LSGAN (Least Squares Generative Adversarial Networks)
Paper: https://arxiv.org/pdf/1611.04076.pdf
Github:
https://github.com/Hansry/PyTorch-GAN
1.前言
传统GAN出现的问题: 传统GAN, 将Discriminator当作分类器,最后一层使用Sigmoid函数,使用交叉熵函数作为代价函数,容易出现梯度消失和collapse mode等问题,具体原因参考本博客Wasserstein GAN。
LSGAN主要解决关键: 使用最小二乘损失代替交叉熵损失,解决了传统GAN生成的图片质量不高以及训练过程不稳定这俩个缺陷。
为什么使用最小二乘法能够改善传统GAN存在的问题?
1.避免梯度消失
文章指出,传统的GAN在使用生成的“fake”图片(已被Discriminator分类为正样本) 来更新Generator的参数的时候,会造成梯度消失,尽管该生成的"fake"图片数据离真实样本的数据还有一定的距离。当使用最小二乘来作为Discriminator的代价函数的时候,最小二乘会将生成的“fake”图片拉向决策边界,这里的决策边界穿过真实样本,可以使得LSGANs生成的图片更接近真实的数据。如文章中下图所示:
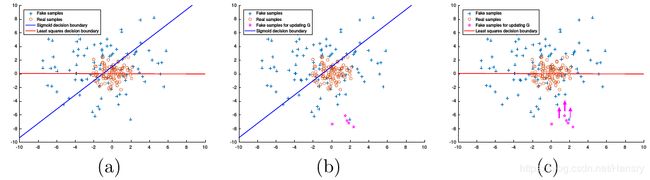
俩种不同损失函数的区别:(a)上图蓝色线代表交叉熵代价函数的Sigmoid决策边界,红色线代表最小二乘的决策边界。值得注意的是,对于成功的GANs学习过程,决策边界应该穿过真实样本分布,除非学习过程已经饱和了。(b)对于Sigmoid 交叉熵损失函数,当生成的“fake”图片被归类在决策边界正确的一边的时候(correct side),得到的误差非差小以至于不能更新Generator,尽管这些数据离决策边界很远,也即离真实样本很远。©最小二乘损失函数会惩罚离决策边界很远的数据,使之朝着决策边界迈进,避免了梯度消失。
2.使训练过程更加稳定
由于GANs学习过程不稳定导致GANs训练困难。特别的,对于传统的由于其存在梯度消失的问题,所以很难更新Generator,造成训练困难。而LSGANs基于离边界的距离而对生成的样本进行惩罚,一定程度上避免了梯度消失,减缓了训练困难的问题。
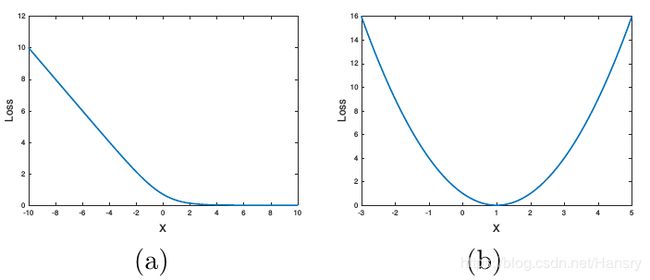
上图中,(a) 为Sigmoid交叉熵损失函数; (b)为最小二乘损失函数
文章的贡献:
- 提出最小二乘损失函数,在最小化LSGAN目标函数的时候也在最小化皮尔森 χ 2 \chi ^ { 2 } χ2散度(Pearson χ 2 \chi ^ { 2 } χ2 散度)。
- 设计了俩种LSGANs, 其中一个用于图片生成(112x112分别率),可生成高质量的图片。另一网络用于多类别任务,文章使用了中国字作为测试。
2. 传统的GAN
GAN的学习过程即同时训练Discriminator (D)和Generator (G)的过程,G从高斯分布的变量 z z z, 学习潜在变量 θ g \theta _ { g } θg,来产生分布 p g p_{g} pg,使得该分布与真实分布越接近越好。因此,G学习的是一个映射过程,通过 G ( z ; θ g ) G \left( \boldsymbol { z } ; \theta _ { g } \right) G(z;θg)变量映射空间来产生分布。另一方方面,D是一个分类器,来判断G产生的分布是否与真实样本接近,通过变量空间 D ( x ; θ d ) D \left( \boldsymbol { x } ; \theta _ { d } \right) D(x;θd)判断是否一样,同样的也是一个映射。传统GAN的代价函数如下:
min G max D V G A N ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min _ { G } \max _ { D } V _ { \mathrm { GAN } } ( D , G ) = \mathbb { E } _ { \boldsymbol { x } \sim p _ { data } ( \boldsymbol { x } ) } [ \log D ( \boldsymbol { x } ) ] + \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } [ \log ( 1 - D ( G ( \boldsymbol { z } ) ) ) ] minGmaxDVGAN(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))] (公式1)
这里稍微解释下:
- 整个式子由两项构成。 x x x表示真实图片, z z z表示输入 G G G网络的噪声或者高斯分布数据,而 G ( z ) G(z) G(z)表示 G G G网络生成的图片。
- D ( x ) D(x) D(x)表示 D D D网络判断真实图片是否真实的概率(因为 x x x就是真实的,所以对于 D D D来说,这个值越接近1越好)。而 D ( G ( z ) ) D(G(z)) D(G(z))是 D D D网络判断 G G G生成的图片的是否真实的概率。
