TIBCO Spotfire 10.4新特性
亲们,TIBCO Spotfire 10.4今天正式发布了。
新的TIBCO Spotfire 10.4的新特性包含数据访问,可视化分析,数据争用和开发人员功能方面的改进。Spotfire 10.4中的签名功能是对Google BigQuery的原生支持。借助新的Google BigQuery连接器,您可以使用实时查询和广泛的分析功能,解锁大量数据的交互式可视化数据发现。该连接器使用Google的API,因此您甚至无需安装驱动程序,而是在Web浏览器中使用Google帐户登录。Spotfire®10.4还为ComputeDB(TIBCO内存分析数据库)引入了原生支持。它基于Apache Spark和Apache Geode,可为统一分析工作负载提供高吞吐量,低延迟和高并发性。
作为TIBCO Cloud™Spotfire用户,您现在可以直接从Web客户端中的TIBCO Data Virtualization实例刷新数据。事实上,由于数据加载框架中的新机制,现在可以直接从Consumer and Business Author Web客户端的Data菜单刷新数据。如果数据刷新失败,则会为失败的源保留先前的数据。
还提供新的节省时间的功能。现在可以使用键盘快捷键和搜索来快速添加可视化,然后返回“文件”菜单中的“打开”。
管理员和作者将欣赏用户操作日志现在收集可视分析操作和开发人员,C#API允许IronPython脚本和C#扩展访问用户信息。
请注意,Spotfire 10.4是主流版本。发布后发现的关键问题的修复仅针对最新版本和长期支持的版本。有关主流版本和长期支持版本之间差异的更多信息,请参阅 文档。
数据访问
原生Google BigQuery访问权限
用于Google BigQuery的新的原生自助服务连接器不需要驱动程序,并且可以将交互式查询推送到最大量的数据。Google Analytics用户还可以在页面跟踪事件数据上推送交互式查询。
Google BigQuery连接器位于Google Analytics旁边的“连接到”列表中。

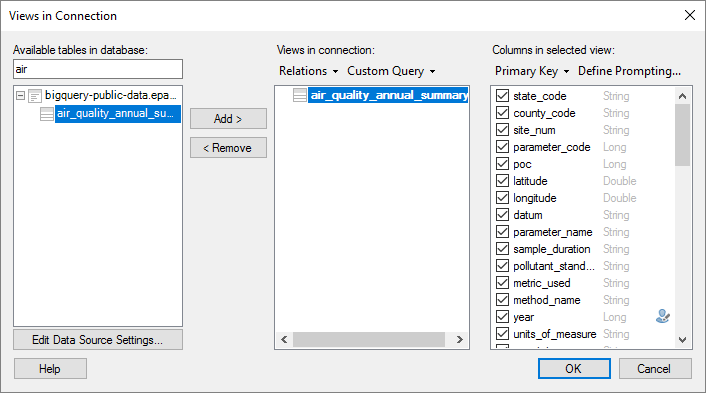
Google BigQuery连接器具有大多数可用的Spotfire连接器功能。例如:
