白话Spark——Executor模块与RDD详解
Executor模块
了解DAGScheduler,TaskScheduler,SchedulerBackend模块的实现机制后
https://blog.csdn.net/handoking/article/details/81122877
按照spark的运行逻辑,应该了解一下executor工作节点中运算单元的机制。简单说就是以下几个过程:
1.appclient的创建
Appclient是用户应用Application与Master的交互借口,Master是指资源管理器。Appclient可以完成很多操作,比如注册应用,删除应用,增加executor,更新executor的状态等。Appclient是由SchedulerBackend创建的,Appclient向Master进行Application的注册,然后Master根据Application中的信息为它分配Worker。
2.Application注册过程
Appclient向Master发起注册请求,超过20秒没有收到注册成功就会重新发送注册请求,超过三次那么这个注册就失败了,但正常情况下,只要Master是健康的,注册就会成功的。Master收到注册申请后,将application的信息持久化存储在Master的数据结构中。
3.分配worker
Master根据提交的application的信息,来为application分配资源worker。分配有两种策略,一是尽量打散,就是将application分配到尽量多的节点上,这个适合大的应用,占用内存大,这样分散能提高效率。另一种是尽量集中,就是把application集中分配到一些节点上,这种适合CPU密集且内存占用较小的应用。根据这两种策略选择好worker以及CPU的数目后,Master会调用launchExecutor向worker发送请求,来增加executor,减少CPU和memory数目等操作。
4.创建Executor
worker收到了lanchExecutor,创建方法ExecutorRunner,ExecutorRunner启动后和Driver进行通信,向Driver注册Executor。Driver收到注册信息后将Executor的信息保存到本地,新建的Executor,在Executor上启动Task。
5.Task执行
Driver发出Task时对Task进行包装,将Task以及依赖信息一起打包封装。executor恢复task以及其依赖信息,下载好依赖后就可以执行Task了。Task的运行应该分两种情况,因为在划分阶段时提到会产生两种stage,这两种stage中不同的任务属性,最后一个阶段中的ResultTask和其他阶段中的ShuffleMapTask。
RDD机制
1.RDD是什么
这个定义我看了几本书一堆博客后觉得这样写会更好理解也更贴切:RDD(弹性分布式数据集)提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改。每个RDD可以分成多个分区,每个分区就是一个数据集片段。简单说,RDD就是一种数据抽象。
2.怎么创建RDD
可以用内存中已经有的数据集,也可以用外部数据源。之后通过RDD的转换,从父RDD中衍生出新的RDD,并生成依赖(就是和父RDD的血缘关系),一旦丢失便于结合父RDD和依赖信息恢复数据集。
3.什么是RDD转换
RDD创建后就可以在RDD上进行数据处理了。RDD有种操作一个是转换(transformation)一个是动作(action)。RDD转换是通过用户提交的应用程序来不断衍生出需要的RDD,并同时产生依赖信息。衍生的过程就是转换,之所以叫转换是因为这个过程中不涉及计算,只是记录了转换的轨迹(就是依赖信息),只有当动作执行时才会真正的进行转换。这样做是避免了将大量数据返回给控制点Driver,而只是返回了最后的结果,大大提高了效率。

下面这张图就很好的说明了转换过程是惰性的,只有当RDDF输出时才会完成动作,转换完成,在动作之前所有的RDD转换都是逻辑上的,转换完成后就生成了如下的DAG。转换和动作都有一些函数可以选择,比如说map就是一个转换的函数,reduce就是一个动作函数,还有一些其他的函数,根据用户应用程序调用。
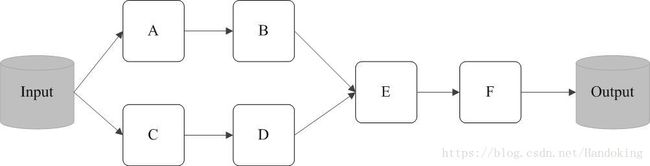
4.什么是RDD缓存
缓存是Spark构建迭代式算法和快速交互式查询的关键,也是Spark速度非常快的原因之一(基于内存的运算速度是hadoop mapreduce的100倍,基于硬盘10倍以上 )。简单说就是一些关键的重复利用率高的数据实现内存持久化或者缓存,会使后续的重用数据的速度提高10倍以上。RDD本来就是数据集,所以RDD持久化和RDD缓存后,每一个节点都将计算的分片结果保存在内存中或者缓存中。这样避免了需要利用此RDD时重复转换,从而提高速度。提到分片(patition),其实RDD中是一组分片,是数据集的基本组成单位,可以理解为分区存储。由于分区存储可以映射工作节点中不同的block,每个block被一个task负责计算,这样实现并行运算。
5.RDD的计算
RDD经过一系列转换,在最后的RDD上执行一个动作,这个动作会提交一个job,job会生成一批task,通过工作点中executor执行计算。Spark的任务分为两种:ResultTask和ShuffleMapTask。DAG的最后阶段每一个分片都会产生一个ResultTask,其余所有阶段都产生ShuffleMapTask,这些task都将送给executor来执行计算。