浅谈树链剖分
首先把一个知识摆在前面:倍增。
这是个非常优秀的算法,他普遍应用与何处呢?像树上的倍增求LCA,序列中的倍增RMQ之类的算法,倍增在dp中也有广泛应用,可以大大优化时间和空间。
但是我相信,各位读者都是比本人智商高的人,于是倍增只讲讲一个RMQ。
RMQ有一个很优秀的算法就是DP。这个大家都很熟悉,众所周知,RMQ中多加一个修改操作,那么DP就失去的它的用武之地,也就是说,倍增在这里就不管用了。那么,就引出了重点内容——树链剖分。
树链剖分的目的是对树路径信息维护。将一棵树划分成若干条链,用数据结构去维护每条链,复杂度为O(logN)。
但是如何分呢?分成什么呢?
将树中的边分为:轻边和重边
定义siz(x)为以x为根的子树的节点个数。
令v为u的儿子节点中siz值最大的节点,那么边(u,v)被称为重边,树中重边之外的边被称为轻边。
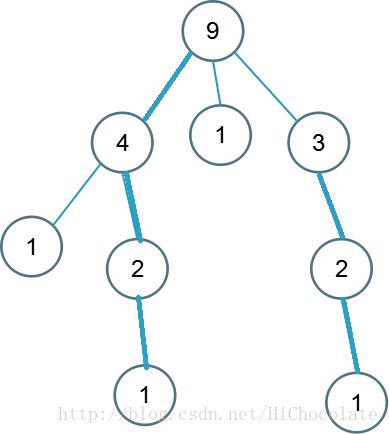
上图节点中的数表示儿子数量。粗边为重边。其余的为轻边。
我们称某条路径为重链,重链是由重边组成。
top[x]表示x所属重链的起点。
x 1 2 3 4 5 6 7 8 9
top[x] 1 1 3 4 5 1 4 1 4
轻边(U,V),siz(V)<=siz(U)/2。 从根到某一点的路径上,不超过O(logN)条轻边,不超过O(logN)条重路径。
然后大家就看完了概念,现在我们来考虑如何实现。
数链剖分的过程为2次dfs
第一次:按照定义找出重边、重儿子
第二次:按照优先走重边的原则走出一个dfs序,x在dfs序中的位置记为tree[x],并算出每个点所属重链的起点top[x]。
剖分完之后,每条重链就相当于一段区间,用数据结构(如线段树等)去维护。
把所有的重链首尾相接,放到同一个数据结构上,然后维护这一个整体即可。
如果u和v在同一条重链上,直接用数据结构修改tree[u]至tree[v]间的值或查询答案。
如果u和v不在同一条重链上 一边进行修改,一边将u和v往同一条重链上靠,然后就变成了上面的情况。
具体操作:我们把深度较大的一方x跳到他的fa[top[x]]上,并修改或查询tree[top[x]]~tree[x]
由于一条重链在数据结构中是一段连续的区间,所以直接查询tree[top[x]]~tree[x]是没问题的。
然后就几乎没啦。
证明一下时间复杂度。
一条路径由于被分成logN条重链,每条重链又对数据结构进行一次搜索,所以一次操作的复杂度为O(logN*数据结构的复杂度)。
假如用LCT来维护的话就是O(logN)了。
最后,丢下一道经典例题:
【ZJOI2008】树的统计
Description
一棵树上有n个节点,编号分别为1到n,每个节点都有一个权值w。
我们将以下面的形式来要求你对这棵树完成一些操作:
I. CHANGE u t : 把结点u的权值改为t
II. QMAX u v: 询问从点u到点v的路径上的节点的最大权值
III. QSUM u v: 询问从点u到点v的路径上的节点的权值和
注意:从点u到点v的路径上的节点包括u和v本身
Input
输入文件的第一行为一个整数n,表示节点的个数。
接下来n – 1行,每行2个整数a和b,表示节点a和节点b之间有一条边相连。
接下来n行,每行一个整数,第i行的整数wi表示节点i的权值。
接下来1行,为一个整数q,表示操作的总数。
接下来q行,每行一个操作,以“CHANGE u t”或者“QMAX u v”或者“QSUM u v”的形式给出。
Output
对于每个“QMAX”或者“QSUM”的操作,每行输出一个整数表示要求输出的结果。
Sample Input
4
1 2
2 3
4 1
4 2 1 3
12
QMAX 3 4
QMAX 3 3
QMAX 3 2
QMAX 2 3
QSUM 3 4
QSUM 2 1
CHANGE 1 5
QMAX 3 4
CHANGE 3 6
QMAX 3 4
QMAX 2 4
QSUM 3 4
Sample Output
4
1
2
2
10
6
5
6
5
16
Data Constraint
对于100%的数据,保证1<=n<=30000,0<=q<=200000;中途操作中保证每个节点的权值w在-30000到30000之间。
本题显然树链剖分,大家可以把本题作为树链剖分的入门题,开心地虐题把~~~
Code:
uses math;
var
i,j,k,l,n,m,num,x,y,tot,gs:longint;
small,ans:int64;
tov,last,next,siz,son,dep,fa,tree,pre,top,f,a,tmax:array[1..800000] of int64;
ch:char;
procedure maketree(x,st,en:longint);
var
m:longint;
begin
if st=en then
begin
f[x]:=a[pre[st]];
tmax[x]:=a[pre[st]];
end
else
begin
m:=(st+en) div 2;
maketree(x*2,st,m);
maketree(x*2+1,m+1,en);
tmax[x]:=max(tmax[x*2],tmax[x*2+1]);
f[x]:=f[x*2]+f[x*2+1];
end;
end;
procedure change(v,x,l,r,y:longint);
var
i,j,mid:longint;
begin
if l=r then
begin
tmax[v]:=y;
f[v]:=y;
exit;
end;
mid:=(r+l) div 2;
if x>mid then
begin
change(v*2+1,x,mid+1,r,y);
end
else
begin
change(v*2,x,l,mid,y);
end;
tmax[v]:=max(tmax[v*2],tmax[v*2+1]);
f[v]:=f[v*2]+f[v*2+1];
end;
procedure findsum(x,st,en,l,r:longint);
var
m:longint;
begin
if (st>=l) and (en<=r) then ans:=ans+f[x]
else
begin
m:=(st+en) div 2;
if r<=m then findsum(x*2,st,m,l,r)
else
begin
if l>m then findsum(x*2+1,m+1,en,l,r)
else
begin
findsum(x*2,st,m,l,m);
