【Active Learning - 01】深入学习“主动学习”:如何显著地减少标注代价
主动学习系列博文:
- 【Active Learning - 00】主动学习重要资源总结、分享(提供源码的论文、一些AL相关的研究者):https://blog.csdn.net/Houchaoqun_XMU/article/details/85245714
- 【Active Learning - 01】深入学习“主动学习”:如何显著地减少标注代价:https://blog.csdn.net/Houchaoqun_XMU/article/details/80146710
- 【Active Learning - 02】Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally:https://blog.csdn.net/Houchaoqun_XMU/article/details/78874834
- 【Active Learning - 03】Adaptive Active Learning for Image Classification:https://blog.csdn.net/Houchaoqun_XMU/article/details/89553144
- 【Active Learning - 04】Generative Adversarial Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89631986
- 【Active Learning - 05】Adversarial Sampling for Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89736607
- 【Active Learning - 06】面向图像分类任务的主动学习系统(理论篇):https://blog.csdn.net/Houchaoqun_XMU/article/details/89717028
- 【Active Learning - 07】面向图像分类任务的主动学习系统(实践篇 - 展示):https://blog.csdn.net/Houchaoqun_XMU/article/details/89955561
- 【Active Learning - 08】主动学习(Active Learning)资料汇总与分享:https://blog.csdn.net/Houchaoqun_XMU/article/details/96210160
- 【Active Learning - 09】主动学习策略研究及其在图像分类中的应用:研究背景与研究意义:https://blog.csdn.net/Houchaoqun_XMU/article/details/100177750
写在前面
这篇博文很早之前就整理好啦,一直想继续完善再发布。但接下来一年的时间,估计会忙于各种事情,毕竟下半年就研三了。再者,最近在阿里实习,因某个业务场景需人工标注数据,借此机会尝试着做了主动学习的模拟实验,取得不错的效果,并把一些相关的理论知识和实验内容发表到阿里的内网 ATA 上,获得了不少赞赏(感谢)。因此,最近也在考虑是不是可以把一些内容也分享到 CSDN 上,也想着有机会的话能够跟一些感兴趣的读者合作,深入探索研究主动学习领域,争取能够带来实际的价值。
此外,还有一个重要的原因:如果读者们觉得这个领域能够在学术界上有所价值的话,也希望能够合作哈,发个论文,嘿嘿。个人感觉,能够从如下两个方面在 active learning 领域尝试组织一波突破。但由于时间和精力有限(虽然这话有点官方,但确实有很多其他事情,哈哈),希望有相关领域的大佬可以带飞,毕竟现在的我对论文还是很需要的...
- “select strategy”:目前大多数选择策略都是手工设计的,文献[5]在2017年首次提出通过学习的方式获得选择策略,克服了手工设计的选择策略跨领域泛化能力的不足。就像深度学习克服了手工设计的特征一样,通过学习的选择策略还有很长的道路要走,也还有很多机会可能争取。
- 工业界的真实数据:下文提到的 CVPR-2017 论文中,关键点之一就是在医疗图像领域的3个数据集验证了 Active Learning 至少能够减少一半以上的标注代价。因此,如果能够巧妙的结合实际应用场景,感觉还是能够做出点成绩的(发表论文或者实际应用价值)
说明:本文纯属根据个人学习过程中的理解进行总结,仅代表个人观点,如有问题,还望各位前辈指正...^^
 欢迎关注公众号,欢迎交流讨论~~
欢迎关注公众号,欢迎交流讨论~~
本文修改日记(Log):博文的更新时间点
2018.05.10:汇总目前学习的论文,并完成初版的“概述”部分;
2018.05.14:常用于分类问题的启发式方法、部分参考文献的简短总结、主动学习算法的步骤;
2018.05.16:主动学习算法的 Scenarios 和 Strategies;
2018.05.17:整理 CSDN 中关于AL的一些资料;
2018.05.21:增加杨文柱等人[21]的《主动学习算法研究进展》并将部分内容整合于博文中;
2018.05.22:增加新章节“主动学习领域的难点汇总”;
2018.06.30:整理于阿里ATA内网;
2018.07.08:完善并发布于CSDN;
2018.07.09:知乎链接 - https://zhuanlan.zhihu.com/p/39367595
2019.04.22:欢迎加微信讨论哈(https://blog.csdn.net/Houchaoqun_XMU/article/details/87993906)
