自旋锁公平性的三种实现
随着多核处理器的爆炸式增长,多线程同步访问共享内存的性能也成了计算机系统发展的关键。在《互斥锁与自旋锁》这篇文章中我们提到了互斥锁与自旋锁之间的区别以及各自的优点和适用场景。
普通自旋锁的实现
我们适用Java代码来实现一个简单的自旋锁:
import java.util.concurrent.atomic.AtomicBoolean;
public class Spinlock {
private AtomicBoolean available = new AtomicBoolean(false);
public void lock() {
// 循环检测尝试获取锁
while (!tryLock())
Thread.yield();//这一句可以不加,加上节能减排
// while (!tryLock());
}
public boolean tryLock() {
// 尝试获取锁,成功返回true,失败返回false
return available.compareAndSet(false, true);
}
public void unlock() {
if (!available.compareAndSet(true, false)) {
throw new RuntimeException("释放锁失败");
}
}
}这种简单的自旋锁有一个问题:无法保证多线程竞争的公平性。对于上面的Spinlock,当多个线程想要获取锁时,谁最先将available设为false谁就能最先获得锁,这可能会造成某些线程一直都未获取到锁造成“线程饥饿”。就像我们下课后蜂拥的跑向食堂,下班后蜂拥地挤向地铁,通常我们会采取排队的方式解决这样的问题,类似地,我们把这种锁叫“排队自旋锁(QueuedSpinlock)”。计算机科学家们使用了各种方式来实现排队自旋锁,如TicketLock,MCSLock,CLHLock。接下来我们使用源码对这几种锁的基本原理进行分析。
TicketLock
第一种方法就是按先来后到的顺序为每个线程编个号,按编号顺序来分配锁。这就类似于银行挂号或者医院挂号一样,按照先来后到的顺序为每个问诊者排个号,医生按号依次为问诊者服务。
import java.util.concurrent.atomic.AtomicInteger;
public class TicketSpinlock {
private AtomicInteger currService = new AtomicInteger();
private ThreadLocal LOCAL = new ThreadLocal<>();
private AtomicInteger ticketNumber = new AtomicInteger();
public void lock() {
// 为当前线程分配编号
int myTicket = ticketNumber.getAndIncrement();
LOCAL.set(myTicket);
// 等待,直到自己的编号
while (myTicket != currService.get())
Thread.yield();
}
public void unlock() {
int myTicket = LOCAL.get();
// 将锁让下一个编号的线程
currService.compareAndSet(myTicket, myTicket + 1);
}
} 缺点
Ticket Lock 虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量serviceNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
下面介绍的CLH锁和MCS锁都是为了解决这个问题的:
MCS 来自于其发明人名字的首字母: John **M**ellor **C**rummey和Michael **S**cott。
CLH的发明人是:**C**raig,**L**andin and **H**agersten。
SMP和NUMA处理器架构
1、 SMP(Symmetric Multi-Processor)
对称多处理器结构,指服务器中多个CPU对称工作,每个CPU访问内存地址所需时间相同。其主要特征是共享,包含对CPU,内存,I/O等进行共享。
SMP能够保证内存一致性,但这些共享的资源很可能成为性能瓶颈,随着CPU数量的增加,每个CPU都要访问相同的内存资源,内存访问冲突随之增加,可能会导致CPU资源的浪费。常用的PC机就属于这种。
2、 NUMA(Non-Uniform Memory Access)
非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问的由来。
NUMA较好地解决SMP的扩展问题,当CPU数量增加时,因为访问远地内存的延时远远超过本地内存,系统性能无法线性增加。
可以将NUMA视为紧密联系的集群计算形式。
CLHLock
检测前驱结点的locked状态:如果为false说明该线程是队列中的第一个线程;如果为true说明为前面已经有线程获取了锁,当前线程需要自旋阻塞。
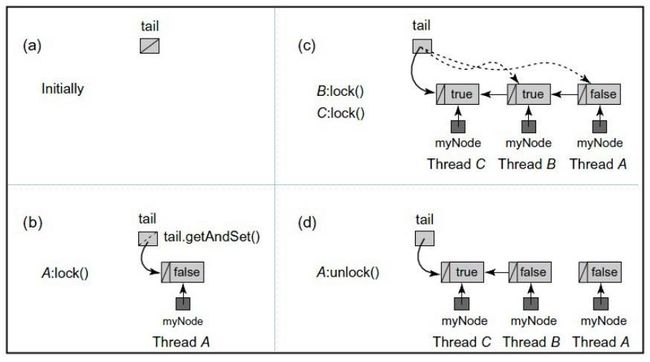
实现代码:
import java.util.concurrent.atomic.AtomicReference;
public class CLHSpinlock {
private final AtomicReference tail;
private final ThreadLocal myPred;
private final ThreadLocal myNode;
public CLHSpinlock() {
tail = new AtomicReference(new Node());
myNode = new ThreadLocal() {
protected Node initialValue() {
return new Node();
}
