python3 ORM重难点
转自灯塔水母 » Python 编写ORM时的重难点掌握
其中夹杂了一些自己的一些理解,可以结合这个看会更好,讲解aiomysql的,特别好点击打开链接
前言:
最近才狠下心来 准备做一个自己的博客 原先FuckBlog项目由于后端小伙伴加班而搁置,因此 作为团队PM的我自己也要开始做技术方面了,准备自己先写一个博客看看。
备注- ORM全称:object related mapping 对象关系映射
0x00 为什么需要写一个ORM
首先,我觉得数据库操作不封装是很傻比的。原来我写了一个数据库导入工具,全篇导出都是sql语句 什么增删改查都他妈齐活的在各个py里面跑来跑去。给大家上一张图:
大家体会到这种乱跑的辛酸了么 从那次失败的架构我就说:再不用orm我他妈就是一傻逼
其次就是不安全,我这里再给大家举一个反例 使我们FuckBlog项目里面 后端小伙伴采用了一个异常简单的后台模板 我在查看代码的时候 发现了问题 我们看用户验证的代码:

看到了么 传输的用户名密码 居然是直接放进sql语句拼接的。大家知道怎么构造 password来达到我们想要的任意用户名都可以登录的效果了么 有几个月了 我简单说一下思路 首先引号闭合 闭合之后 然后在+ or +构造万能查询语句 只要能查询成功,就到让session进行赋值。
最后呢 就是在web中 因为:
一处异步调用 处处异步调用
我们在查询数据库中肯定不能因为数据量过大而放弃其他的请求 这样效率非常慢所以这方面的控制 以及上文所述的问题 需要我们去封装 而方便我们的调用和请求。因此我们需要自己写一个orm工具类 去完成异步的增删改查
0x01 ORM 编写的一些难点
我跟着廖雪峰大神的博客 来学习 期间也看了不少人的跑通代码 自己的疑问点期初看的时候也很多当然 自己慢慢一点一点啃 啃几天就会发现豁然开朗。
代码加上测试一共三百多行,非常简洁,当然我估计注释就能占到八九十行,包括别人的也包括自己第一篇学习的困惑和不了解。也算是比较实用吧。 我先贴我第一版学习跑通的代码 然后呢 我会慢慢在后面进行阐述。
import sys
import asyncio
import logging
logging.basicConfig(level=logging.INFO)
# 一次使用异步 处处使用异步
import aiomysql
def log(sql,args=()):
logging.info('SQL:%s' %sql)
@asyncio.coroutine
def create_pool(loop, **kw): #这里的**kw是一个dict
logging.info(' start creating database connection pool')
global __pool
# 理解这里的yield from 是很重要的
#dict有一个get方法,如果dict中有对应的value值,则返回对应于key的value值,否则返回默认值,例如下面的host,如果dict里面没有
#'host',则返回后面的默认值,也就是'localhost'
#这里有一个关于Pool的连接,讲了一些Pool的知识点,挺不错的,点击打开链接,下面这些参数都会讲到,以及destroy__pool里面的
#wait_closed()
__pool=yield from aiomysql.create_pool(
host=kw.get('host','localhost'),
port=kw.get('port',3306),
user=kw['user'],
password=kw['password'],
db=kw['db'],
charset=kw.get('charset','utf8'),
autocommit=kw.get('autocommit',True), #默认自动提交事务,不用手动去提交事务
maxsize=kw.get('maxsize',10),
minsize=kw.get('minsize',1),
loop=loop
)
@asyncio.coroutine
def destroy_pool():
global __pool
if __pool is not None :
__pool.close() #关闭进程池,The method is not a coroutine,就是说close()不是一个协程,所有不用yield from
yield from __pool.wait_closed() #但是wait_close()是一个协程,所以要用yield from,到底哪些函数是协程,上面Pool的链接中都有
# 我很好奇为啥不用commit 事务不用提交么?我觉得是因为上面再创建进程池的时候,有一个参数autocommit=kw.get('autocommit',True)
# 意思是默认会自动提交事务
@asyncio.coroutine
def select(sql, args, size=None):
log(sql,args)
global __pool
# 666 建立游标
# -*- yield from 将会调用一个子协程,并直接返回调用的结果
# yield from从连接池中返回一个连接, 这个地方已经创建了进程池并和进程池连接了,进程池的创建被封装到了create_pool(loop, **kw)
with (yield from __pool) as conn: #使用该语句的前提是已经创建了进程池,因为这句话是在函数定义里面,所以可以这样用
cur = yield from conn.cursor(aiomysql.DictCursor) #A cursor which returns results as a dictionary.