(本文篇幅较长,可以结合博客左侧导航的“目录”阅读感兴趣的内容;文中出现[index]表示Reference文献的索引号)
=============================
概述(Abstract)
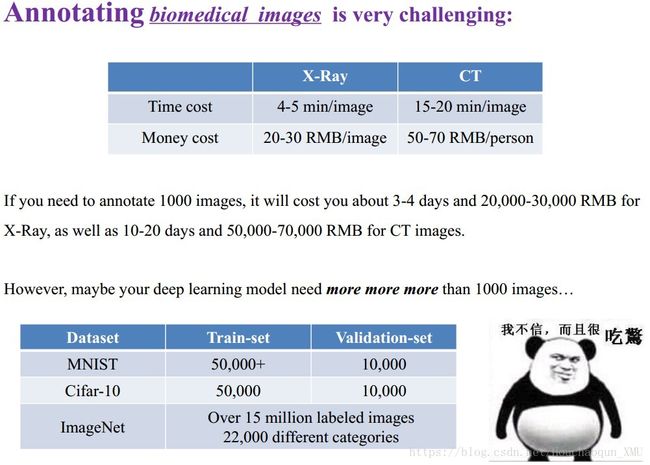
《Fine-Tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally》这是一篇发表在 CVPR-2017 的文章,我根据这篇论文详细的整理了相关的博文,也正是这篇论文让我想进一步研究“主动学习”。这篇文章提出的方法主要想解决深度学习应用中的一个重要问题:如何使用尽可能少的标注数据集训练一个模型,这个模型的性能可以达到一个由大量的标注数据集按照普通方法(随机选择训练数据)训练得到的模型的性能。如下图所示(之前在实验室分享时做的PPT),标注数据是一个很棘手的问题,特别是在生物医疗领域:1)需要具有相关专业知识的医生;2)成本很高;3)周期较长。那么,如果能用少量的标注数据去训练一个效果好的分类器,将是一个很有意义的工作。这篇文章提出的方法也是想解决这个问题,并在三种不同的生物医疗数据上做测试,证明了该方法的至少能够减少一半的标注代价。这篇论文的几个关键词:Active Learning + Transfer Learning、Data Augmentation、Majority Selection、Continuously Fine-Tuning。此外,我还找到了这篇论文作者的博客和个人主页,一位90后大佬。
随后,我找了几个分类任务相关的数据集进行实验,包括:1)MNIST;2)Cifar-10;3)Dog-Cat from Kaggle 等,使用PyTorch框架、AlexNet网络结构,算法流程如下所示(下文也会根据图示介绍主动学习算法的大体流程):
实验步骤:以cifar10为例,10分类
1)制作数据:active_samples=50000,val_samples=10000;train_samples=0;
2)初始化 alexnet 模型,随机权重得到最初的模型,记为 cifar10_alexnet_imagenet_init.7t;num_train_samples=0;
3)分别对 active_samples 目录下的 50000 - num_train_samples 张数据进行预测,得到10个类别对应的10个概率值;
4)重点关注每个样本预测结果的最大概率值:p_pred_max。我们初步认为 p_pred_max>0.5 的情况表示当前模型对该样本有个确定的分类结果(此处分类结果的正确与否不重要);反之,当前模型对该样本的判断结果模棱两可,标记为hard sample;比如:模型进行第一次预测,得到10个概率值,取其最大的概率 p_pred_max;
5)对P(real lable) < p_threshold(此处的10分类任务取p_threshold=0.5)的样本进行排序,取前N个样本加入集合train_samples中;
6)基于当前的训练数据集 train_samples 对模型进行微调,得到新的模型记为 model_fine_tuned.7t;
7)重复(3)到(6)步骤,直到 active_samples 样本数为 0 或者当前模型 model_fine_tuned.7t 已经达到理想效果;
#### steps
### step0: initialize a pretrained model based on imagent --> mnist_alexnet_imagenet_init.7t
### step1: predict active_samples on current model --> get active_train_samples_path
### step2: active_select_samples_to_train --> train samples added.
### step3: if train_dataset_sizes>0; train it --> get a new pretrained model, named active_pretrained_cifar10.7t
### do step1, step2, step3 while(active_target_val_acc>=0.9)
### step4: record number of labeled samples
按照上述算法流程分别对 MNIST、Cifar-10 和 Dog-Cat 三个数据集做实验。实验结果表明引入active learning 不仅能够得到减少样本标注代价,还能够提升分类的准确率。如MNIST的实验(train_num=55000, val_num = 10000)中,使用AlexNet模型、PyTorch框架:1)使用全部的训练数据直接训练模型120次epoch,val_acc=98.992%;2)使用主动学习,Uncertainty Strategy(US),只需要2300张标注数据val_acc就能够达到99.04%,将剩余的55000-2300=52700张扔到训练好的模型进行预测,得到 99.70% (52543/52700) 的效果。可见对于MNIST数据集,仅仅使用US策略能够得到显著的效果。主动学习为什么还能够提升分类模型的准确率呢?文献[21]提到1个解释,“带标注的训练数据可能含有部分低质量的样本(噪声点)反而会降低模型的鲁棒性(模型过渡拟合噪声点)。因此标注训练样本要在保证质量的条件下,再增加数量”。如何高效地选出具有高分类贡献度的无类标样例进行标注并补充到已有训练集中逐步提高分类器精度与鲁棒性是主动学习亟待解决的关键问题。以上3个数据集的实验结果如下表所示:
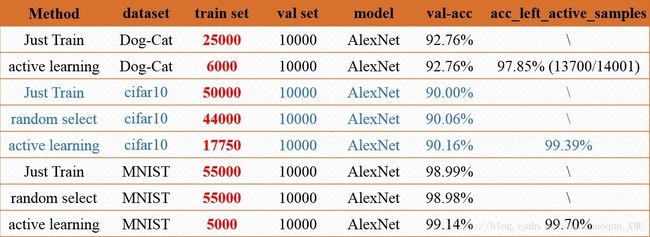 分别在MNIST、Cifar-10 和 Dog-Cat 三个数据集上验证 Active Learning 的效果
分别在MNIST、Cifar-10 和 Dog-Cat 三个数据集上验证 Active Learning 的效果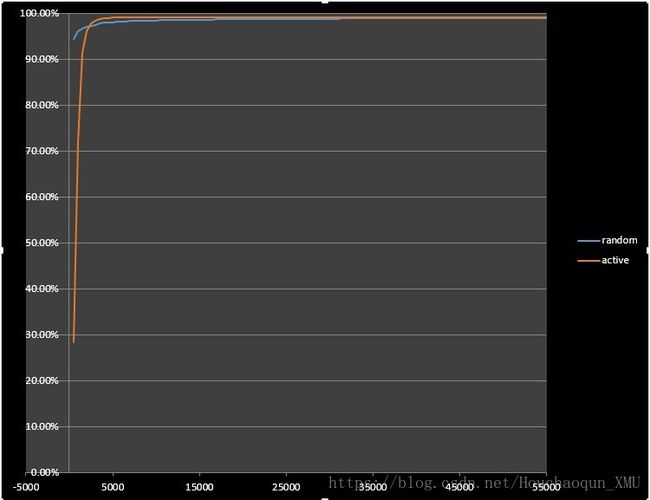
MNIST 数据集:active select vs. random select
上述实验结果表明:
1)引入 active learning 后,能够在 MNIST、Cifar-10 和 Dog-Cat 等三个数据集上减少一半以上的标注代价。虽然上述实验使用的数据集较为简单,但也能够证明 Active Learning 的效果。
2)active select 比 random select 在更少标注样本的条件下达到更高的性能,相当于下图右半部分所示的红虚线;
3)在 active learning 的实验中还有一个环节:使用训练得到的模型对未选中的样本进行预测,acc_left_active_samples 的精度都很高(表格中未列出,但3个实验的 acc_left_active_samples 都稍优于 train_acc)。本人认为:acc_left_active_samples 表示主动选择的过程中未被选中的样本,即当前模型足以能够区分出这些样本的类别,所以不再需要使用这些样本对模型进行微调(对模型的作用相对较小,甚至没有作用)。因此,当模型在 train 数据集下的训练精度达到 99.378% 时,使用当前模型对 acc_left_active_samples 样本进行预测的精度也同样在 99.378% 左右,甚至更高。
行文至此,试想一下应用场景:
假如业务需求中,遇到一些场景需要人工标注数据。一般情况下,我们不知道需要多少标注数据才能得到预期的效果,所以希望获得尽可能多的标注样本。但实际上,如下图所示,模型的性能并不是随着标注数据量的增多而无线上升的,模型的性能会有对应的瓶颈,而我们关注的正是如何使用尽可能少的标注数据去达到这个瓶颈。
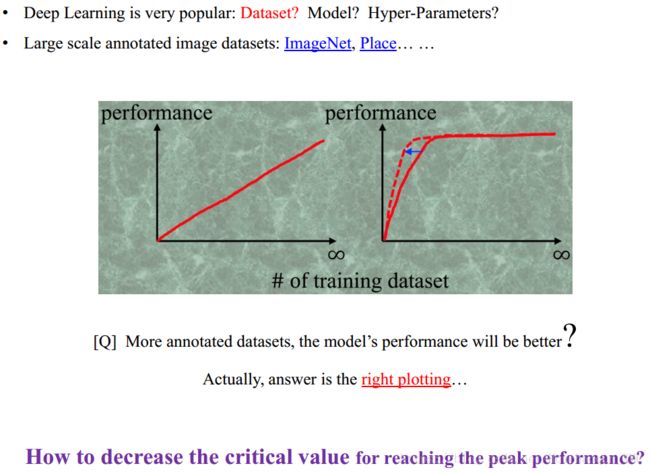
因此,业务方可以先挑选一定量的数据进行标注,然后训练看看效果如何;性能不能达到预期效果的话,再增加标注样本,直到模型达到预测的效果。这个思路其实跟上述介绍的主动学习算法流程略相似,但却有实质上的区别。
1)一般情况下,业务方挑选样本的准则是随机挑选(相当于 random select),更理想一点的就是挑选一些人为觉得比较复杂的样本;
2)active learning 能够通过一些选择策略挑选出当前模型认为最难区分的样本给相关领域的专家进行标注;
综上,如果某一些实际业务需要手工标注数据,并且先思考完如下几个条件后,决定是否使用 Active Learning:
1)能够较方便的获取未标注的源数据,并且有相关领域的标注专家;
2)对于一些较复杂的任务,需要慎重考虑是否已有相关的算法或者模型能够解决,不然花费再多的标注数据也不一定能够达到预期的效果;
3)不同任务类型(如,分类、检测、NLP等等),想好要用什么样的指标衡量样本(hard sample or easy sample);
4)Last But Not Least:算法设计完成后,还要考虑如何设计一个完整的系统。比如,你需要提供一个接口,让专家把标注完成的数据传到到模型的输入端,后续有时间我也会仔细思考下这个问题。否则,到时候可能会照成时间上的浪费,虽然减少了标注代价。
就这样,我越来越发现 Active Learning 是个值得深入研究的领域(有趣,有应用价值),并着手收集关于 Active Learning 的 papers。首先去找一些关于Active Learning 算法综述类的文章[1-2],其中文献[1]是一位博生生根据其毕业论文整理而来的,全面的介绍了2007年以来 Active Learning 的发展历程,目前该论文更新至2010年,此外论文还提供了一个网址链接,在线更新相关的内容。文献[2]有中英文版本(我看的是中文版本)、篇幅较少,简要介绍了Active Learning的基本思想以及2012年关于 Active Learning 的一些最近研究成果、对Active Learning 算法进行分析,并提出和分析了有待进一步研究的问题。
2018年3月至今,我主要围绕 Active Learning 相关的论文进一步研究,我学习的方法是:1)精读有意义的论文;2)第一遍打印在纸上并做相应的笔记(单词意思、段落大意、想法);3)第二遍看电子版的论文,并根据自己的理解做一个相应的PPT,这样的方式既能更深刻的理解,又能整理出落地文档(方便后续回忆论文或者分享论文);4)能找到代码和数据集的就赶紧进行实验,不能找到代码但有数据集的视情况而定(论文中的很多数据集都没有),没有数据集的就理解算法就行了(可见数据在机器学习领域的重要地位)。
Some Tips and AL from CSDN
Active Learning 的学习过程中也遇到很多不懂的概念,比如“Membership Query Synthesis”每个单词都懂,连起来就不知道是什么意思了,需要根据实际场景去理解其含义。因此,我经常在网上搜索一些相关的资料,看看有没有前辈已经整理过类似的问题。惊讶的是,网上关于AL的资料很少,估计是AL被冷漠了一段时间了。但是最近几年的顶会都有一些关于AL的研究和应用。此处主要介绍一些来自于CSDN的资料(给我的最大帮助就是发现了一些论文),分享给大家。