- 自定义查询
- 提示
- 关系
- 主键列
- 数据库内下推查询
- 内存提取
- 按需数据加载
- 自动化服务支持
- 预定更新支持
您还可以使用计算列来争论数据。
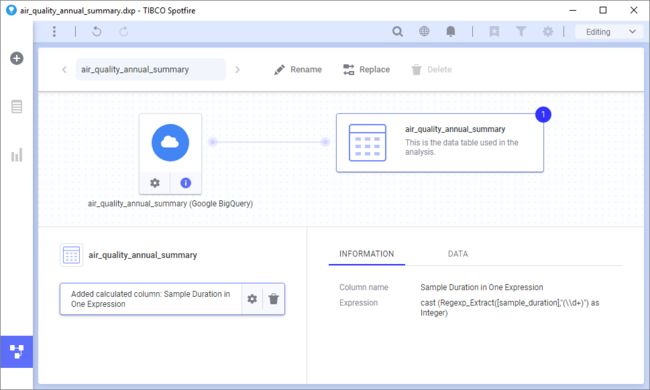
在这个例子中,我们已经保存在唯一数值 sample_duration 使用柱 的正则表达式 ,然后使用改变的数据类型为整数 铸造。
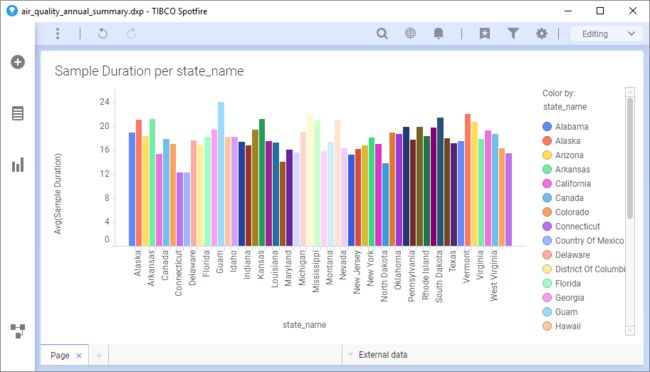
然后,可以很容易地看到每个州的平均样本持续时间。
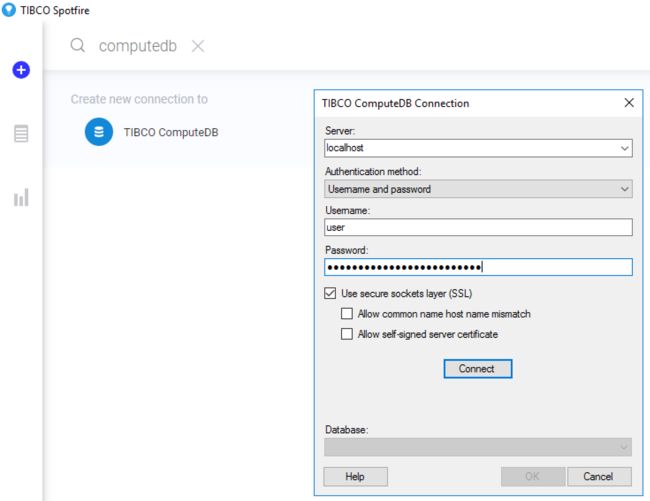
原生TIBCO ComputeDB访问
TIBCO ComputeDB内存优化分析数据库基于Apache Spark和Apache Geode(GemFire的开源版本),为统一分析工作负载提供高吞吐量,低延迟和高并发性。您可以在单个易于管理的分布式群集中将交互式和流式分析与人工智能相结合。
