Python 实现协同过滤算法
一、推荐系统
在信息暴涨的时代,每天大量的微博转载和创作,给用户不断更新信息的同时,也增加了用户筛选信息的难度,当用户有明确的需求时可以使用搜索引擎。但是在用户没有明确的需求时,只是为了打发时间,在微博中为了给用户筛选出他们感兴趣的信息,就要分析用户的兴趣,从海量的信息中选择与用户兴趣相似的信息,并将此推荐给用户。推荐系统(Recommendation System RS)被提出,推荐系统的任务就是能够链接信息和用户,帮助用户找到其感兴趣的信息,同时让一些有价值的信息能够触达到潜在的用户。
推荐算法是根据用户的历史行为,挖掘出用户的喜好,并为用户推荐与其喜好相符的商品或者信息。
推荐系统的核心问题是为用户推荐与其兴趣相似度比较高的商品。为此需要函数 f(x)计算候选商品与用户之间的相似度,并向用户推荐相似度比较高的商品。为了预测函数 f(x)可用的历史数据有:用户的历史行为数据、与该用户相关的其他用户信息,商品之间的相似性、文本的描述。
二、推荐的常用方法
- 协同过滤的推荐:主要依据的是用户或者项之间的相似性。
- 基于内容的推荐:主要依据的是推荐项的性质。
- 基于关联规则的推荐
- 基于效用的推荐
- 基于知识的推荐
- 组合推荐
三、基于协同过滤的推荐
1.协同过滤算法概述
协同过滤(Collaborative Filtering CF)推荐算法是通过在用户的行为中寻找特定的模式,并通过该模式为用户产生有效推荐,依赖于系统中用户的行为数据。
基于协同过滤的推荐算法的核心思想是:通过对用户的历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的项。在计算推荐结果的过程中,只与用户对项的评分有关。
2.协同过滤算法分类
- 基于项的协同过滤算法:主要依据的是项与项之间的相似性。
- 基于用户的协同过滤算法:主要依据的是用户与用户之间的相似性。
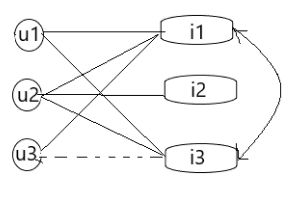
下图基于项的协同过滤算法中,用户 u1、u2、u3,与用户 u1 互动的商品有 i1,i2,与用户 u2 互动的商品有 i1,i2,i3,用户u3 互动的商品 i1。通过计算 i1,i3 商品相似,对于用户 u3 来说,用户 u1 互动过的 i3 用户 u3 为互动,所以为用户 u3 推荐商品 i3。
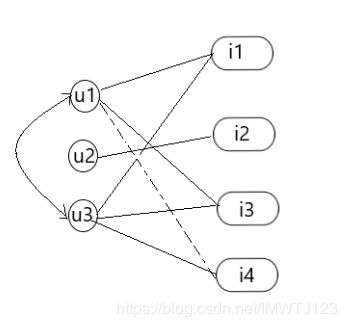
下图基于用户的协同过滤算法中,与用户 u1 互动的商品 i1,i3,用户 u2 互动的商品 i2,用户 u3 互动的商品 i1,i3,i4,。通过计算,用户 u1 和 u3 较为相似,对于用户 u1,用户 u3 互动过的商品 i4 使用户 u1 未互动过的,所以为用户 u1 推荐商品 i4。
四、相似度的度量方法
相似性的度量方法必须满足拓扑学中的度量空间的基本条件:
假设 d 是度量空间 M 上的度量:![]() , 其中度量 d 满足:
, 其中度量 d 满足:
- 非负性:
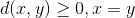 取等号
取等号 - 对称性:
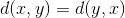
- 三角不等式:
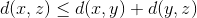
主要介绍三种度量方法: 欧氏距离、 皮尔逊相关系数、 余弦相似度
1.欧氏距离
在之前的K-Means算法中讲到过
2.皮尔逊相关系数
在欧氏距离的计算中,不同特征之间的量级对欧氏距离的影响比较大,而皮尔逊相关系数的度量方法对量级不敏感,其具体形式为:
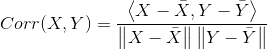
![]() 表示内积,
表示内积,![]() 表示向量X的范数。
表示向量X的范数。
3.余弦相似度
余弦相似度有着与皮尔逊相似度同样的性质,对量级不敏感,是计算两个向量的夹角。对于两个向量X和Y,对应的形式为:
![]()
五、协同过滤算法实现
我们将用户——商品数据转换为商品——用户矩阵,并计算商品之间的相似度。

基于项的协同过滤算法的商品之间的相似度:
0. 0.39524659 0.76346445 0.82977382 0.26349773
0.39524659 0. 0.204524 0.47633051 0.58823529
0.76346445 0.204524 0. 0.36803496 0.63913749
0.82977382 0.47633051 0.36803496 0. 0.