“在实习的公司遇到大量的无标签数据怎么办,利用SVM进行Active Learning主动学习”是2017年的一篇博文,简要介绍了AL+SVM的应用,内容篇幅较少,但也分析了一些细节。还有几篇是围绕周志华等人在2014年关于AL的一篇论文“Active learning by querying informative and representative examples”[17]整理而来,如:博文简要文献[17]的主旨和一些AL的基本概念。文献[18]“A Deep Active Learning Framework for Biomedical Image Segmentation”发表在MICCAI 2017上,使用“Uncertainty estimation and similarity estimation”的主动选择策略应用在医疗图像分割领域(FCN模型),作者均来自美国圣母大学,Lin Yang,YizheZhang,Jianxu Chen 均为华人,博文对论文较详细的进行解读,还有一篇博文尝试对论文进行翻译。文献[19]“Multi-Class Active Learning by Uncertainty Sampling with Diversity Maximization”发表于IJCV-2014,提出了一种新的 Active Learning 方法 USDM,利用 seed set 和 active pool内的所有样本的数据结构,来解决小 seed set 情况下 uncertainty sampling 存在的问题。而且联合 diversity ,得到 batch mode 的算法结果。在 multi-class 内准确判断样本的信息量,从而能够让选择结果更加准确(这篇博文对论文进行了详细的解读,这位博主截止目前整理了1-6篇关于AL的博文),包括对文献[20]“Multi-criteria-based active learning for named entity recognition”的解读博文,这是multi-criteria 开山鼻祖的文章(一篇长文);这位博主很用心的整理并分享了相关知识,值得称赞。文献[13]“An MRF Model-Based Active Learning Framework for the Spectral-Spatial Classification of Hyperspectral Imagery”是从一篇2015年的CSDN博文找到,结合了马尔科夫随机场和active learning (AL)
Study Record: Active Learning
什么是主动学习(What is Active Learning):
作者 Burr Settles[1] 的文章《Active Learning Literature Survey》很详细的介绍了“什么是主动学习”- “主动学习是机器学习(更普遍的说是人工智能)的一个子领域,在统计学领域也叫查询学习、最优实验设计”(Active learning (sometimes called “query learning” or “optimal experimental design” in the statistics literature) is a subfield of machine learning and, more generally, artificial intelligence. )。“学习模块”和“选择策略”是主动学习算法的2个基本且重要的模块。主动学习通过“选择策略”主动从未标注的样本集中挑选部分(1个或N个)样本让相关领域的专家进行标注;然后将标注过的样本增加到训练数据集给“学习模块”进行训练;当“学习模块”满足终止条件时即可结束程序,否则不断重复上述步骤获得更多的标注样本进行训练。此外,主动学习算法有个关键的假设:“The key hypothesis is that if the learning algorithm is allowed to choose the data from which it learns—to be “curious,” if you will—it will perform better with less training”。
在机器学习领域中,根据是否需要样本的标签信息可分为“监督学习”和“无监督学习”。此外,同时利用未标注样本和标注样本进行机器学习的算法可进一步归纳为3类:半监督学习、直推式学习和主动学习 。文献[21]简要介绍了主动学习与半监督学习的异同点:“半监督学习和主动学习都是从未标记样例中挑选部分价值量高的样例标注后补充到已标记样例集中来提高分类器精度,降低领域专家的工作量,但二者的学习方式不同:半监督学习一般不需要人工参与,是通过具有一定分类精度的基准分类器实现对未标注样例的自动标注;而主动学习有别于半监督学习的特点之一就是需要将挑选出的高价值样例进行人工准确标注。半监督学习通过用计算机进行自动或半自动标注代替人工标注,虽然有效降低了标注代价,但其标注结果依赖于用部分已标注样例训练出的基准分类器的分类精度,因此并不能保证标注结果完全正确。相比而言,主动学习挑选样例后是人工标注,不会引入错误类标 ”。
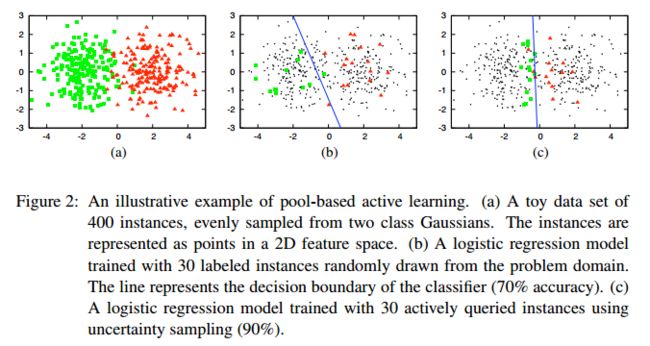