使用Spotfire,您现在可以使用原生TIBCO ComputeDB连接器自助访问TIBCO ComputeDB。业务用户可以轻松地将交互式查询直接连接到ComputeDB。
TIBCO Cloud™Spotfire Web客户端中的TIBCO Data Virtualization支持
在运行TIBCO Cloud™Spotfire的Web和移动客户端中,您现在可以从TIBCO Data Virtualization(TDV)加载和刷新数据。
通过面向Internet的TDV实例,这意味着您现在可以在云上运行Spotfire客户端,库和TDV。
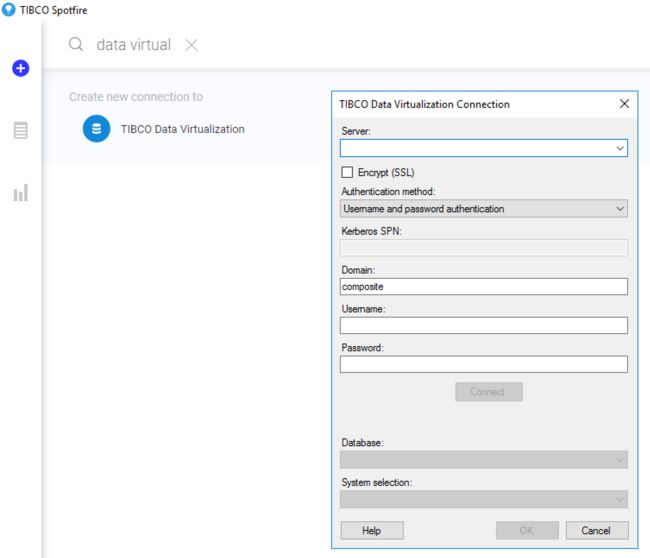
在Windows客户端上使用TIBCO Cloud Analyst创建连接。
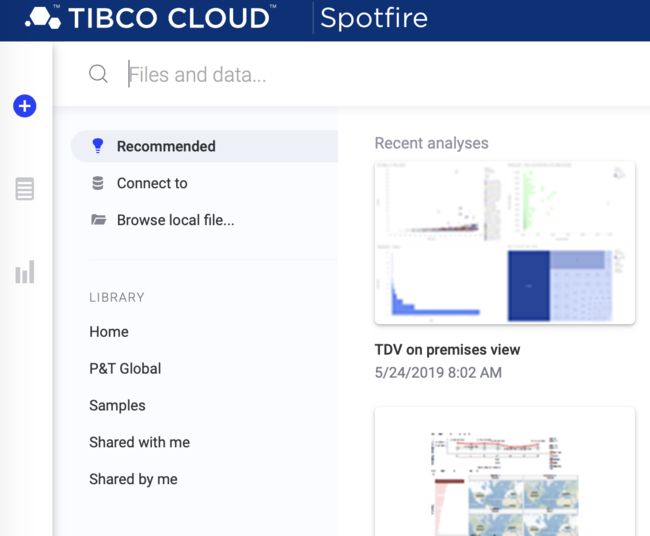
在TIBCO Cloud Spotfire Web客户端中使用和刷新数据。TIBCO驱动程序1.8
TIBCO驱动程序1.8
Spotfire Server附带了用于Apache Spark SQL,Cassandra和MongoDB的ODBC驱动程序。这些已更新到最新版本。