- G G G的目的: D ( G ( z ) ) D(G(z)) D(G(z))是 D D D网络判断 G G G生成的图片是否真实的概率, G G G应该希望自己生成的图片“越接近真实越好”。也就是说, G G G希望 D ( G ( z ) ) D(G(z)) D(G(z))尽可能得大,这时 V ( D , G ) V(D, G) V(D,G)会变小。因此我们看到式子的最前面的记号是 m i n G min_G minG。
- D D D的目的: D D D的能力越强, D ( x ) D(x) D(x)应该越大, D ( G ( x ) ) D(G(x)) D(G(x))应该越小。这时 V ( D , G ) V(D,G) V(D,G)会变大。因此式子对于 D D D来说是求最大(max_D)
3. Least Squares Generative Adversarial Networks
LSGANs在Discriminator上使用a-b编码策略,简单来说就是用a来代表“fake”数据,用b来代表“real”数据。LSGANs的目标函数为:
min D V L S G A N ( D ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − b ) 2 ] + 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − a ) 2 ] \min _ { D } V _ { \mathrm { LSGAN } } ( D ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { x } \sim p _ { \mathrm { data } } ( \boldsymbol { x } ) } \left[ ( D ( \boldsymbol { x } ) - b ) ^ { 2 } \right] + \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) - a ) ^ { 2 } \right] minDVLSGAN(D)=21Ex∼pdata(x)[(D(x)−b)2]+21Ez∼pz(z)[(D(G(z))−a)2]
min G V L S G A N ( G ) = 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − c ) 2 ] \min _ { G } V _ { \mathrm { LSGAN } } ( G ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) - c ) ^ { 2 } \right] minGVLSGAN(G)=21Ez∼pz(z)[(D(G(z))−c)2] (公式2)
其中c代表生成器为了让判断器认为生成的数据是真实分布数据而定的值。在文章中作者设置 a = c = 1 , c = 0 a=c=1, c=0 a=c=1,c=0。
同时在文章中,作者列出了传统的GAN其实在优化的是JS散度,具体参考Wasserstein GAN,
C ( G ) = K L ( p d a t a ∥ p d a t a + p g 2 ) + K L ( p g ∥ p d a t a + p g 2 ) − log ( 4 ) C ( G ) = K L \left( p _ {data} \| \frac { p _ {data} + p _ { g } } { 2 } \right) + K L \left( p _ { g } \| \frac { p _ {data} + p _ { g } } { 2 } \right) - \log ( 4 ) C(G)=KL(pdata∥2pdata+pg)+KL(pg∥2pdata+pg)−log(4) (公式3)
化为JS散度为 2 J S ( P d a t a ∥ P g ) − 2 log 2 2 J S \left( P _ {data } \| P _ { g } \right) - 2 \log 2 2JS(Pdata∥Pg)−2log2
因此当俩个分布没有重叠或者重叠部分可忽略的时候, J S ( P d a t a ∥ P g ) = 0 J S \left( P _ {data } \| P _ { g } \right)=0 JS(Pdata∥Pg)=0, 因此此时的梯度就变为0了。
因此,对于作者提出的LSGANs, 研究了LSGANs损失函数和f散度 (f-divergence)之间的联系:
min D V L S G A N ( D ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − b ) 2 ] + 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − a ) 2 ] \min _ { D } V _ { \mathrm { LSGAN } } ( D ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { x } \sim p _ { \mathrm { data } } ( \boldsymbol { x } ) } \left[ ( D ( \boldsymbol { x } ) - b ) ^ { 2 } \right] + \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) - a ) ^ { 2 } \right] minDVLSGAN(D)=21Ex∼pdata(x)[(D(x)−b)2]+21Ez∼pz(z)[(D(G(z))−a)2]
min G V L S G A N ( G ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − c ) 2 ] + 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − c ) 2 ] \min _ { G } V _ { \mathrm { LSGAN } } ( G ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { x } \sim p _ { \mathrm { data } } ( \boldsymbol { x } ) } \left[ ( D ( \boldsymbol { x } ) - c ) ^ { 2 } \right] + \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) - c ) ^ { 2 } \right] minGVLSGAN(G)=21Ex∼pdata(x)[(D(x)−c)2]+21Ez∼pz(z)[(D(G(z))−c)2] 公式(4)
其中在 V L S G A N ( G ) V _ { \mathrm { LSGAN } } ( G ) VLSGAN(G)添加 E x ∼ p d a t a ( x ) [ ( D ( x ) − c ) 2 ] \mathbb { E } _ { \boldsymbol { x } \sim p _ {data } ( \boldsymbol { x } ) } \left[ ( D ( \boldsymbol { x } ) - c ) ^ { 2 } \right] Ex∼pdata(x)[(D(x)−c)2]并不会影响优化过程,因为添加的项没有包含关于G的内容。
对D求导数
D ∗ ( x ) = b p d a t a ( x ) + a p g ( x ) p d a t a ( x ) + p g ( x ) D ^ { * } ( \boldsymbol { x } ) = \frac { b p _ {data} ( \boldsymbol { x } ) + a p _ { g } ( \boldsymbol { x } ) } { p _ {data} ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } D∗(x)=pdata(x)+pg(x)bpdata(x)+apg(x)
因此对于公式4,我们可以得到
2 C ( G ) = E x ∼ p d [ ( D ∗ ( x ) − c ) 2 ] + E x ∼ p g [ ( D ∗ ( x ) − c ) 2 ] 2 C ( G ) = \mathbb { E } _ { \boldsymbol { x } \sim p _ { \mathrm { d } } } \left[ \left( D ^ { * } ( \boldsymbol { x } ) - c \right) ^ { 2 } \right] + \mathbb { E } _ { \boldsymbol { x } \sim p _ { g } } \left[ \left( D ^ { * } ( \boldsymbol { x } ) - c \right) ^ { 2 } \right] 2C(G)=Ex∼pd[(D∗(x)−c)2]+Ex∼pg[(D∗(x)−c)2]
= E x ∼ p d [ ( b p d ( x ) + a p g ( x ) p d ( x ) + p g ( x ) − c ) 2 ] + E x ∼ p g [ ( b p d ( x ) + a p g ( x ) p d ( x ) + p g ( x ) − c ) 2 ] = \mathbb { E } _ { \boldsymbol { x } \sim p _ { \mathrm { d } } } \left[ \left( \frac { b p _ { \mathrm { d } } ( \boldsymbol { x } ) + a p _ { g } ( \boldsymbol { x } ) } { p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } - c \right) ^ { 2 } \right] + \mathbb { E } _ { \boldsymbol { x } \sim p _ { g } } \left[ \left( \frac { b p _ { \mathrm { d } } ( \boldsymbol { x } ) + a p _ { g } ( \boldsymbol { x } ) } { p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } - c \right) ^ { 2 } \right] =Ex∼pd[(pd(x)+pg(x)bpd(x)+apg(x)−c)2]+Ex∼pg[(pd(x)+pg(x)bpd(x)+apg(x)−c)2]