在一些复杂的监督学习任务中,获取标注样本是非常困难:既耗时,而且代价昂贵。如,语音识别(Speech recoginition)、信息提取(Information extraction)、分类和聚类(Classification and filtering)等。主动学习系统尝试解决样本的标注瓶颈,通过主动选择一些最有价值的未标注样本给相关领域的专家进行标注(Active learning systems attempt to overcome the labeling bottleneck by asking queries in the form of unlabeled instances to be labeled by an oracle)。如下图所示,文献[1]展示了一个基于 pool-based(下文会详细介绍)的主动学习案例,数据集(toy data)是从高斯分布产生的400个样本,任务是2分类问题(每个类有200个样本),如(a)图所示将这些数据映射在2D特征空间上;图(b)使用了逻辑回归模型,通过训练随机选择的30个标注样本,得到70%的验证精度,蓝色线表示决策边界(decision boundary);图(c)同样使用逻辑回归模型,但训练的30个标注样本是通过主动学习(US策略)选择而来,达到90%的验证精度。这个简单的案例体现了引入主动学习算法所带来的效果,同样使用30个标注样本能够提升20%的精度。一点值得注意的是,上述2分类的样本分别200个,样本数据非常平衡。但是在现实生活中,分类样本数据比例往往不能达到1:1,也有一些相关的研究尝试去解决这类问题。
主动学习作为一种新的机器学习方法,其主要目标是有效地发现训练数据集中高信息量的样本,并高效地训练模型。与传统的监督方法相比,主动学习具有如下优点:能够很好地处理较大的训练数据集,从中选择有辨别能力的样本点,减少训练数据的数量,减少人工标注成本[2]。
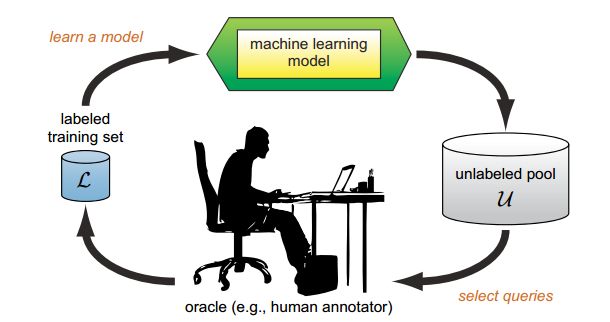
如下图所示为常见的主动学习流程图,属于一个完整的迭代过程,模型可以表示为 A = (C, L, S, Q, U)。其中C表示分类器(1个或者多个)、L表示带标注的样本集、S表示能够标注样本的专家、Q表示当前所使用的查询策略、U表示未标注的样本集。流程图可解释为如下步骤(以分类任务为例):
(1)选取合适的分类器(网络模型)记为 current_model 、主动选择策略、数据划分为 train_sample(带标注的样本,用于训练模型)、validation_sample(带标注的样本,用于验证当前模型的性能)、active_sample(未标注的数据集,对应于ublabeled pool);
(2)初始化:随机初始化或者通过迁移学习(source domain)初始化;如果有target domain的标注样本,就通过这些标注样本对模型进行训练;
(3)使用当前模型 current_model 对 active_sample 中的样本进行逐一预测(预测不需要标签),得到每个样本的预测结果。此时可以选择 Uncertainty Strategy 衡量样本的标注价值,预测结果越接近0.5的样本表示当前模型对于该样本具有较高的不确定性,即样本需要进行标注的价值越高。
(4)专家对选择的样本进行标注,并将标注后的样本放至train_sapmle目录下。
(5)使用当前所有标注样本 train_sample对当前模型current_model 进行fine-tuning,更新 current_model;
(6)使用 current_model 对validation_sample进行验证,如果当前模型的性能得到目标或者已不能再继续标注新的样本(没有专家或者没有钱),则结束迭代过程。否则,循环执行步骤(3)-(6)。
主动学习的问题场景(Scenarios of Active Learning):
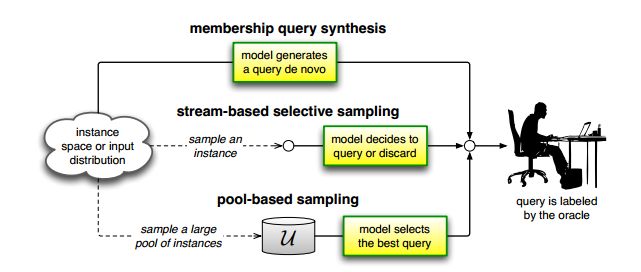
截至2010年,已经有很多不同的 Problem Scenarios 能够使用学习模型主动选择样本让专家进行标注。如下图所示,文献[1]主要提供了下列3种 Scenarios:
1)Membership Query Synthesis:文献“D. Angluin. Queries and concept learning. Machine Learning, 2:319–342, 1988”研究了第一个主动学习场景“membership queries”,学习器能够在输入空间中为未标注数据集申请标签,包括“queries that the learner generates de novo ”,而不是这些来自于同一个潜在分布的样本。有效的“query synthesis”在解决特定领域的问题通常比较易于处理和高效,如文献“D. Angluin. Queries revisited. In Proceedings of the International Conference on Algorithmic Learning Theory, pages 12–31. Springer-Verlag, 2001.”。文献“D. Cohn, Z. Ghahramani, and M.I. Jordan. Active learning with statistical models. Journal of Artificial Intelligence Research, 4:129–145, 1996.”把“synthesizing query”问题转化为回归学习任务,比如以机械手臂作为模型输入,学习如何预测一个机器人的手的关节角度的绝对坐标。