数据争吵
选项不在会话之间存储按需数据
按需数据表的新选项可以选择是否应按需加载的数据自动存储在分析中。以前,按需数据始终存储,但有了新的偏好,现在可以全局关闭此功能。例如,当您希望通过减小按需分析文件的大小来节省库中的存储空间时,这很有用。当许多人共享相同的分析文件并可访问按需数据的个人切片时,它也很有用。然后,每个用户将从空的按需数据表开始,直到从数据源加载其个人数据。
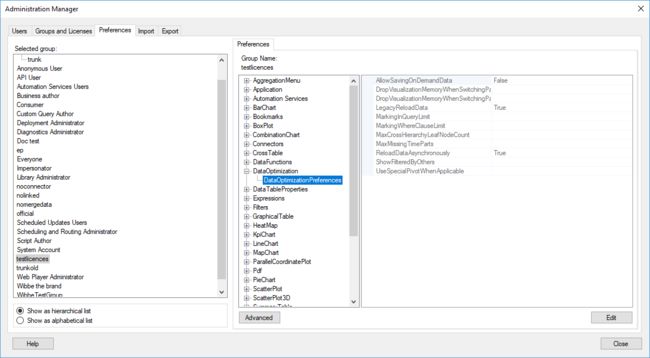
从Web客户端工具栏重新加载数据
现在可以直接从Spotfire Web客户端的工具栏重新加载数据。根据数据的加载方式以及您是处于消费者还是创作模式,刷新选项会有所不同。
当您处于 Business Author 模式时,您可以通过菜单选项 Data> Reload Linked Data and Data> Reload All Data刷新所有链接和所有存储的数据源。
当您处于“ 消费者” 模式时,您可以通过菜单选项“ 数据”>“重新加载关联数据”刷新链接数据源,以 获取尚未由“预设更新”加载的分析文件。