yield from cur.execute(sql.replace('?', '%s'), args)
if size:
rs = yield from cur.fetchmany(size) #一次性返回size条查询结果,结果是一个list,里面是tuple
else:
rs = yield from cur.fetchall() #一次性返回所有的查询结果
yield from cur.close() #关闭游标,不用手动关闭conn,因为是在with语句里面,会自动关闭,因为是select,所以不需要提交事务(commit)
logging.info('rows have returned %s' %len(rs))
return rs #返回查询结果,元素是tuple的list
# 封装INSERT, UPDATE, DELETE
# 语句操作参数一样,所以定义一个通用的执行函数,只是操作参数一样,但是语句的格式不一样
# 返回操作影响的行号
# 我想说的是 知道影响行号有个叼用
@asyncio.coroutine
def execute(sql,args, autocommit=True):
log(sql)
global __pool
with (yield from __pool) as conn:
try:
# 因为execute类型sql操作返回结果只有行号,不需要dict
cur = yield from conn.cursor()
# 顺便说一下 后面的args 别掉了 掉了是无论如何都插入不了数据的
yield from cur.execute(sql.replace('?', '%s'), args)
yield from conn.commit() #这里为什么还要手动提交数据
affected_line=cur.rowcount
yield from cur.close()
print('execute : ', affected_line)
except BaseException as e:
raise
return affected_line
# 这个函数主要是把查询字段计数 替换成sql识别的?
# 比如说:insert into `User` (`password`, `email`, `name`, `id`) values (?,?,?,?) 看到了么 后面这四个问号
def create_args_string(num):
lol=[]
for n in range(num):
lol.append('?')
return (','.join(lol))
# 定义Field类,负责保存(数据库)表的字段名和字段类型
class Field(object):
# 表的字段包含名字、类型、是否为表的主键和默认值
def __init__(self, name, column_type, primary__key, default):
self.name = name
self.column_type=column_type
self.primary_key=primary__key
self.default=default
def __str__(self):
# 返回 表名字 字段名 和字段类型
return "<%s , %s , %s>" %(self.__class__.__name__, self.name, self.column_type)
# 定义数据库中五个存储类型
class StringField(Field):
def __init__(self, name=None, primary_key=False, default=None, ddl='varchar(100)'):
super().__init__(name,ddl,primary_key,default)
# 布尔类型不可以作为主键
class BooleanField(Field):
def __init__(self, name=None, default=False):
super().__init__(name,'Boolean',False, default)
# 不知道这个column type是否可以自己定义 先自己定义看一下
class IntegerField(Field):
def __init__(self, name=None, primary_key=False, default=0):
super().__init__(name, 'int', primary_key, default)
class FloatField(Field):
def __init__(self, name=None, primary_key=False,default=0.0):
super().__init__(name, 'float', primary_key, default)
class TextField(Field):
def __init__(self, name=None, default=None):
super().__init__(name,'text',False, default)
# class Model(dict,metaclass=ModelMetaclass):
# -*-定义Model的元类
# 所有的元类都继承自type
# ModelMetaclass元类定义了所有Model基类(继承ModelMetaclass)的子类实现的操作
# -*-ModelMetaclass的工作主要是为一个数据库表映射成一个封装的类做准备:
# ***读取具体子类(user)的映射信息
# 创造类的时候,排除对Model类的修改
# 在当前类中查找所有的类属性(attrs),如果找到Field属性,就将其保存到__mappings__的dict中,同时从类属性中删除Field(防止实例属性遮住类的同名属性)
# 将数据库表名保存到__table__中
# 完成这些工作就可以在Model中定义各种数据库的操作方法
# metaclass是类的模板,所以必须从`type`类型派生:
class ModelMetaclass(type):
# __new__控制__init__的执行,所以在其执行之前
# cls:代表要__init__的类,此参数在实例化时由Python解释器自动提供(例如下文的User和Model)
# bases:代表继承父类的集合
# attrs:类的方法集合
def __new__(cls, name, bases, attrs):
# 排除model 是因为要排除对model类的修改
if name=='Model':
return type.__new__(cls, name, bases, attrs)
# 获取table名称 为啥获取table名称 至于在哪里我也是不明白握草
table_name=attrs.get('__table__', None) or name #r如果存在表名,则返回表名,否则返回 name
logging.info('found table: %s (table: %s) ' %(name,table_name ))
# 获取Field所有主键名和Field
mappings=dict()
fields=[] #field保存的是除主键外的属性名
primaryKey=None
# 这个k是表示字段名
for k, v in attrs.items():
if isinstance(v, Field):
logging.info('Found mapping %s===>%s' %(k, v))
# 注意mapping的用法
mappings[k] = v
if v.primary_key:
logging.info('fond primary key %s'%k)
# 这里很有意思 当第一次主键存在primaryKey被赋值 后来如果再出现主键的话就会引发错误
if primaryKey:
raise RuntimeError('Duplicated key for field') #一个表只能有一个主键,当再出现一个主键的时候就报错
primaryKey=k # 也就是说主键只能被设置一次
else:
fields.append(k)
if not primaryKey: #如果主键不存在也将会报错,在这个表中没有找到主键,一个表只能有一个主键,而且必须有一个主键
raise RuntimeError('Primary key not found!')