“Query Synthesis”能够很合理应用到很多领域的问题,但如果主动学习的专家环节是人工的话,标注任意样本这项工作往往很不合适(awkward)。例如,文献“K. Lang and E. Baum. Query learning can work poorly when a human oracle is used. In Proceedings of the IEEE International Joint Conference on Neural Networks, pages 335–340. IEEE Press, 1992. ”使用“membership query learning with human oracles”的模式训练一个神经网络模型对手写体字母进行分类,遇到一个意外的问题:通过学习器生成的许多 query images 都不包含可识别的符号(recognizable symbols),伪造的混合字符没有语义(semantic meaning)。同样地,当“membership queries”应用到 NLP 任务时可能会产生一些相当于乱语的文本或者语音的数据流(streams of text or speech)。因此提出了基于数据流和基于池的方法(stream-based and pool-based scenarios)来解决上述问题。然而,也有文献King et al. (2004, 2009) 提出了一个创新性和有前景的真实案例,此处不做详细介绍。
2)Stream-Based Selective Sampling ||| Sequential active learning:
Stream-Based Selective Sampling 有一个重要的前提假设:可以免费或者便宜的获取相关领域的未标注样本,因此就能够从真实的分布采集未标注的数据,然后学习器能够决定是否选择这些未标注样本让专家标注。如果输入样本属于 uniform distribution,选择性采样(selective sampling)可能跟 membership query learning 的效果一样好。然而,如果输入样本的分布是 non-uniform 或者连分布是什么都不知道的情况下,作者[1]证实了
文献[21]对“基于流的样例选择策略”是这样描述的:基于流的策略依次从未标注样例池中取出一个样例输入到选择模块,若满足预设的选中条件则对其进行准确的人工标注,反之直接舍弃。该学习过程需要处理所有未标记样例,查询成本高昂。另外,由于基于流的样例选择策略需要预设一个样例标注条件,但该条件往往需要根据不同的任务进行适当调整,因此很难将其作为一种通用方法普遍使用。
3)Pool-Based Sampling:
文献[21]对“基于池的样例选择策略”是这样描述的:基于池的方法每次从系统维护的未标注样例池中按预设的选择规则选取一个样例交给基准分类器进行识别,当基准分类器对其识别出现错误时进行人工标注。相较基于流的方法,基于池的方法每次都可选出当前样例池中对分类贡献度最高的样例,这既降低了查询样例成本,也降低了标注代价,这使得基于池的样例选择策略广泛使用。基于池的样例选择标准主要包括:不确定性标准、版本空间缩减标准、泛化误差缩减标准等。
分类问题的启发式方法(也属于选择/查询策略):
基于委员会的主动学习算法(QBC):熵值装袋查询(EBQ)、自适应不一致最大化(AMD)
在 QBC 算法中,使用标记样本训练多个参数不同的假设模型,并用于预测未标记的样本。因此,QBC算法需要训练一定数量的分类器,在实际应用中,其计算复杂度相当大。为了约束计算量,使用EQB方法简化计算。针对高维数据的情形,AMD算法能够将特征空间划分为子空间,它是 EQB算法的变形,不同的分类方法将相同的样本分类在不同的区域中,在计算过程中避免了维数灾难的问题。该算法优点:分类器可以使用多种分类模型以及组合模式,如:神经网络,贝叶斯法则等等。
基于边缘的主动学习算法(MS):边缘抽样、基于多层不确定性抽样、基于空间重构的抽样
对于边缘的启发式方法而言,主要针对支持向量机的情形。根据分类模型计算出样本到分类界面的距离选择样本。在 MS算法中,仅仅选择距离分类界面最近的样本加入训练集,它是最简单的边缘抽样的方法。而在 MCLU 算法中,与 MS 不同之处在于:选择离分类界面最远的两个最可能的样本的距离差值作为评判标准。在混合类别区域中,MCLU能够选择最不确信度的样本,而MS的效果不佳。在某些情形下,MS和 MCLU都会选出冗余的样本,引入多样性准则,剔除相似的样本,减少迭代的次数。常用的多样性准则采用样本间相似度,即样本间的相似度越高,说明样本所反映的数据特点越一致,则需要剔除该样本,反之,相似度越低。可以使用相似系数值来刻画样本点性质的相似性。
基于后验概率的主动学习算法(PP):Kullback-Leibler最大化、Breaking Ties算法
基于概率的启发式方法依赖于样本的后验概率分布形式,所以该方法的计算速度最快。KL方法的不足之处在于:在迭代优化过程中,它每次只能选择一个样本,增加了迭代的次数。此外,如果分类模型不能提供准确的概率评估值,它依赖于之后的优化评估值。而在 BT 算法中,其思想类似于 EQB,在多分类器中,选择样本两个最大概率的差值作为准则。当两个最大的概率很接近时,分类器的分类确性度最低。
查询策略(Query Strategy):
Random Sampling(RS):随机选择样本
Uncertainty Sampling(US):选择当前模型认为最不确定的样本(如,分类问题,概率为0.5表示对该样本模棱两可,不确定性很高),标注这类样本对提升当前模型最有帮助,US也是主动学习领域最常用的策略之一。但是很少有人仅仅只用这种策略选择样本,其原因在于:US 策略仅仅考虑单个样本的信息,没有考虑样本空间整体的分布情况,因此会找到 outlier 样本,或者一些冗余的样本。比如文献[3]结合了 US 和 diversity(能够保证 batch-mode 的选择样本具有比较大的多样性)。
Kapoor[16]:An algorithm that balances exploration and exploitation by incorporating mean and variance estimation of the GP classifier.