这种差异和限制可以保护您的公司免于让10,000名消费者刷新已存储在分析中的大型数据集,以将分析工作负载与生产数据库工作负载分开,或者已配置为加载(每晚)为同一目的安排。
此功能也可通过Spotfire API获得。

在此业务作者示例中,我们链接了数据,但也能够刷新所有数据,包括存储和嵌入数据。
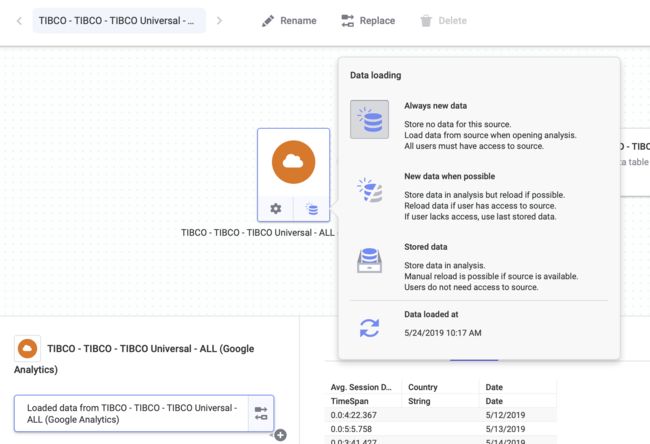
在创建或编辑分析时定义的数据加载选项控制应该可以刷新哪些数据源。
如果重新加载失败,则保留数据
Spotfire有三个数据加载选项:Always new data,尽可能新数据和存储数据。使用打开的分析时,如果您选择重新加载链接数据并且重新加载失败,Spotfire将保留已加载的链接数据。例如,如果缺少数据源,就会发生这种情况。对于基于多个数据源的数据表,结果可以是部分重新加载的数据表。
也可以跳过无法重新加载的嵌入式数据表的重新加载,并继续使用其余的数据表。
可视化分析
用于可视分析的用户操作日志记录
