cv.error.10 = rep(0,10)
for(i in 1:10){
glm.fit = glm(mpg~poly(horsepower,i), data=Auto)
# 根据经验,k取10或者5
cv.error.10[i]=cv.glm(Auto, glm.fit, K=10)$delta[1]
}
cv.error.10
# [1] 24.20520 19.18924 19.30662 19.33799 18.87911 19.02103 18.89609 19.71201 18.95140 19.501965.3.4 The Bootstrap
Estimating the Accuracy of a Statistic of Interest
#在R语言中使用自助法有两个步骤
#一、创建一个感兴趣统计量的函数
#二、使用用boot库中的boot函数
## 功能:计算alhpa
# data: 数据
# index: 数据位置
# 返回:alpha值
alpha.fn= function (data , index ){
X= data$X [ index ]
Y= data$Y [ index ]
return (( var (Y)-cov (X,Y))/( var (X)+ var (Y) -2* cov (X,Y)))
}
alpha.fn( Portfolio ,1:100)
#[1] 0.5758321
set.seed (1)
alpha.fn( Portfolio,sample (100 ,100 , replace =T))
#[1] 0.5963833
boot(Portfolio , alpha.fn ,R =1000)
# ORDINARY NONPARAMETRIC BOOTSTRAP
#
#
# Call:
# boot(data = Portfolio, statistic = alpha.fn, R = 1000)
#
#
# Bootstrap Statistics :
# original bias std. error
# t1* 0.5758321 -7.315422e-05 0.08861826
Estimating the Accuracy of a Linear Regression Model
library(boot)
boot.fn= function (data ,index )
return (coef(lm(mpg~horsepower , data=data , subset = index )))
boot.fn(Auto ,1:392)
# (Intercept) horsepower
# 39.9358610 -0.1578447
set.seed (1)
boot.fn(Auto ,sample (392 ,392 , replace =T))
# (Intercept) horsepower
# 38.7387134 -0.1481952
boot.fn(Auto ,sample (392 ,392 , replace =T))
# (Intercept) horsepower
# 40.0383086 -0.1596104
boot(Auto ,boot.fn ,1000)
# ORDINARY NONPARAMETRIC BOOTSTRAP
#
#
# Call:
# boot(data = Auto, statistic = boot.fn, R = 1000)
#
#
# Bootstrap Statistics :
# original bias std. error
# t1* 39.9358610 0.02972191 0.860007896
# t2* -0.1578447 -0.00030823 0.007404467
summary (lm(mpg~horsepower ,data =Auto))$coef
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 39.9358610 0.717498656 55.65984 1.220362e-187
# horsepower -0.1578447 0.006445501 -24.48914 7.031989e-81
boot.fn= function (data ,index )
coefficients(lm(mpg~horsepower +I( horsepower ^2) ,data=data ,subset = index ))
set.seed (1)
boot(Auto ,boot.fn ,1000)
# ORDINARY NONPARAMETRIC BOOTSTRAP
#
#
# Call:
# boot(data = Auto, statistic = boot.fn, R = 1000)
#
#
# Bootstrap Statistics :
# original bias std. error
# t1* 56.900099702 6.098115e-03 2.0944855842
# t2* -0.466189630 -1.777108e-04 0.0334123802
# t3* 0.001230536 1.324315e-06 0.0001208339
summary (lm(mpg~horsepower +I( horsepower ^2) ,data= Auto)) $coef
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 56.900099702 1.8004268063 31.60367 1.740911e-109
# horsepower -0.466189630 0.0311246171 -14.97816 2.289429e-40
# I(horsepower^2) 0.001230536 0.0001220759 10.08009 2.196340e-21相关链接
交叉验证(简单交叉验证、k折交叉验证、留一法)http://www.cnblogs.com/boat-lee/p/5503036.html