ALBE[14]:A recent example of meta-AL that adaptively uses a combination of strategies, including [15].
主动学习相关的论文(Relevant paper with Active Learning)
文献[1]“Active Learning Literature Survey”详细的对主动学习展开介绍,篇幅较长。文献[2]“Survey on active learning algorithms”是一篇幅较短的中文论文,主要围绕主动学习的基本思想和截至2012年最新的研究成果,并对相关算法进行分析,总结了有待进一步研究的问题,包括:1)结合非监督学习算法,取代专家标注的环节;2)维度灾难:在预处理阶段寻找高效的降维方法,减少主动查询过程的复杂度。文献[3]“Fine-Tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally”是一篇发表于CVPR-2017的论文,使用Active Learning + Transfer Learning、Data Augmentation、Majority Selection、Continuously Fine-Tuning等方法在3个医疗图像领域的数据集上验证了引入主动选择的策略(entropy+diversity)能够至少减少一半的数据标注代价。文献[4]“Generative Adversarial Active Learning”首次将GAN与Active Learning进行组合,通过训练GAN得到生成器模型,主动生成最有价值的样本让专家进行标注。文献[5]“Learning Active Learning from Data”跟传统的主动选择策略有本质上的区别,它克服了手工设计的选择策略跨领域泛化能力的不足,通过将主动选择策略转化为回归问题进行学习,学习得到的策略在多个不同领域的真实数据集(Striatum、MRI、Credit Card、Splice、Higgs)上取得显著的效果。文献[6]"Just Sort It! A Simple and Effective Approach to Active Preference Learning",还未仔细读。文献[21]“主动学习算法研究进展”于2017年发表在河北大学学报的一篇中文论文(个人觉得看了这篇论文还是有所收获的),围绕主动学习的3个关键步骤(学习器初始化、选择策略、算法的终止条件)展开详细的介绍,并总结了主动学习面临的问题及其对应的改进方法。
以上简要介绍了一些关于AL的论文,后续有时间的话再针对一些有意义的论文进行详细的理解并整理分享给大家。
主动学习领域的难点汇总:
- 多类分类问题:在处理多类分类问题时,基于 Margin Sampling 的样例选择标准忽略了样例可能属于其他类别的信息,因此所选样例质量较差。基于熵的方法“基于不确定性的主动学习算法研究(2011)”虽考虑了样例从属于每个类别的概率,但在多类分类问题中,样例的熵也会受到那些不重要类别的干扰。文献“Multi-class active learning for image classification(2009)”提出了基于最优标号和次优标号的准则(BvSB),考虑样例所属概率最高的前2个类别,忽略剩余类别对样例选择标准产生的干扰。文献“基于主动学习和半监督学习的多类图像分类(2011)”将BvSB和带约束的自学习(Constrained self-training,CST)引入到基于SVM的图像分类中,显著提高了分类精度。
- 样本中的孤立点:若选择样例时能综合考虑样其代表性(样本的先验分布信息,如聚类分析或样本密度分布分析)和不确定性(如,信息熵),通常可避免采集到孤立点。如文献“Active Learning by querying informative and representative examples(2010)”中提出了一种综合利用聚类信息和分类间隔的样例选择方法;文献“Active Learning using a Variational Dirichlet Processing model for pre-clustering and classification of underwater stereo imagery(2011)”提出了一种利用预聚类协助选择代表性样例的主动学习方法;文献“Dual strategy active learning(2007)”利用样例的不确定性及其先验分布密度进行样例选择以获取优质样例;文献“基于样本不确定性和代表性相结合的可控主动学习算法研究 (2009)”将样例的分布密度作为度量样例代表性的指标,结合以熵作为不确定性指标,提出了一种基于密度熵的样例选择策略,有效解决了孤立点问题给样例选择质量造成的影响。
- 训练集样本冗余:
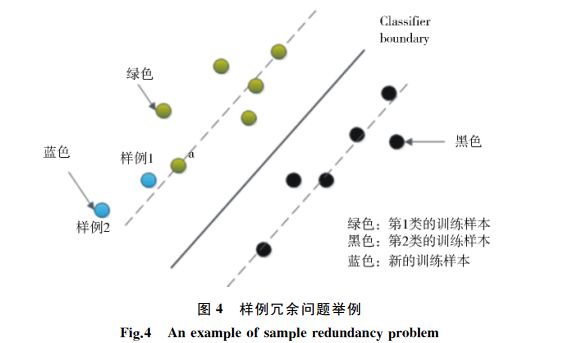 新的训练样本中样例1与分类超平面的距离比样例2近,根据 BvSB 准则应当挑选样例1进行标注并补充到训练集中;但紧挨着样例1的绿色样例 a 已经在训练集中,此时若再加入样例1则对分类界面影响甚微。相比而言,将样例2补充到训练集中,对当前分类模型的训练贡献度更大。通过上述分析可知,主动学习中的样例选择度量主要分为2种:1)不确定性度量;2)差异性度量或代表性度量。样例的不确定性一般可通过计算其信息熵获得,样例的代表性通常可根据其是否在聚类中心判断,而样例的差异性则可通过计算余弦相似度(基于采样策略的主动学习算法研究进展,2012)或用高斯核函数(基于多特征融合的中文评论情感分类算法,2015)获得。
新的训练样本中样例1与分类超平面的距离比样例2近,根据 BvSB 准则应当挑选样例1进行标注并补充到训练集中;但紧挨着样例1的绿色样例 a 已经在训练集中,此时若再加入样例1则对分类界面影响甚微。相比而言,将样例2补充到训练集中,对当前分类模型的训练贡献度更大。通过上述分析可知,主动学习中的样例选择度量主要分为2种:1)不确定性度量;2)差异性度量或代表性度量。样例的不确定性一般可通过计算其信息熵获得,样例的代表性通常可根据其是否在聚类中心判断,而样例的差异性则可通过计算余弦相似度(基于采样策略的主动学习算法研究进展,2012)或用高斯核函数(基于多特征融合的中文评论情感分类算法,2015)获得。 - 不平衡数据集:文献“一种新的SVM主动学习算法及其在障碍物检测中的应用(2009)”提出 KSVMactive 主动学习算法;文献“基于主动学习的加权支持向量机的分类(2009)”提出了改进的加权支持向量机模型;文献“基于专家委员会的主动学习算法研究(2010)”提出了基于SVM超平面位置校正的主动学习算法。
总结和展望
1)主动学习早在90年代的时候就已经有人在研究了,但好像未能达到风靡一时的效果,可能是缺失某些致命条件(如,数据和计算能力)。随着大数据时代的到来以及计算能力的突飞猛进,深度学习在学术界和工业界取得了巨大的成就。深度学习的各种成绩也同时给很多领域带来可能,近几年主动学习又开始在学术界蠢蠢欲动,结合深度学习使得主动学习在一定程度上突破了瓶颈,在一些领域取得了不错的成绩(主要用来减少标注代价)。