# w下面位字段从类属性中删除Field 属性
for k in mappings.keys():
attrs.pop(k)
# 保存除主键外的属性为''列表形式
# 将除主键外的其他属性变成`id`, `name`这种形式,关于反引号``的用法,可以参考点击打开链接
escaped_fields=list(map(lambda f:'`%s`' %f, fields))
# 保存属性和列的映射关系
attrs['__mappings__']=mappings
# 保存表名
attrs['__table__']=table_name #这里的tablename并没有转换成反引号的形式
# 保存主键名称
attrs['__primary_key__']=primaryKey
# 保存主键外的属性名
attrs['__fields__']=fields
# 构造默认的增删改查 语句
attrs['__select__']='select `%s`, %s from `%s` '%(primaryKey,', '.join(escaped_fields), table_name)
attrs['__insert__'] = 'insert into `%s` (%s, `%s`) values (%s) ' %(table_name, ', '.join(escaped_fields), primaryKey, create_args_string(len(escaped_fields)+1))
attrs['__update__']='update `%s` set %s where `%s` = ?' % (table_name, ', '.join(map(lambda f:'`%s`=?' % (mappings.get(f).name or f), fields)), primaryKey)
attrs['__delete__']='delete from `%s` where `%s`=?' %(table_name, primaryKey)
return type.__new__(cls, name, bases, attrs)
# 定义ORM所有映射的基类:Model
# Model类的任意子类可以映射一个数据库表
# Model类可以看作是对所有数据库表操作的基本定义的映射
# 基于字典查询形式
# Model从dict继承,拥有字典的所有功能,同时实现特殊方法__getattr__和__setattr__,能够实现属性操作
# 实现数据库操作的所有方法,定义为class方法,所有继承自Model都具有数据库操作方法
class Model(dict,metaclass=ModelMetaclass):
def __init__(self, **kw): #感觉这里去掉__init__的声明也是代码结果是没影响的
super(Model,self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError("'Model' object have no attribution: %s"% key)
def __setattr__(self, key, value):
self[key] =value
def getValue(self, key):
# 这个是默认内置函数实现的
return getattr(self, key, None)
def getValueOrDefault(self, key):
value=getattr(self, key , None)
if value is None:
field = self.__mappings__[key]
if field.default is not None:
value = field.default() if callable(field.default) else field.default
logging.info('using default value for %s : %s ' % (key, str(value)))
setattr(self, key, value)
return value
@classmethod
# 类方法有类变量cls传入,从而可以用cls做一些相关的处理。并且有子类继承时,调用该类方法时,传入的类变量cls是子类,而非父类。
@asyncio.coroutine
def find_all(cls, where=None, args=None, **kw):
sql = [cls.__select__]
if where:
sql.append('where')
sql.append(where)
if args is None:
args = []
orderBy = kw.get('orderBy', None)
if orderBy:
sql.append('order by')
sql.append(orderBy)
# dict 提供get方法 指定放不存在时候返回后学的东西 比如a.get('Fuck',None)
limit = kw.get('limit', None)
if limit is not None:
sql.append('limit')
if isinstance(limit, int):
sql.append('?')
args.append(limit)
elif isinstance(limit, tuple) and len(limit) ==2:
sql.append('?,?')
args.extend(limit)
else:
raise ValueError('Invalid limit value : %s ' % str(limit))
rs = yield from select(' '.join(sql),args) #返回的rs是一个元素是tuple的list
return [cls(**r) for r in rs] # **r 是关键字参数,构成了一个cls类的列表,其实就是每一条记录对应的类实例
@classmethod
@asyncio.coroutine
def findNumber(cls, selectField, where=None, args=None):
'''find number by select and where.'''
