[深度学习论文笔记][Attention]Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention
1 Motivation
In the previous image captioning model, the RNN decoder part only looks at the whole image once. Besides, the CNN encoder part encode fc7 representations which distill information in image down to the most salient objects.
features) can help preserve this information. However working with these features necessitates a attention mechanism to learn to fix its gaze on salient objects while generating the corresponding words in the output sequence to release computational burden. Another usage of attention model is the ability to visualize what the model “sees”.
dynamically come to the forefront as needed. This is especially important when there is a lot of clutter in an image.
See Fig. Where ⃗ z is the context vector, capturing the visual information associated with attention. L represents possible locations (conv4/conv5 different grid cells in our
case), each of which is a D dimensional embedding vector. The distribution over L locations satisfy
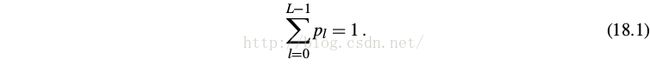
Note that p ⃗ is the a ⃗ used in the Fig.
![[深度学习论文笔记][Attention]Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention_第1张图片](http://img.e-com-net.com/image/info8/4c4f4aa875b346dba012f55b14935a05.jpg)
3 Hard Attention
Each time, z is taken from one location of a .![]()
![]()
Because of the arg max, ∂ ∂⃗ p ⃗ z is zero almost everywhere since slightly change p ⃗ will not affect l⋆ . Therefore, it can not be trained using SGD. We use reinforcement learning instead.
4 Soft Attention
Each time, z is the summarization of all locations
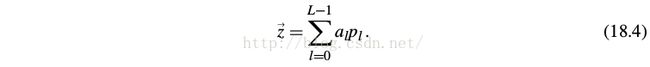
This form is easy to take derivative, so it can be trained with SGD.
5 Doublely Stochastic Attention
Besides ![]() , we also encourage
, we also encourage![]() . This can be interpreted as encouraging the model to pay equal attention to every part of the image over the course of
. This can be interpreted as encouraging the model to pay equal attention to every part of the image over the course of
generation. In practice, we found that this regularization leads to more rich and descriptive captions.
6 Results
See Fig. The model can attend to “non object” salient regions.
![[深度学习论文笔记][Attention]Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention_第2张图片](http://img.e-com-net.com/image/info8/42d8549f8b6d4adfaba4f4327a94f37f.jpg)