};
myPred = new ThreadLocal() {
protected Node initialValue() {
return null;
}
};
}
public void lock() {
final Node node = myNode.get();
node.locked = true;
Node pred = this.tail.getAndSet(node);
this.myPred.set(pred);
// 检查前驱节点的locked值
// 如果为true则自旋
while (pred.locked)
Thread.yield();
}
public void unlock() {
final Node node = myNode.get();
node.locked = false;
myNode.set(this.myPred.get());
}
private static class Node {
volatile boolean locked;
}
} CLH队列锁的优点是空间复杂度低(如果有n个线程,L个锁,每个线程每次只获取一个锁,那么需要的存储空间是O(L+n),n个线程有n个
myNode,L个锁有L个tail),CLH的一种变体被应用在了JAVA并发框架中(AbstractQueuedSynchronizer.Node)。
CLH在SMP系统结构下法是非常有效的。但在NUMA系统结构下,每个线程有自己的内存,如果前趋结点的内存位置比较远,自旋判断前趋结点的locked域,性能大打折扣,一种解决NUMA系统结构的思路是MCS队列锁。
MCSLock
MSC与CLH最大的不同并不是链表是显示还是隐式,而是线程自旋的规则不同:CLH是在前趋结点的locked域上自旋等待,而MCS是在自己的
结点的locked域上自旋等待。正因为如此,它解决了CLH在NUMA系统架构中获取locked域状态内存过远的问题。
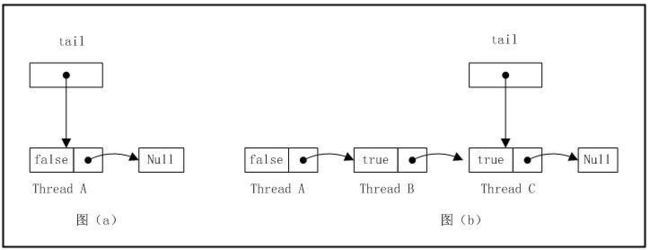
import java.util.concurrent.atomic.AtomicReference;
public class MCSSpinlock {
private volatile AtomicReference tail;
private volatile ThreadLocal myNode;
public MCSSpinlock() {
tail = new AtomicReference(null);
myNode = new ThreadLocal() {
protected QNode initialValue() {
return new QNode();
}
};
}
public void lock() {
QNode qnode = myNode.get();
QNode pred = tail.getAndSet(qnode);
// 为空直接获取锁
// 不为空则自旋等待
if (pred != null) {
qnode.locked = true;
pred.next = qnode;
// 自旋
while (qnode.locked)
Thread.yield();
}
}
public void unlock() {
QNode qnode = myNode.get();
if (qnode.next == null) {
// 没有线程等待,需要把尾节点置空
if (tail.compareAndSet(qnode, null))
return;
// 置空失败,说明在置空过程中又有新线程加入
// 这里的自旋为了保证新加入的线程确实存在
// 如果不存在,后面赋值操作将会发生空指针一场
while (qnode.next == null)
Thread.yield();
}
qnode.next.locked = false;
qnode.next = null;
}
private class QNode {
volatile boolean locked = false;
volatile QNode next = null;
}
} 公平性测试
测试仍然用之前用的计数器例子,不过为了体现出多线程竞争,代码中会使用到线程池以及一些并发库中的工具类,这些类我们会在后期的文章中陆续讲到。同时我们从上面各个锁中抽出一个Lock接口(方便测试用例),代码如下:
public interface Lock {
void lock();
void unlock();
}
java.util.concurrent.locks包中的Lock接口也会在后期的文章中讲到。
测试代码:
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadCommunicate {
static class Counter {
private Lock lock = new Spinlock();
// private Lock lock = new TicketSpinlock();
// private Lock lock = new CLHSpinlock();
// private Lock lock = new MCSSpinlock();
private volatile int value = 0;
public void increment() {
lock.lock();
value++;// 执行++操作
System.out.println("++");// 输出++到控制台
lock.unlock();
}
public void decrement() {
lock.lock();
value--;// 执行--操作
System.out.println("--");// 输出--到控制台
lock.unlock();
}
public int value() {
return this.value;
}
}
static class IncrementTask implements Runnable {
