Python requests爬虫实例
操作系统:Windows
Python:3.5
欢迎加入学习交流QQ群:657341423
需要用到的库:
requests
wxPython
docx
win32api需要安装pywin32
解释:
requests这个用来做爬虫,基本上不用多作解释
wxPython和win32api主要生成软件的操作界面,给用户使用。
docx主要将爬取的结果,用word显示出来。
网页分析:
这里以南方日报每天的报纸为例:请点击
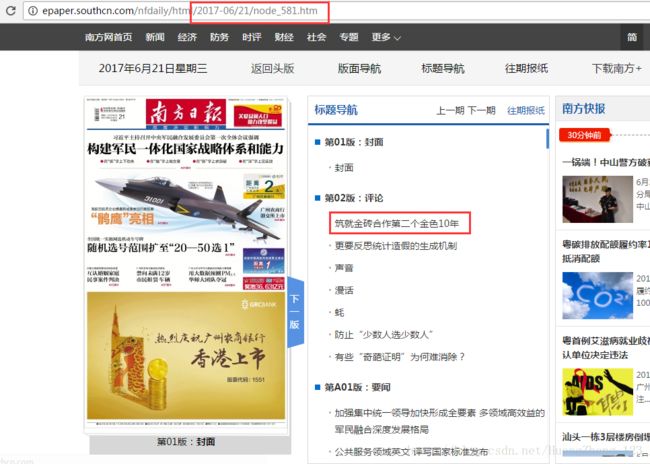
可以看到,url后面是一个日期和node为尾的,日期就代表当天的报纸,node是报纸的首页,看到下面红色标记的是每篇新闻的标题,点开标题看到

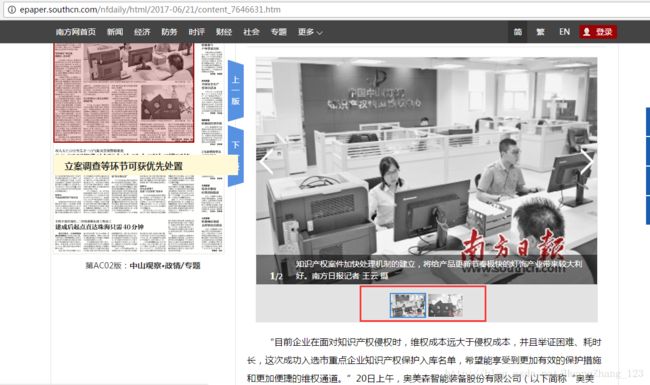
点开标题后,看到新的url,日期和一个content为尾的。content是代表每篇新闻的详细报道。下面红色标记的是我们需要的正文。
当然,有时候会附带一些图片的,而且是会有多张图片。如:
设计思路:
以http://epaper.southcn.com/nfdaily/html/2017-06/21/node_581.htm 开始。
然后获取这个html里面的带有content的url链接。
再通过获取的url组合成每篇新闻报道的url,然后获取这些url的正文内容,标题和图片。
分析node网页的标题url
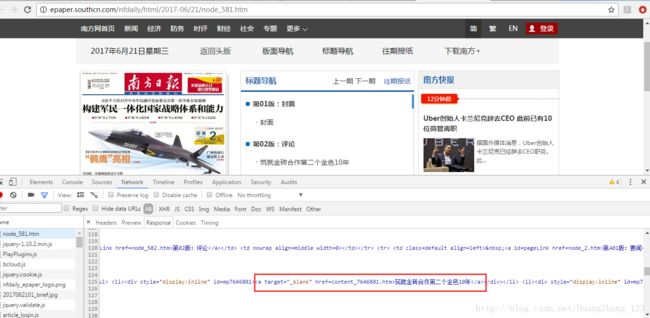
可以发现,每个标题都是这样的格式。
再分析content网页的正文和标题,图片。
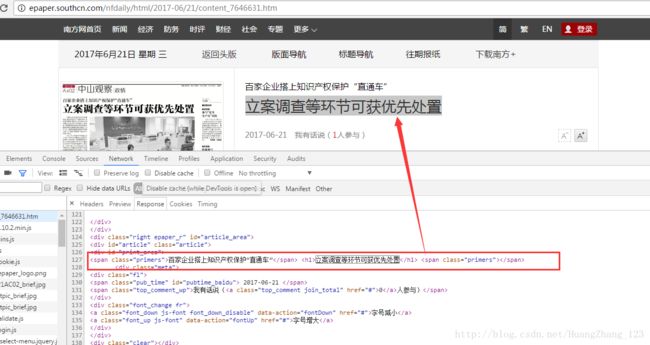

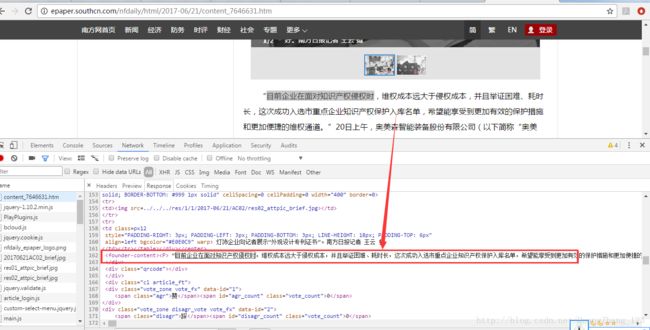
总的来说,就是在node这个网页,获取每篇新闻详细信息的url,而且这些url带有content的,然后循环访问这些url,获取每篇新闻的标题,正文和图片即可实现。
实现代码:
#爬虫库
from bs4 import BeautifulSoup
import requests
import queue
import re
#读写word
from docx import Document
from docx.shared import Inches
from io import StringIO
#界面设计
import os
import wx
import win32api
import win32con
import win32gui
def mkdir(path):#判断是否有文件夹,没则新建
path=path.strip()
path=path.rstrip("\\")
isExists=os.path.exists(path)
if not isExists:
os.makedirs(path)
return True
else:
return False
PicSavePath=os.getcwd()+"\\news"
mkpath=PicSavePath
mkdir(mkpath)
class MyFrame(wx.Frame):
def __init__(self, parent, title):
super(MyFrame, self).__init__(parent, title = title, size = (500, 350))
self.InitUI()
self.Centre()
self.Show()
def InitUI(self):
panel = wx.Panel(self)
hbox = wx.BoxSizer(wx.HORIZONTAL)
fgs = wx.FlexGridSizer(4, 2, 10,10)
Sort = wx.StaticText(panel, label = "年 份")
sale = wx.StaticText(panel, label = "月 份")
keys = wx.StaticText(panel, label = "关键字")
self.tc1 = wx.ComboBox(panel,value="年份",choices=["2016","2017"])
