xxl-job分布式任务调度项目搭建(单机部署demo)
今天学习了一下分布式任务开源项目xxl-job,然后自己在本地“搭建”了一个单机的任务项目。
写了一个定时任务,每分钟向数据库中添加一条数据,很简单的项目,大家可以通过该项目作为xxl-job的入门小试。
先介绍一下大致是怎样的吧:
第一部分,xxl-job作为一个单独的项目,需要部署在tomcat上面,当然是进行一些简单的配置之后。
第二部门,是我单独创建了一个springboot项目,定义了一个简单的任务,实现每分钟向数据库中插入一条数据。当谈也是需要进行一下简单的配置,然后用tomcat启动。
最后通过访问xxl-job的admin界面,进行执行器的配置和任务的配置。
一、先把xxl-job搞一下
1、直接去xxl-job的网站克隆源码 http://www.xuxueli.com/xxl-job/#/
我是下载的第一个,下面看一下需要修改的配置文件:
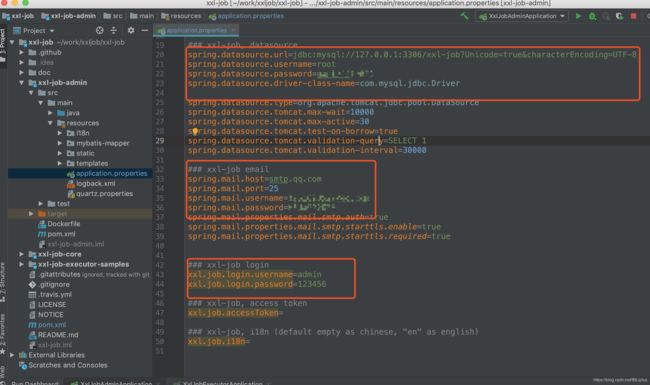
配置的地方 数据源 邮箱 login设置(默认不变)
xxl-job项目就算弄完了,然后直接用IDE启用,启动方式是tomcat,或者直接把项目打包部署tomcat也可以。
然后xxl-job是有自己的数据库的,在项目的doc文件中有两个sql文件,大家直接在本地数据库执行就可以了。
userinfo是我下面demo项目需要的表,xxl-job数据库是其自带的数据库,有16张表。
二、新创建springboot项目demo
大家可以看一下项目大致的目录

这里面我使用了generator插件进行反向生成,大家可以配置一下,很简单的。然后就是配置xxl-job了。
先看一下配置文件application.yml (我是用的是格式更加简洁明了的yml格式的文件,大家也可以使用properties格式的文件,都一样,只不过格式不一样)
server:
port: 8080
spring:
datasource:
name: test
url: jdbc:mysql://127.0.0.1:3306/test
username: root
password: gaoleif1e629
driver-class-name: com.mysql.jdbc.Driver
mybatis:
mapper-locations: classpath:mapping/*Mapper.xml
type-aliases-package: com.example.pojo
xxl:
job:
admin:
#调度中心部署跟地址:如调度中心集群部署存在多个地址则用逗号分隔。
#执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调"。
addresses: http://127.0.0.1:8081/xxl-job-admin
#分别配置执行器的名称、ip地址、端口号
#注意:如果配置多个执行器时,防止端口冲突
executor:
logpath: /data/apps/logs/demo
appname: xxl-job-demo
ip: 127.0.0.1
port: 8082
accessToken:
#执行器运行日志文件存储的磁盘位置,需要对该路径拥有读写权限
#执行器Log文件定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保持3天,否则功能不生效;
#-1表示永不删除
然后看一下通过一个java配置类来获取我们配置的属性:
@Configuration
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String addresses;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logpath;
@Value("${xxl.job.accessToken}")
private String accessToken;
/*@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;*/
@Bean(initMethod = "start", destroyMethod = "destroy")
public XxlJobExecutor xxlJobExecutor() {
System.err.println(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(addresses);
xxlJobSpringExecutor.setAppName(appname);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logpath);
return xxlJobSpringExecutor;
}
}我在这里遇到一个坑,浪费了好长的时间,分享给大家
xxl-job 分布式任务调用 jobhandler【xxxhandler】 not found
然后看一下我的job类,他是继承了IJobHandler类,重写的execute方法
@JobHandler("demouserinfoinsertJobHandler")
@Component
public class UserInfoJobHandler extends IJobHandler {
@Resource
private UserInfoService userInfoService;
@Override
public ReturnT execute(String s) throws Exception {
System.err.println(">>>>>>>>>>>>>>>> 执行方法 ");
UserInfo userInfo = UserInfo.builder()
.username("haha")
.phone("13730175343")
.gmtCreate(new Date())
.sex("N")
.build();
userInfoService.insert(userInfo);
return ReturnT.SUCCESS;
}
}
这里我的项目创建的很简单,日志什么的都没有配置,大家之后如果需要的话,可以自己配置一下。到这里demo项目页配置完了,然后启动springboot项目接可以了。
三、添加执行器
按照xxl-job的官方文档介绍,我们第一个xxl-job项目启动之后,我们可以访问admin调度中心了,如下:

下面是我访问的我启动的xxl-job项目
先配置执行器:
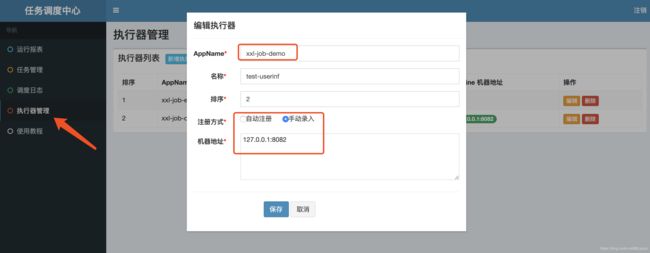
上面的AppName要和demo项目中的application.yml中的一致。名称做到见名知义即可。注册方式我是手动录入的,端口和yml文件中的executor的端口号保持一样!然后保存就添加执行器了。
四、新建任务并配置

下面看一下官方文件对于各个配置参数的介绍:
- 执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 "执行器管理" 进行设置;
- 任务描述:任务的描述信息,便于任务管理;
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
- Cron:触发任务执行的Cron表达式;
- 运行模式:
BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 "JobHandler" 属性匹配执行器中任务;
GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 "groovy" 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "shell" 脚本;
GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "python" 脚本;
GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "php" 脚本;
GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "nodejs" 脚本;
GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "PowerShell" 脚本;
- JobHandler:运行模式为 "BEAN模式" 时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
- 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
- 负责人:任务的负责人;
- 执行参数:任务执行所需的参数;Cron用来配置任务如何执行,我是配置的一分钟执行一次;
最后启动任务即可
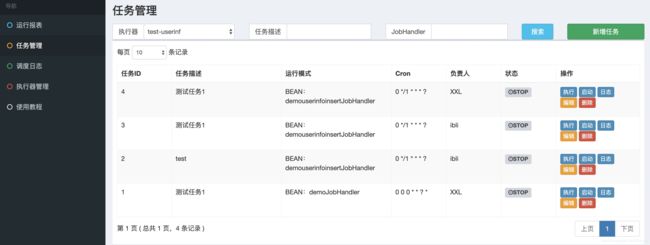
最后看一下数据库的执行结果吧:

⚠️先启动xxl-job项目,然后在启动demo项目。
有需要源码的可以底部留言,这个项目仅仅是实现了简单的定时任务,至于分布式任务调度,需要搭配集群,我这里就不演示了。大家工作中遇到和更加容易理解分布式任务与传统的定时任务的区别与优势。
大家可以看一下官方中文文档,讲解的还是很详细的。