sql = ['select %s __num__ from `%s`' %(selectField, cls.__table__)]
if where:
sql.append('where')
sql.append(where)
rs = yield from select(' '.join(sql), args, 1)
if len(rs) == 0:
return None
return rs[0]['__num__']
@classmethod
@asyncio.coroutine
def find(cls, primarykey):
'''find object by primary key'''
#rs是一个list,里面是一个dict
rs = yield from select('%s where `%s`=?' %(cls.__select__, cls.__primary_key__), [primarykey], 1)
if len(rs) == 0:
return None
return cls(**rs[0]) #返回一条记录,以dict的形式返回,因为cls的夫类继承了dict类
@classmethod
@asyncio.coroutine
def findAll(cls, **kw):
rs = []
if len(kw) == 0:
rs = yield from select(cls.__select__, None)
else:
args=[]
values=[]
for k, v in kw.items():
args.append('%s=?' % k )
values.append(v)
print('%s where %s ' % (cls.__select__, ' and '.join(args)), values)
rs = yield from select('%s where %s ' % (cls.__select__, ' and '.join(args)), values)
return rs
@asyncio.coroutine
def save(self):
args = list(map(self.getValueOrDefault, self.__fields__))
print('save:%s' % args)
args.append(self.getValueOrDefault(self.__primary_key__))
rows = yield from execute(self.__insert__, args)
if rows != 1:
print(self.__insert__)
logging.warning('failed to insert record: affected rows: %s' %rows)
@asyncio.coroutine
# 显示方言错误是什么鬼。。。
def update(self): #修改数据库中已经存入的数据
args = list(map(self.getValue, self.__fields__)) #获得的value是User2实例的属性值,也就是传入的name,email,password值
args.append(self.getValue(self.__primary_key__))
rows = yield from execute(self.__update__, args)
if rows != 1:
logging.warning('failed to update record: affected rows: %s'%rows)
@asyncio.coroutine
def delete(self):
args = [self.getValue(self.__primary_key__)]
rows = yield from execute(self.__delete__, args)
if rows != 1:
logging.warning('failed to delete by primary key: affected rows: %s' %rows)
if __name__=="__main__":#一个类自带前后都有双下划线的方法,在子类继承该类的时候,这些方法会自动调用,比如__init__
class User2(Model): #虽然User类乍看没有参数传入,但实际上,User类继承Model类,Model类又继承dict类,所以User类的实例可以传入关键字参数
id = IntegerField('id',primary_key=True) #主键为id, tablename为User,即类名
name = StringField('name')
email = StringField('email')
password = StringField('password')
#创建异步事件的句柄
loop = asyncio.get_event_loop()
#创建实例
@asyncio.coroutine
def test():
yield from create_pool(loop=loop, host='localhost', port=3306, user='root', password='Limin123?', db='test')
#user = User2(id=2, name='Tom', email='slysly759@gmail.com', password='12345')
r = yield from User2.findAll()
print(r)
#yield from user.save()
#ield from user.update()
#yield from user.delete()
# r = yield from User2.find(8)
# print(r)
# r = yield from User2.findAll()
# print(1, r)
# r = yield from User2.findAll(name='sly')
# print(2, r)
yield from destroy_pool() #关闭pool
loop.run_until_complete(test())
loop.close()
if loop.is_closed():
sys.exit(0) NO1: 为何要使用asyncore 和 aiomysql 这两个库
假设我们调用数据库的请求不知一个,比如用户小王访问我们网站,获取你以前的文章,那么东北社会你关哥也在同一时间访问我们网站,而文章比较多,小王的请求需要5秒才能返回结果。采用同步的话,那社会你关哥 就要等着小王请求王城才能进行请求(获得服务器关注)么? 显然不行,因此需要采用异步的收发请求 。而Python 中实现这个的就是asyncore 他封装了HTTP UDP SSL 的异步协议 可以让单线程 也可以异步收发请求。(如果你想自己实现套字节的异步收发返回,可以小小参考一下我的这篇网络脚本编写)
那aiohttp是什么鬼 aiomysql 又是什么叼东西。他们都是基于asyncore 实现的异步http库 异步mysql 库 调用他们就可以实现异步请求在http 和 mysql 上。记住:一处异步 处处异步
NO2:关于日志的记录
引用日志模块logging 没有什么好说的 需要注意的是 在我们编写服务端的时候 良好的日志记录习惯很重要 不要被pycharm惯坏了 动不动print大法 debug大法 另外我想补充的是:logging这个吊玩儿,在多线程记录的时候会出错,需要改写其中的某些方法,别问我是如何知道的。对了,
level=logging.INFO
这个INFO大写。
NO3:*args **kw是什么东西?