self.tc2 = wx.ComboBox(panel,value="月份",choices=["1","2","3","4","5","6","7","8","9","10","11","12"])
self.tc3 = wx.TextCtrl(panel, style = wx.TE_MULTILINE)
bt1=wx.Button(panel,label = "查询")
bt2=wx.Button(panel,label = "清除")
fgs.AddMany([(Sort), (self.tc1, 1, wx.EXPAND), (sale),
(self.tc2, 1, wx.EXPAND), (keys, 1, wx.EXPAND), (self.tc3, 1, wx.EXPAND),(bt1),(bt2)])
fgs.AddGrowableRow(2, 1)
fgs.AddGrowableCol(1, 1)
hbox.Add(fgs, proportion = 2, flag = wx.ALL|wx.EXPAND, border = 15)
panel.SetSizer(hbox)
bt1.Bind( wx.EVT_BUTTON, self.query )
bt2.Bind( wx.EVT_BUTTON, self.cleanValue )
def cleanValue(self,event):
self.tc1.ChangeValue('年份')
self.tc2.ChangeValue('月份')
self.tc3.Clear()
def dowloadPic(self,imageUrl,filePath):
r = requests.get(imageUrl)
with open(filePath, "wb") as code:
code.write(r.content)
def query(self,event):
queryyear=self.tc1.GetValue().strip()
KeyValue=self.tc3.GetValue().strip()
if KeyValue:
Keylist=KeyValue.split('\n')
else:
Keylist=['南海区专利代理人培训','专利管理师','南海区专利代理行业自律公约','南海区专利特派员','知识产权投融资对接会','科技服务业集聚区',
'专利质押融资','rttp','南海区荣获中国专利奖','知识产权优势示范企业','知识产权日系列活动','南海基地']
if queryyear.isdigit()==False:
win32api.MessageBox(0,'请选择年份', '提示',win32con.MB_ICONASTERISK|win32con.MB_OKCANCEL)
else:
#获取全年的新闻
for i in range(12):
for k in range(31):
#设置日期的月日格式
if len(str(i+1))==1:
month="0"+str(i+1)
else:
month=str(i+1)
if len(str(k+1))==1:
day="0"+str(k+1)
else:
day=str(k+1)
#生成日期
dateDay=queryyear+"-"+month+'/'+day
print(dateDay)
self.queryDay(dateDay,Keylist)
win32api.MessageBox(0,'数据采集完成', '提示',win32con.MB_ICONASTERISK|win32con.MB_OKCANCEL)
def queryDay(self,dateDay,Keylist):
try:
urlList=[]
PicUrl=[]
#获取每天的报纸里面每篇新闻的url
papgedate=dateDay
url='http://epaper.southcn.com/nfdaily/html/%s/node_2.htm' %papgedate
r=requests.get(url)
soup=BeautifulSoup(r.content.decode("utf-8"),"html.parser")
temp=soup.find_all('div',id='btdh')[0]
herfList=temp.find_all('a',href=re.compile("content"))
for i in herfList:
StarIndex=re.search('href=',str(i)).span()[1]
EndIndex=re.search('target',str(i)).span()[0]
tempValue=str(i)[StarIndex:EndIndex].replace('"','').strip()
if tempValue:
urlList.append(tempValue)
urlList=sorted(set(urlList))
for i in urlList:
url='http://epaper.southcn.com/nfdaily/html/%s/%s' %(papgedate,i)
r=requests.get(url)
#获取每篇新闻的标题和正文
soup=BeautifulSoup(r.content.decode('utf-8'),"html.parser")
title=soup.find_all('div',id='print_area')[0].find_all('h1')[0].getText()
ContentText=soup.find_all('founder-content')[0].getText()
PicList=soup.find_all('div',id='print_area')[0].find_all('img',src=re.compile('/res/'))
#关键字筛选
Mycontent=False
for kw in Keylist:
if kw in title:
Mycontent=True
elif kw in ContentText:
Mycontent=True
if Mycontent:
for j,k in enumerate(PicList):
StarIndex=re.search('/res',str(k)).span()[0]
EndIndex=re.search('"/>',str(k)).span()[0]
tempValue=str(k)[StarIndex:EndIndex].replace('"','').strip()
imageUrl='http://epaper.southcn.com/nfdaily'+tempValue
self.dowloadPic(imageUrl,i.replace('.','')+"_"+str(j)+".jpg")
PicList[j]=i.replace('.','')+"_"+str(j)+".jpg"
#写入word
document = Document()
document.add_heading(title, 0)
document.add_paragraph(ContentText)
for p in PicList:
document.add_picture(p, width=Inches(1.25))
os.remove(p)
document.save('news//'+title.strip()+'.docx')
except Exception as e:
pass
app = wx.App()
MyFrame(None, title = 'XyJw')
app.MainLoop()
代码设计思路:
1.代码运行会生成一个用户操作界面,用户可以选择年份和输入关键字对新闻进行筛选,(这里的月份还没做相应的开发。)目前只是做了爬取一年里面的全部新闻,然后将每篇新闻的标题和正文和关键字对比,如果含有关键字的,会爬取下来生成word。如果关键字不输入数据,会默认程序里面的关键字进行筛选。
2.在年份设置那里,我是默认每个月都是31日的,如果当月不存在31日的,在queryDay里面会跳到Exception不作处理。
运行结果:
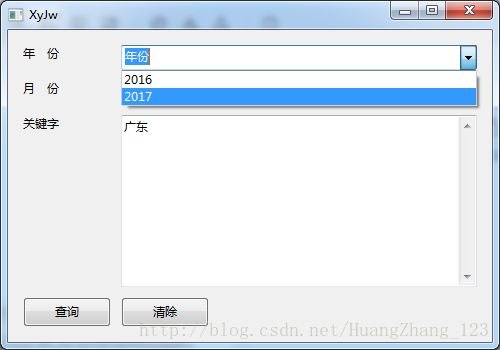

这里是爬取含义广东为关键字的新闻。
扩展和优化
- 在这里,我们会发现,网页的爬取速度很慢。毕竟循环的次数比较多。而且很受网速的影响。
- 对于上述代码,可以做优化,最外的循环,是每次生成一个日期,然后再爬取,这里可以用多线程方法,一次爬取2天或者3天的数据,如果是一次2天数据,按一个月32天计算,就是循环16次即可。
- 关键字优化,如果要更加精准地获取新闻信息,这里可以自然语言处理方法。
这里介绍一个现有的方法,就是用百度的现有自然语言处理方法:请点击
当然也可以自己编写,具体自行百度。