= ∫ X p d ( x ) ( ( b − c ) p d ( x ) + ( a − c ) p g ( x ) p d ( x ) + p g ( x ) ) 2 d x + ∫ X p g ( x ) ( ( b − c ) p d ( x ) + ( a − c ) p g ( x ) p d ( x ) + p g ( x ) ) 2 d x = \int _ { \mathcal { X } } p _ { \mathrm { d } } ( \boldsymbol { x } ) \left( \frac { ( b - c ) p _ { \mathrm { d } } ( \boldsymbol { x } ) + ( a - c ) p _ { g } ( \boldsymbol { x } ) } { p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } \right) ^ { 2 } \mathrm { d } x + \int _ { \mathcal { X } } p _ { g } ( \boldsymbol { x } ) \left( \frac { ( b - c ) p _ { \mathrm { d } } ( \boldsymbol { x } ) + ( a - c ) p _ { g } ( \boldsymbol { x } ) } { p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } \right) ^ { 2 } \mathrm { d } x =∫Xpd(x)(pd(x)+pg(x)(b−c)pd(x)+(a−c)pg(x))2dx+∫Xpg(x)(pd(x)+pg(x)(b−c)pd(x)+(a−c)pg(x))2dx
= ∫ X ( ( b − c ) p d ( x ) + ( a − c ) p g ( x ) ) 2 p d ( x ) + p g ( x ) d x = \int _ { \mathcal { X } } \frac { \left( ( b - c ) p _ { \mathrm { d } } ( \boldsymbol { x } ) + ( a - c ) p _ { g } ( \boldsymbol { x } ) \right) ^ { 2 } } { p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } \mathrm { d } x =∫Xpd(x)+pg(x)((b−c)pd(x)+(a−c)pg(x))2dx
= ∫ X ( ( b − c ) ( p d ( x ) + p g ( x ) ) − ( b − a ) p g ( x ) ) 2 p d ( x ) + p g ( x ) d x = \int _ { \mathcal { X } } \frac { \left( ( b - c ) \left( p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) \right) - ( b - a ) p _ { g } ( \boldsymbol { x } ) \right) ^ { 2 } } { p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } \mathrm { d } x =∫Xpd(x)+pg(x)((b−c)(pd(x)+pg(x))−(b−a)pg(x))2dx (公式6)
这是在Discriminator达到最优的时候,Generator的损失函数,如果设 b − c = 1 b-c=1 b−c=1和 b − a = 2 b-a=2 b−a=2的话,有:
2 C ( G ) = ∫ X ( 2 p g ( x ) − ( p d ( x ) + p g ( x ) ) ) 2 p d ( x ) + p g ( x ) d x = χ P e a r s o n 2 ( p d + p g ∥ 2 p g ) \begin{aligned} 2 C ( G ) & = \int _ { \mathcal { X } } \frac { \left( 2 p _ { g } ( \boldsymbol { x } ) - \left( p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) \right) \right) ^ { 2 } } { p _ { \mathrm { d } } ( \boldsymbol { x } ) + p _ { g } ( \boldsymbol { x } ) } \mathrm { d } x \\ & = \chi _ { \mathrm { Pearson } } ^ { 2 } \left( p _ { \mathrm { d } } + p _ { g } \| 2 p _ { g } \right) \end{aligned} 2C(G)=∫Xpd(x)+pg(x)(2pg(x)−(pd(x)+pg(x)))2dx=χPearson2(pd+pg∥2pg)
其中 χ P e a r s o n 2 \chi _ { \mathrm { P } earson} ^ { 2 } χPearson2为Pearson χ 2 \chi ^ { 2 } χ2 divergence(皮尔森散度),因此在最优化D的情况下将优化变为了Pearson χ 2 \chi ^ { 2 } χ2 divergence,避免了使用JS散度下造成的梯度为0,其中需要满足b-c=1 且b-a=2。
4. 搭建的网络
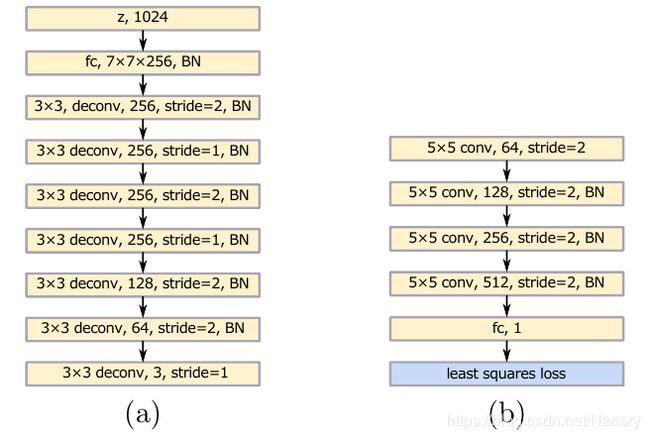
俩种参数的选择:
min D V L S G A N ( D ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − 1 ) 2 ] + 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) + 1 ) 2 ] \min _ { D } V _ { \mathrm { LSGAN } } ( D ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { x } \sim p _ { \mathrm { data } } ( \boldsymbol { x } ) } \left[ ( D ( \boldsymbol { x } ) - 1 ) ^ { 2 } \right] + \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) + 1 ) ^ { 2 } \right] minDVLSGAN(D)=21Ex∼pdata(x)[(D(x)−1)2]+21Ez∼pz(z)[(D(G(z))+1)2]
min G V L S G A N ( G ) = 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) ) 2 ] \min _ { G } V _ { \mathrm { LSGAN } } ( G ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) ) ^ { 2 } \right] minGVLSGAN(G)=21Ez∼pz(z)[(D(G(z)))2] (公式8)
和
min D V L S G A N ( D ) = 1 2 E x ∼ p d a t a ( x ) [ ( D ( x ) − 1 ) 2 ] + 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) ) 2 ] \min _ { D } V _ { \mathrm { LSGAN } } ( D ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { x } \sim p _ { \mathrm { data } } ( \boldsymbol { x } ) } \left[ ( D ( \boldsymbol { x } ) - 1 ) ^ { 2 } \right] + \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) ) ^ { 2 } \right] minDVLSGAN(D)=21Ex∼pdata(x)[(D(x)−1)2]+21Ez∼pz(z)[(D(G(z)))2]
min G V L S G A N ( G ) = 1 2 E z ∼ p z ( z ) [ ( D ( G ( z ) ) − 1 ) 2 ] \min _ { G } V _ { \mathrm { LSGAN } } ( G ) = \frac { 1 } { 2 } \mathbb { E } _ { \boldsymbol { z } \sim p _ { \boldsymbol { z } } ( \boldsymbol { z } ) } \left[ ( D ( G ( \boldsymbol { z } ) ) - 1 ) ^ { 2 } \right] minGVLSGAN(G)=21Ez∼pz(z)[(D(G(z))−1)2] (公式9)
但是作者在文章又提了,这俩种参数在实践中的性能基本一样。
具体实验结果可看原文Least Squares Generative Adversarial Networks