Spotfire操作日志现在基于可视分析记录操作。例如,现在记录用户创建可视化,更改列或聚合,创建/删除/重命名页面,过滤数据,导出数据等操作。这使公司能够更好地了解其用户及其可视化分析行为。下面的屏幕截图显示了一个分析,用户可以看到用户在一天的什么时间使用过滤器,他们使用了哪种过滤器以及执行过滤的用户的详细信息。

可视化类型的快捷方式
现在可以使用CTRL +数字键盘组合快速创建新的可视化。CTRL + 1创建一个表,CTRL + 2表示一个交叉表,然后它以与可视化弹出窗口相同的顺序继续。在CTRL + 9之后,它以CTRL + SHIFT + 1重新开始。
您可以将鼠标指针悬停在弹出窗口中的可视化图标上,以了解可视化类型具有哪种键盘组合。
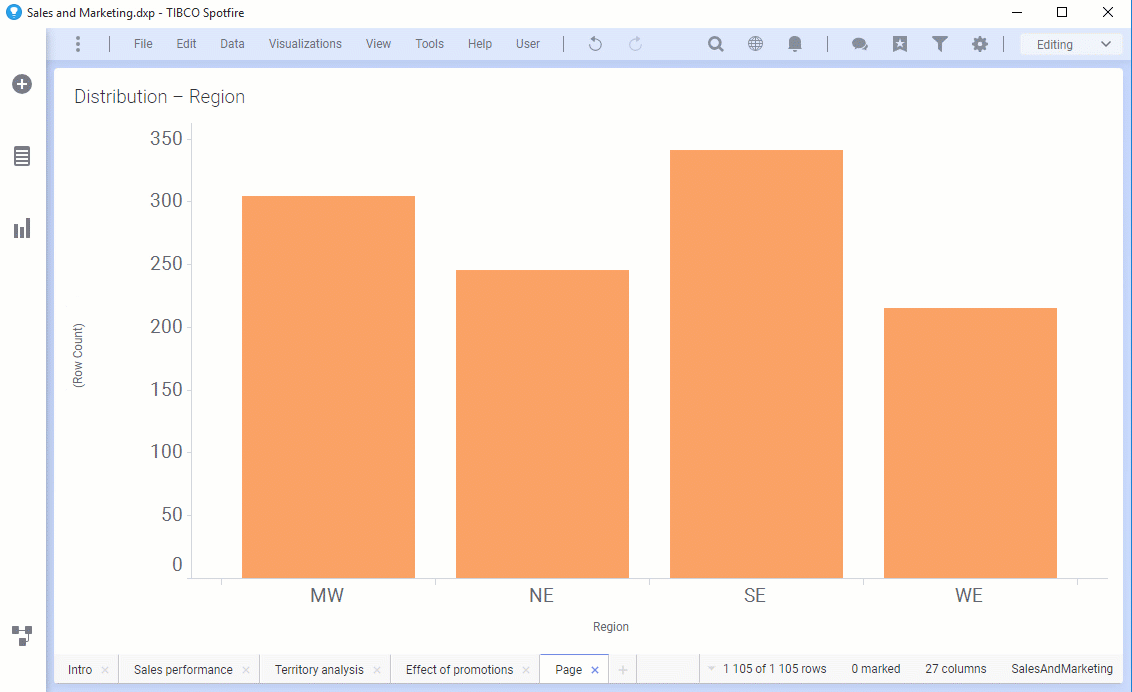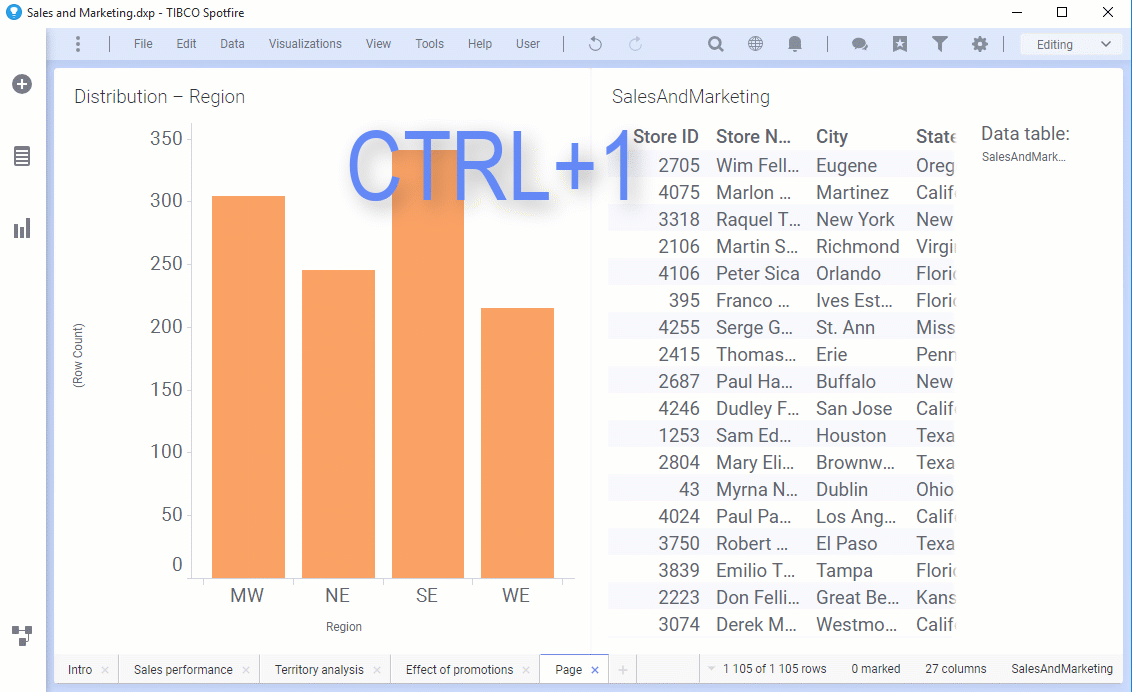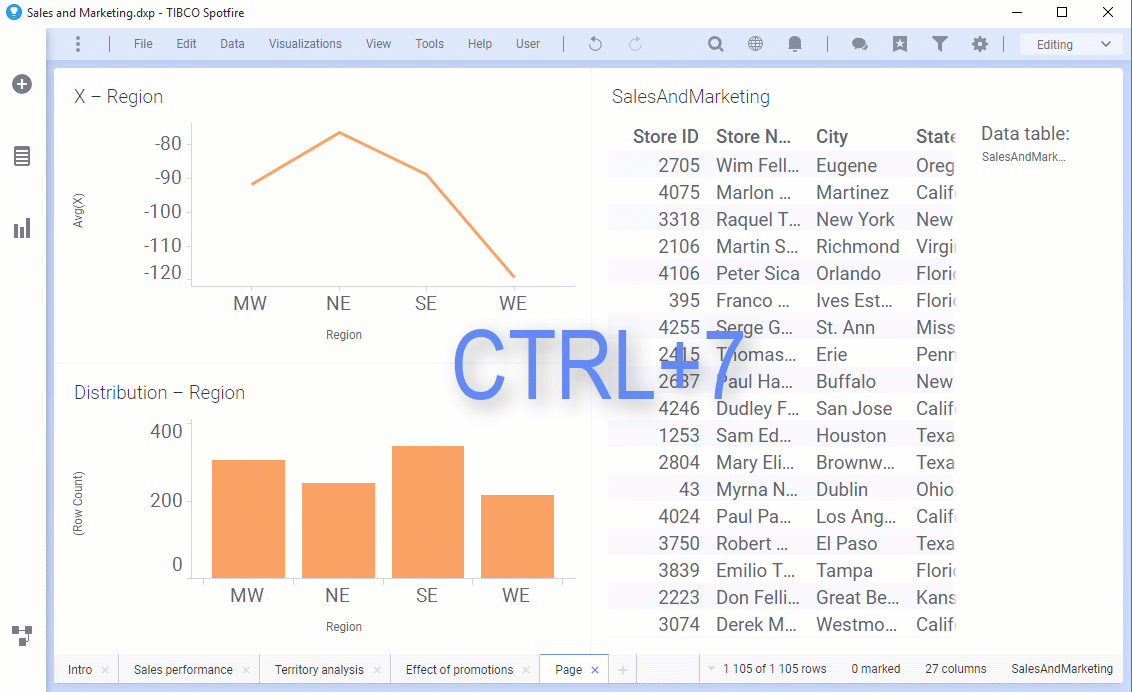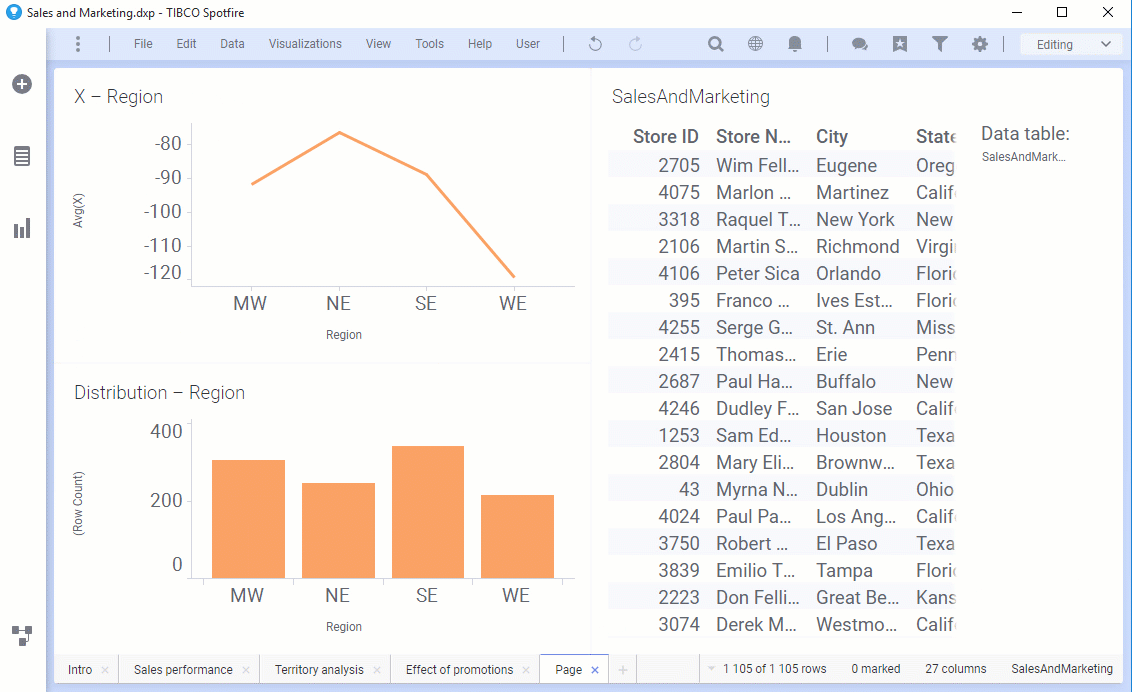
搜索以添加特定的可视化类型