2)主动学习的关键在于“select strategy”,目前主要是一些手工设计的策略,一种选择策略仅仅能够应用于某些特定的领域,类似于机器学习的手工设计特征。某种相似的套路:针对手工设计特征的局限性,(分类任务)深度学习将特征选择和分类器结合,不再需要为分类器输入手工设计的特征,取得了质的飞跃;同样的,文献[5]“Learning Active Learning from Data”通过学习得到的“select strategy”能够同时应用到多个不同的领域,克服了手工设计的选择策略跨领域泛化能力的不足。个人感觉,主动学习领域还是有很多方面可以尝试的,毕竟如果做好了,确实能够给实际业务带来价值。
3)本文的实验环节也仅限于使用一些简单的“select strategy”,希望今后有时间能够想出更厉害的策略。
参考文献(Reference)
(参考文献的排列顺序以本人对论文的阅读精细程度进行排序)
- Krishnakumar A. Active Learning Literature Survey[J]. 2007.
- Liu K, Qian X. Survey on active learning algorithms[J]. Computer Engineering & Applications, 2012.
- Zhou Z, Shin J, Zhang L, et al. Fine-Tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2017:4761-4772.
- Zhu J J, Bento J. Generative Adversarial Active Learning[J]. 2017.
- Konyushkova K, Sznitman R, Fua P. Learning Active Learning from Data[J]. 2017.
- Maystre L, Grossglauser M. Just Sort It! A Simple and Effective Approach to Active Preference Learning[J]. Computer Science, 2017.
- Chu H M, Lin H T. Can Active Learning Experience Be Transferred?[C]// IEEE, International Conference on Data Mining. IEEE, 2017:841-846.
- Chen L, Hassani H, Karbasi A. Near-Optimal Active Learning of Halfspaces via Query Synthesis in the Noisy Setting[J]. 2016.
- Huijser M W, Van Gemert J C. Active Decision Boundary Annotation with Deep Generative Models[J]. 2017:5296-5305.
- Wang X, Huang T, Schneider J. Active Transfer Learning under Model Shift[C]// International Conference on Machine Learning. 2014:1305-1313.
- Baram Y, El-Yaniv R, Luz K. Online Choice of Active Learning Algorithms.[J]. Journal of Machine Learning Research, 2004, 5(1):255-291.
- Schein A I, Ungar L H. Active learning for logistic regression: an evaluation[J]. Machine Learning, 2007, 68(3):235-265.
- Sun S, Zhong P, Xiao H, et al. An MRF Model-Based Active Learning Framework for the Spectral-Spatial Classification of Hyperspectral Imagery[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 9(6):1074-1088.
- W.-N. Hsu, , and H.-T. Lin. Active learning by learning. American Association for Artificial Intelligence Conference, pages 2659–2665, 2015.
- Sheng jun Huang, Rong Jin, and Zhi hua Zhou. Active learning by querying informative and representative examples. In J. D. Lafferty, C. K. I. Williams, J. Shawe-Taylor, R. S. Zemel, and A. Culotta, editors, NIPS, pages 892–900. Curran Associates, Inc. 2010.
- A. Kapoor, K. Grauman, R. Urtasun, and T. Darrell. Active Learning with Gaussian Processes for Object Categorization. In International Conference on Computer Vision, 2007.
- Huang S J, Jin R, Zhou Z H. Active Learning by Querying Informative and Representative Examples[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 36(10):1936-1949.
- Yang L, Zhang Y, Chen J, et al. Suggestive Annotation: A Deep Active Learning Framework for Biomedical Image Segmentation[J]. 2017:399-407.
- Yang Y, Ma Z, Nie F, et al. Multi-Class Active Learning by Uncertainty Sampling with Diversity Maximization[J]. International Journal of Computer Vision, 2015, 113(2):113-127.
- Shen D, Zhang J, Su J, et al. Multi-criteria-based active learning for named entity recognition[C]// Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2004:589.
- 杨文柱, 田潇潇, 王思乐,等. 主动学习算法研究进展[J]. 河北大学学报(自然科学版), 2017, 37(2):216-224.