*args 和 **kwargs 主要用于函数定义。 **kw就是**kwargs的缩写,可以传递数量不一的变量,他们的核心是前面的星号 一颗星和两颗星 而不是后面的args 你写成*fuckyou 都没事。只不过是约定俗称而已。那么这个屌丝东西怎么用呢?我们看一段示例代码:(我改自gitbook Python进阶)
输出结果:
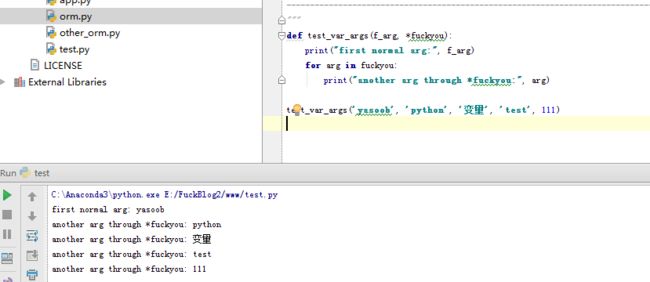
我们再来看**kwargs
**kwargs :该参数允许你将不定长度的键值对, 作为参数传递给一个函数。 如果你想要在一个函数里处理带名字的参数, 你应该使用**kwargs。
你肯定回想 啥叫键值对 带名字的参数又是什么鬼 我们来看这个例子:
怎么样现在传的时候是不是有点小明白 就像传递一个字典一样,比如这样:
主要传进去my_info 是一个字典就好了。
一般来讲传递的顺序是 var *args **kwargs
这里面就顺便提一下,字典的get方法用法是get(key,value) 如果没有key对应的键值 则返回设定value
比如
返回就是:
email ==> slysly759@gmail.com
slysly759@gmail.com
Fuck None
name ==> sly
sly
Fuck None
NO3: yield 和 yield from 语法
我们都知道yield 或者说对yield 比较熟悉 因为我们教学的案例常常就是 yield result 当一个 生成器(英文:generator)。但是我们为了弄清楚这一系列的东西 我们需要首先弄清楚迭代器 生成器这些鬼东西。在这方面 除了官方文档 我还查阅了 这个 这个还有这个 当然 IBM的也不错 等等 我就不一一列出了。
生成器的简析:
我们为啥需要生成器?假设我们需要处理草榴的所有用户信息,如果一次性就处理1000万的用户信息列表非常耗费内存,我们的本地电脑内存不够用,那么就需要一个分批处理草榴用户信息生成器的东西,当我们调用一次的时候返回1000用户信息列表即可 ,下一次调用就返回uid在1001-2000的用户就好了。但是你可能会问:函数里面的return咋知道你是下一次调用还是第三次第四次调用 给你返回你想要的值呢?而这就是yield 存在的神奇方法,它能够记住。
而正因为yield 存在才使得我们不需要拥有存储 1000万草榴用户信息列表,就能逐步得到这些信息。内存占用极小。
那么可能会有人问:适用于生成器的对象自身需要可迭代能力么 也就是说我必须要是一个字典列表啥的才行么?
事实上生成器调用的对象自身必须拥有可迭代能力,之所以你认为传递列表或者字典是你把迭代在Python里面的识别狭义化了。
什么是可迭代?什么东西可以记住当前调用位置?
可迭代是指一种可以在容器中逐个提取元素的能力。
(容器:将多个元素组合在一起的数据结构,常见的容器有 dict list tuple str 文本流 以及他们这些的变形比如OrderedDict)
迭代器的内部状态可以记住当前调用位置
Python是如何识别一个对象拥有可迭代能力?
一个可迭代对象必须具备:
__iter__()
(为啥该命名方法前后有__因为这是Python特殊方法,以示区分,在OOP编程的后续会给大家讲到)
而迭代器呢则必须具备以下特殊方法:2.x是next()
__iter__()__next__()
我们来看廖雪峰在IBM workplace上给的yield 斐波拉切数列案例
你最终会发现这个yield 让返回的对象变成了 generator 一个生成器。 它让你关注的点更多的在算法实现上,而非存储上面。
那么我们该如何自己去实现这个迭代器呢?