findsum(x*2+1,m+1,en,m+1,r);
end;
end;
end;
end;
procedure findmax(x,st,en,l,r:longint);
var
m:longint;
begin
if (st>=l) and (en<=r) then ans:=max(ans,tmax[x])
else
begin
m:=(st+en) div 2;
if r<=m then findmax(x*2,st,m,l,r)
else
begin
if l>m then findmax(x*2+1,m+1,en,l,r)
else
begin
findmax(x*2,st,m,l,m);
findmax(x*2+1,m+1,en,m+1,r);
end;
end;
end;
end;
procedure dfsfd(v,f,d:longint);
var
i,j,k,l:longint;
begin
fa[v]:=f;
dep[v]:=d;
siz[v]:=1;
i:=last[v];
while i<>0 do
begin
if tov[i]<>fa[v] then
begin
dfsfd(tov[i],v,d+1);
siz[v]:=siz[v]+siz[tov[i]];
if (son[v]=0) or (siz[tov[i]]>siz[son[v]]) then son[v]:=tov[i];
end;
i:=next[i];
end;
end;
procedure dfs(v,num:longint);
var
i,j,k,l:longint;
begin
inc(gs);
tree[v]:=gs;
top[v]:=num;
pre[tree[v]]:=v;
if son[v]=0 then exit;
dfs(son[v],num);
i:=last[v];
while i<>0 do
begin
if tov[i]<>fa[v] then
begin
if tov[i]<>son[v] then
begin
dfs(tov[i],tov[i]);
end;
end;
i:=next[i];
end;
end;
function getmax(x,y:int64):int64;
var
i,j,tx,ty:longint;
k:int64;
begin
tx:=top[x];
ty:=top[y];
k:=small;
while tx<>ty do
begin
if dep[tx]then
begin
ans:=small;
findmax(1,1,n,min(tree[y],tree[ty]),max(tree[ty],tree[y]));
k:=max(k,ans);
y:=fa[ty];
ty:=top[y];
end
else
begin
ans:=small;
findmax(1,1,n,min(tree[x],tree[tx]),max(tree[tx],tree[x]));
k:=max(k,ans);
x:=fa[tx];
tx:=top[x];
end;
end;
if dep[x]>dep[y] then
begin
ans:=small;
findmax(1,1,n,tree[y],tree[x]);
k:=max(k,ans);
end
else
begin
ans:=small;
findmax(1,1,n,tree[x],tree[y]);
k:=max(k,ans);
end;
exit(k);
end;
function getsum(x,y:int64):int64;
var
i,j,tx,ty,k:longint;
begin
tx:=top[x];
ty:=top[y];
k:=0;
while tx<>ty do
begin
if dep[tx]then
begin
ans:=0;
findsum(1,1,n,min(tree[y],tree[ty]),max(tree[ty],tree[y]));
k:=k+ans;
y:=fa[ty];
ty:=top[y];
end
else
begin
ans:=0;
findsum(1,1,n,min(tree[x],tree[tx]),max(tree[tx],tree[x]));
k:=k+ans;
x:=fa[tx];
tx:=top[x];
end;
end;
if dep[x]>dep[y] then
begin
ans:=0;
findsum(1,1,n,tree[y],tree[x]);
k:=k+ans;
end
else
begin
ans:=0;
findsum(1,1,n,tree[x],tree[y]);
k:=k+ans;
end;
exit(k);
end;
procedure insert(x,y:longint);
begin
inc(tot);
tov[tot]:=y;
next[tot]:=last[x];
last[x]:=tot;
end;
begin
readln(n);
for i:=1 to n-1 do
begin
readln(x,y);
insert(x,y);
insert(y,x);
end;
for i:=1 to n do
begin
read(a[i]);
end;
fillchar(tmax,sizeof(tmax),128);
fillchar(f,sizeof(f),0);
small:=tmax[1];
dfsfd(1,0,1);
dfs(1,1);
maketree(1,1,n);
readln(m);
for i:=1 to m do
begin
if i=9 then
ch:=' ';
read(ch);
if ch='Q' then
begin
read(ch);
if ch='M' then
begin
for j:=1 to 3 do read(ch);
readln(x,y);
writeln(getmax(x,y));
end
else
if ch='S' then
begin
for j:=1 to 3 do read(ch);
readln(x,y);
writeln(getsum(x,y));
end;
end
else
if ch='C' then
begin
for j:=1 to 6 do read(ch);
readln(x,y);
change(1,tree[x],1,n,y);
a[x]:=y;
end;
end;
end.
说在最后:
树链剖分是一个方法,思路,只要多去找题练习,就可以很好掌握。它的应用范围特别广阔,所以,早学晚学都是可以的~