0.26349773 0.58823529 0.63913749 0. 0. 基于用户的协同过滤算法的商品之间的相似度 :
0. 0.74926865 0.32 0.83152184 0.25298221
0.74926865 0. 0.74926865 0.49559463 0.1579597
0.32 0.74926865 0. 0.30237158 0.52704628
0.83152184 0.49559463 0.30237158 0. 0.47809144
0.25298221 0.1579597 0.52704628 0.47809144 0. 1.基于项的协同过滤算法进行推荐
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 4 17:24:02 2019
@author: 2018061801
"""
import numpy as np
from user_based_CF import load_data, similarity
def item_based_recommend(data, w, user):
'''基于商品相似度为用户user推荐商品
input: data(mat):商品用户矩阵
w(mat):商品与商品之间的相似性
user(int):用户的编号
output: predict(list):推荐列表
'''
m, n = np.shape(data) # m:商品数量 n:用户数量
interaction = data[:,user].T # 用户user的互动商品信息
# 1、找到用户user没有互动的商品
not_inter = []
for i in range(n):
if interaction[0, i] == 0: # 用户user未打分项
not_inter.append(i)
# 2、对没有互动过的商品进行预测
predict = {}
for x in not_inter:
item = np.copy(interaction) # 获取用户user对商品的互动信息
for j in range(m): # 对每一个商品
if item[0, j] != 0: # 利用互动过的商品预测
if x not in predict:
predict[x] = w[x, j] * item[0, j]
else:
predict[x] = predict[x] + w[x, j] * item[0, j]
# 按照预测的大小从大到小排序
return sorted(predict.items(), key=lambda d:d[1], reverse=True)
def top_k(predict, k):
'''为用户推荐前k个商品
input: predict(list):排好序的商品列表
k(int):推荐的商品个数
output: top_recom(list):top_k个商品
'''
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])
return top_recom
if __name__ == "__main__":
# 1、导入用户商品数据
print ("------------ 1. load data ------------")
data = load_data("D:/anaconda4.3/spyder_work/data7.txt")
# 将用户商品矩阵转置成商品用户矩阵
data = data.T
# 2、计算商品之间的相似性
print ("------------ 2. calculate similarity between items -------------")
w = similarity(data)
# 3、利用用户之间的相似性进行预测评分
print ("------------ 3. predict ------------")
predict = item_based_recommend(data, w, 0)
# 4、进行Top-K推荐
print ("------------ 4. top_k recommendation ------------")
top_recom = top_k(predict, 2)
print (top_recom)
结果:
------------ 1. load data ------------
------------ 2. calculate similarity between items -------------
------------ 3. predict ------------
------------ 4. top_k recommendation ------------
[(2, 5.507604598998138), (4, 2.8186967825714824)]用户未打分的商品为2和4, 最终2号打分5.5,,4号打分2.8
2.基于用户的协同过滤算法进行推荐
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 4 17:32:21 2019
@author: 2018061801
"""
import numpy as np
def load_data(file_path):
'''导入用户商品数据
input: file_path(string):用户商品数据存放的文件
output: data(mat):用户商品矩阵
'''
f = open(file_path)
data = []
for line in f.readlines():
lines = line.strip().split("\t")
tmp = []
for x in lines:
if x != "-":
tmp.append(float(x)) # 直接存储用户对商品的打分
else:
tmp.append(0)
data.append(tmp)
f.close()
return np.mat(data)
def cos_sim(x, y):
'''余弦相似性
input: x(mat):以行向量的形式存储,可以是用户或者商品
y(mat):以行向量的形式存储,可以是用户或者商品
output: x和y之间的余弦相似度
'''
numerator = x * y.T # x和y之间的额内积
denominator = np.sqrt(x * x.T) * np.sqrt(y * y.T)
return (numerator / denominator)[0, 0]
def similarity(data):
'''计算矩阵中任意两行之间的相似度
input: data(mat):任意矩阵
output: w(mat):任意两行之间的相似度
'''
m = np.shape(data)[0] # 用户的数量
# 初始化相似度矩阵
w = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
# 计算任意两行之间的相似度
w[i, j] = cos_sim(data[i, ], data[j, ])
w[j, i] = w[i, j]
else:
w[i, j] = 0
return w
def user_based_recommend(data, w, user):
'''基于用户相似性为用户user推荐商品
input: data(mat):用户商品矩阵
w(mat):用户之间的相似度
user(int):用户的编号
output: predict(list):推荐列表
'''
m, n = np.shape(data)
interaction = data[user, ] # 用户user与商品信息
# 1、找到用户user没有互动过的商品
not_inter = []
for i in range(n):
if interaction[0, i] == 0: # 没有互动的商品
not_inter.append(i)
# 2、对没有互动过的商品进行预测
predict = {}
for x in not_inter:
item = np.copy(data[:, x]) # 找到所有用户对商品x的互动信息
for i in range(m): # 对每一个用户
if item[i, 0] != 0: # 若该用户对商品x有过互动
if x not in predict:
predict[x] = w[user, i] * item[i, 0]
else:
predict[x] = predict[x] + w[user, i] * item[i, 0]
# 3、按照预测的大小从大到小排序
return sorted(predict.items(), key=lambda d:d[1], reverse=True)
def top_k(predict, k):
'''为用户推荐前k个商品
input: predict(list):排好序的商品列表
k(int):推荐的商品个数
output: top_recom(list):top_k个商品
'''
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])
return top_recom
if __name__ == "__main__":
# 1、导入用户商品数据
print ("------------ 1. load data ------------")
data = load_data("D:/anaconda4.3/spyder_work/data7.txt")
# 2、计算用户之间的相似性
print ("------------ 2. calculate similarity between users -------------")
w = similarity(data)
# 3、利用用户之间的相似性进行推荐
print ("------------ 3. predict ------------")
predict = user_based_recommend(data, w, 0)
# 4、进行Top-K推荐
print ("------------ 4. top_k recommendation ------------")
top_recom = top_k(predict, 2)
print (top_recom)
结果:
------------ 1. load data ------------
------------ 2. calculate similarity between users -------------
------------ 3. predict ------------
------------ 4. top_k recommendation ------------
[(2, 5.10303902268836), (4, 2.2249110640673515)]用户未打分的商品为2和4, 最终2号打分5.1,,4号打分2.2
参考文献
协同过滤推荐算法
赵志勇——Python 机器学习算法