spark实现詞频分析WordCount(python)
spark的安装配置见上一篇博文。
1.在spark的home目录下新建文件夹
/usr/local/spark/mycode/wordcount #分别建mycode与wordcount2.在wordcount中新建程序test.py以及需要分析的文件word.txt
如word.txt内容为:
When you are old and grey and full of sleep
And nodding by the fire, take down this book
And slowly read, and dream of the soft look
Your eyes had once, and of their shadows deep
How many loved your moments of glad grace
And loved your beauty with love false or true为了使用HDFS中的文件,在HDFS中新建文件夹并把spark目录下的word.txt放在HDFS上。
cd /usr/local/hadoop
./sbin/start-dfs.sh #启动HDFS分布式文件系统./bin/hdfs dfs -mkdir -p /user/hadoop #在HDFS上新建文件夹/user/hadoop,
此处的hadoop是我的用户名。因为文件系统默认创建文件夹的方式就是/user/用户名./bin/hdfs dfs -put /usr/local/spark/mycode/wordcount/word.txt .
#第一个点代表相对路径,命令在/usr/local/hadoop文件夹下运行,
最后一个点等价于/user/hadoop。
#这条命令将spark目录下的word.txt放在HDFS上在wordcount中新建程序test.py,程序如下
from pyspark import SparkContext
sc = SparkContext( 'local', 'test')
textFile = sc.textFile("word.txt")#从HDFS上读取文件,也可以用HDFS中的详细路径"/user/hadoop/word.txt"代替"word.txt"
###textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt")#或者从spark目录下直接读取
wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word,1)).reduceByKey(lambda a, b : a + b)
wordCount.foreach(print)保存程序。
运行spark程序;
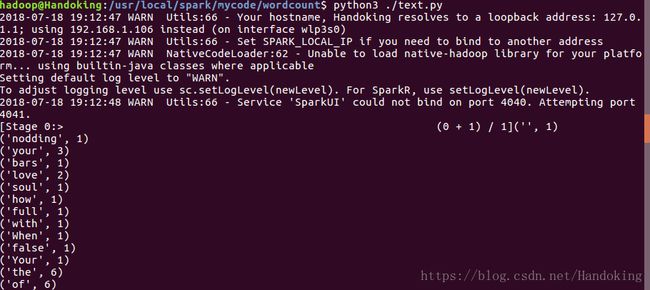
在程序当前的目录下执行python3 ./test.py,截图中程序我随机命名为text.py。