public void run() {
long start = System.nanoTime();
for (int i = 0; i < 10000; i++) {
counter.increment();
}
long end = System.nanoTime();
System.out.println("Increment:" + (end - start));
latch.countDown();
}
}
static class DecrementTask implements Runnable {
public void run() {
long start = System.nanoTime();
for (int i = 0; i < 10000; i++) {
counter.decrement();
}
long end = System.nanoTime();
System.out.println("Decrement:" + (end - start));
latch.countDown();
}
}
private static Counter counter = new Counter();
private static CountDownLatch latch = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException {
// 创建两个线程池
ExecutorService threadPool1 = Executors.newFixedThreadPool(10);
ExecutorService threadPool2 = Executors.newFixedThreadPool(10);
threadPool1.execute(new IncrementTask());
threadPool2.execute(new DecrementTask());
threadPool1.shutdown();
threadPool2.shutdown();
latch.await();// 等待线程池中的任务执行完成
System.out.println(counter.value());
}
}可以通过打开注释来修改使用的锁实现类。
1. 使用普通SpinLock
这里只截取一部分输出结果来说明问题:
--
--
--
--
++
++
++
++
++
++
Increment:242524573
0从输出结果可以看出
++和--分布不均匀
2. TicketSpinlock执行结果
这里只截取一部分输出结果:
++
--
++
--
++
--
++
--
++
--
++
--
Decrement:231070401
Increment:231519110
0输出结果中
++和--基本保持均匀执行结果的头部和尾部可能会有持续的
++或--,这与线程池执行时间的先后顺序有关
CLHSpinlock执行结果
++
--
++
--
++
--
++
--
++
--
++
--
Decrement:231070401
Increment:231519110
0输出结果中
++和--基本保持均匀
MCSSpinlock执行结果
++
--
++
--
++
--
++
--
++
--
++
--
++
--
++
Increment:231035506
Decrement:230355670
0输出结果中
++和--基本保持均匀
从任务的耗时来看三种公平性实现在性能上相差也不是很大。
参考链接:
- CLH锁 、MCS锁:http://www.cnblogs.com/yuyutianxia/p/4296220.html
- A Hierarchical CLH Queue Lock:https://people.csail.mit.edu/shanir/publications/CLH.pdf
- 自旋锁、排队自旋锁、MCS锁、CLH锁:https://coderbee.net/index.php/concurrent/20131115/577
- Why CLH Lock need prev-Node in java:https://stackoverflow.com/questions/43628187/why-clh-lock-need-prev-node-in-java
- 旋转锁:http://www.cs.cornell.edu/courses/cs4410/2015su/lectures/lec06-spin.html
- Test-and-set-维基百科:https://en.wikipedia.org/wiki/Test-and-set
- 竞争条件:http://netclass.csu.edu.cn/NCourse/hep086/chapter2/section2/2.2.1.htm
- 自旋锁、排队自旋锁、MCS锁、CLH锁:http://coderbee.net/index.php/concurrent/20131115/577
- MCS锁-c++:http://www.yebangyu.org/blog/2016/08/21/mcslock/
- Java锁的种类以及辨析(二):自旋锁的其他种类:http://ifeve.com/java_lock_see2/
- Java并发编程:Synchronized底层优化(偏向锁、轻量级锁):http://www.cnblogs.com/paddix/p/5405678.html
- 什么时候应该使用自旋锁而不是互斥体?-StackOverflow:https://stackoverflow.com/questions/5869825/when-should-one-use-a-spinlock-instead-of-mutex
- Linux 内核的排队自旋锁(FIFO Ticket Spinlock):https://www.ibm.com/developerworks/cn/linux/l-cn-spinlock/index.html