现在可以使用“查找”工具通过搜索可视化类型(如“地图”,“条形图”等)来添加可视化。
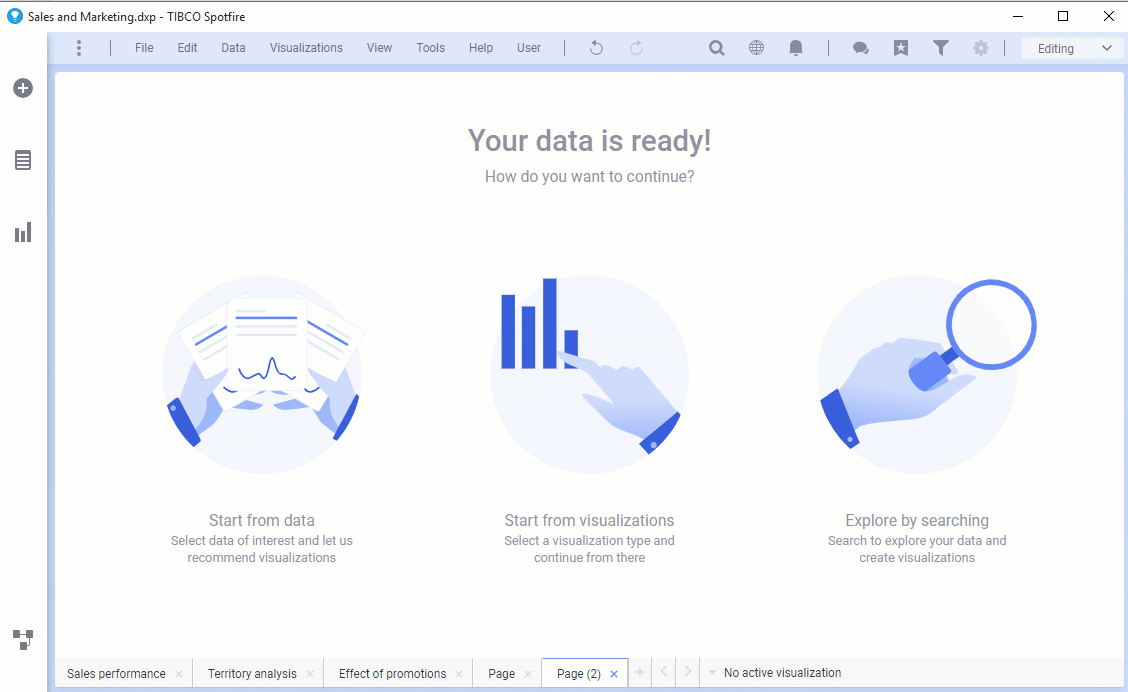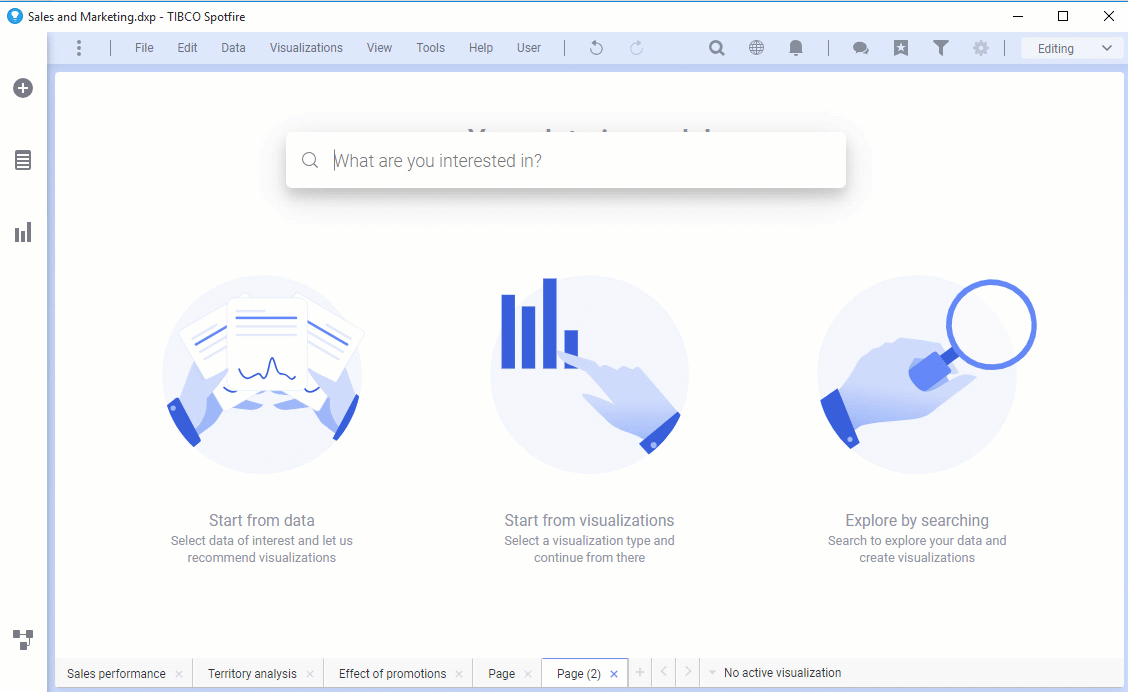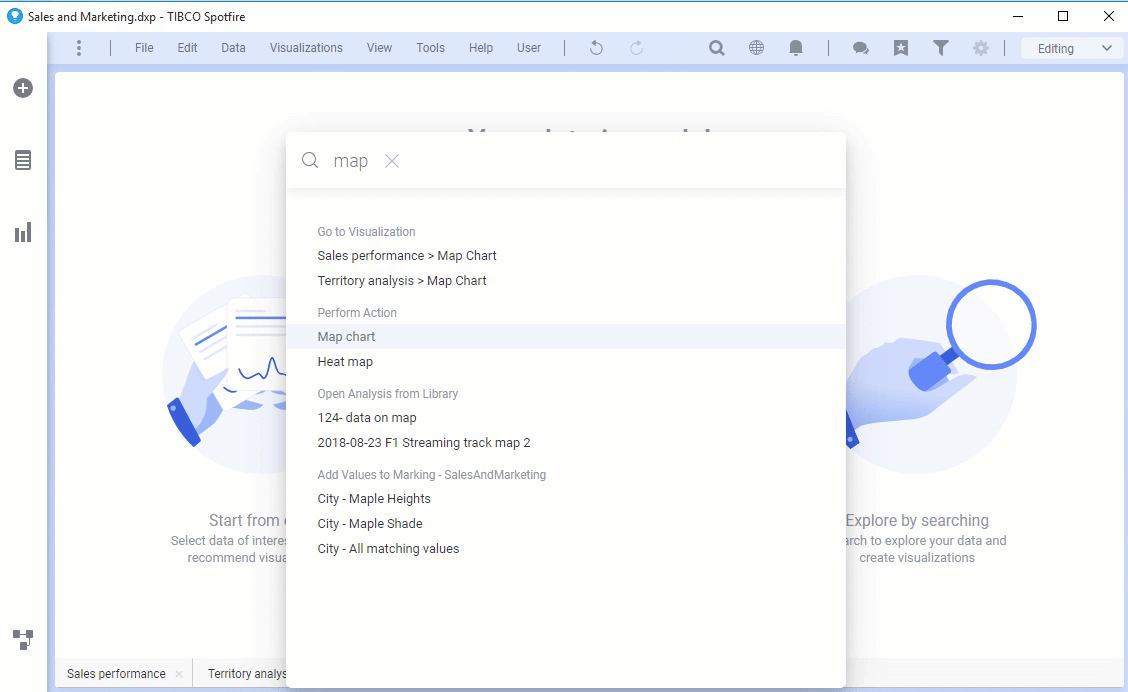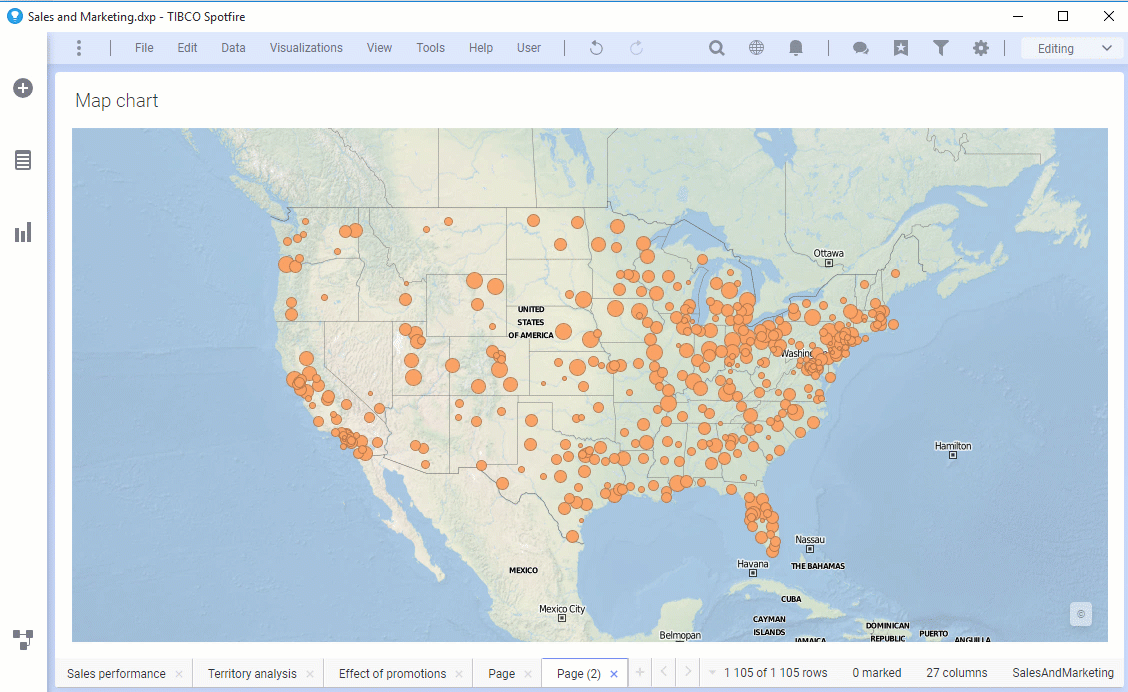
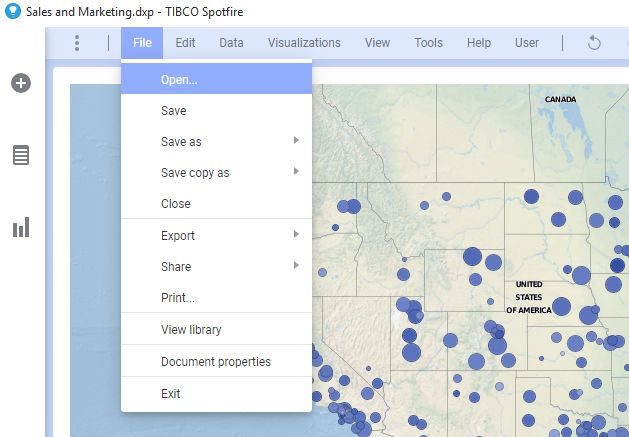
从“文件”菜单中打开
现在,“文件”菜单中有一个“打开”选项,可打开内容浏览器弹出窗口,并允许用户浏览新的分析,数据源或数据文件。
开发人员
用于访问用户信息的C#API
对C#API的这一添加允许IronPython脚本或C#扩展访问用户名,域,组/角色成员以及有关当前用户的其他相关信息。
如需要联系TIBCO原厂的Spotfire采购,各位可以访问如下链接
https://www.tibco.com/company/locations
中国北京Main Office Phone
+86 10 8341 3723