调用和拥有yield 的函数一样,同上。
如果还有疑问或者我的描述有错误的可以在博客评论中提出(mail写好我回复你会收到邮件~)
解释了yield 我们来看一下 yield from
关于yield from 这个Python 3.3 才支持的东西我们看一下:
首先,yield from 是为了解决什么问题而出现的。
看到上文我们发现一个问题,yield 不能脱离代码单独出来用,在一个生成器中调用另外一个生成器想要用,咋办 那么我们就需要yield from
yield from的的历史可以参考 这个PEP:
总之大意是原本的yield语句只能将CPU控制权还给直接调用者,当你想要将一个generator或者coroutine里带有yield语句的逻辑重构到另一个generator(原文是subgenerator)里的时候,会非常麻烦,因为外面的generator要负责为里面的generator做消息传递;所以某人有个想法是让python把消息传递封装起来,使其对程序猿透明,于是就有了
yield from。
对于简单的迭代器,yield from iterable本质上等于for item in iterable: yield item的缩写版 yield from允许子生成器直接从调用者接收其发送的信息或者抛出调用时遇到的异常,并且返回给委派生产器一个值
那么在本次学习orm的过程中你就把他理解为异步执行即可 先别管原理了。
如果大家仍旧很感兴趣 可以参考这篇文章 我能力有限 就不画蛇添足了。
NO4. __pool 和这个__init__ 这些东西是啥?
这个就简单说一下 前面一条杠 就是非公开变量 两条杠私有变量 一条杠能调用 两条杠就不允许外部调用。不像Java 那样有什么private 什么的 别再和我说不能阻止外部调用很不安全 私有变量 不可以 You are Adult.
__str__ __init__ __name__ 这些都是特殊方法(或者魔术方法) 内置的 详细干嘛自己去Python官网看。
NO5. @asyncore.coroutine 是什么鬼?
它能够将一个生成器generator标记为coroutine类型,然后扔进Eventloop 异步执行。
这里我们需要回去复习廖雪峰大神关于asyncore的讲解。(这告诉我们 翘课早晚是要还的 不管你是网课还是自学)
运行这段代码 首先你会看到三个 hello world 然后过了三秒 看到三个hello again这说明 主进程并未在sleep停留 而是直接将任务继续引入Eventloop中进行执行 这相比 那种单步 一直让社会你关哥等的那种先进了一些。
0x03 撰写Python orm 的一些个人解释
NO1:设计Field类意义在哪里?
将数据库的类型与Python进行对应。比如说我们需要对数据库建表或者增删改查 数据库的字段不仅有不同类型 还有是否为主键的设置,这需要我们定一个class 类来进行定义。
这个__str__你可以理解为这个类的注释 说明。在廖雪峰的定制类一篇有详细说明
print打印出来的信息就是来源于这个类。如果是调试显示的话是__repr__
这里提下:repr()方法 可以强制返回类似于字符串的东西 str未必
这里有牛人的解释。
其次是后续的继承:
这个super()方法用于多态继承的,更新变量 使用。
理解Python 中的元类(英文:metalclass)
我们都知道我们创建的实例一开始都继承object 这个基类 那么当我们想创建类的时候我们需要继承怎么办? 于是就有了基类。用 Tim Peters 的话来说就是我们一般不用这个,只有在写一些orm 或者高级封装的时候才会用到这个黑魔法。
Well, usually you don’t:
Metaclasses are deeper magic that 99% of users should never worry about. If you wonder whether you need them, you don’t (the people who actually need them know with certainty that they need them, and don’t need an explanation about why).
Python Guru Tim Peters
现在我们按照廖雪峰大神的例子场景还原:我们需要一个自定义的list 这个list能干嘛呢 多一个fuck方法 调用一次 加一个‘fuck’在list末尾。是不是觉得很爽?
看看我改写的代码:
如何需要深入了解比如继承父类集合或者cls 是如何由Python 解释器自动提供 我觉得额 最好赶快去看源代码谢谢 ~
对了 顺便提一下 @classmethod 作为一个装饰器 为metalclass 提供方便。
一般来说,要使用某个类的方法,需要先实例化一个对象再调用方法。
而使用@staticmethod或@classmethod,就可以不需要实例化,直接类名.方法名()来调用。
如果你觉得有更好的在这方面的解释文章可以分享,可以推荐给我哈~
0x04 后记
忙完PornDetective 这三天就一直忙于这个ORM的学习,在学习过程中很有趣 也很有意思。自己的能力也有所提高。希望这篇文章对大家能够有所帮助。