Checkpoint not complete解决办法
某测试环境开发人员反应执行sql注入脚本的时候,数据库hang住,环境为12.2的rac
解决问题思路
先查看下top
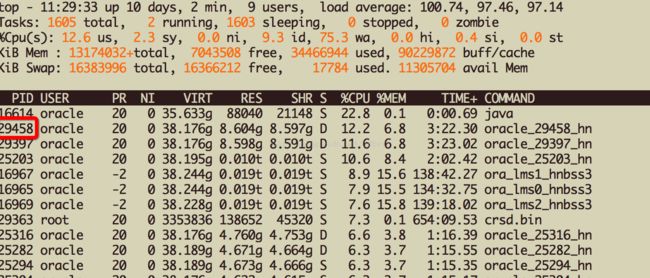
根据相应占用资源的pid查询sqladdr;再根据sqladdr找出对应的sqlid,最后通过sqlid找到相关sql
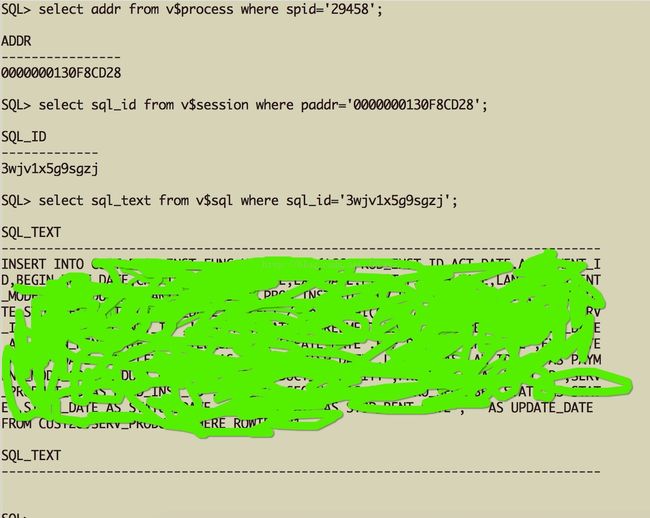
通过相关sql发现是大量insert语句,并且没有append的hint,并且没有no logging以及嵌套了一些笛卡尔积的查询在里面,首先肯定的是sql写的不美丽。。
然后通过sql判断redo会有大量数据写入,结合alter日志以及查询redo


发现redo已经不够切换了,
解决办法可以通过增大redo空间或者增加redo数目,增大空间方法再次就不做赘述,就是新建redolog group,然后switch,在删除原来小的redo。
附一
介绍一下思路原理。
一般来说checkpoint not complete
首先我们要清楚什么时候会出发checkpoint
1、每次重做日志的切换;
2、LOG_CHECKPOINT_TIMEOUT 这个延迟参数的到达;
3、相应字节(LOG_CHECKPOINT_INTERVAL* size of IO OS blocks)被写到当前的重做日志;
4、ALTER SYSTEM SWITCH LOGFILE 这个命令会直接导致checkpoint发生
5、ALTER SYSTEM CHECKPOINT
而出发checkpoint会导致
1. DBWR写所有脏数据到数据文件;
2. LGWR更新控制文件和数据文件的SCN。
所以得出如下结论:
1、系统的IO性能有问题,dbwr进程写的太慢
2、LOG_CHECKPOINT_TIMEOUT,FAST_START_MTTR_TARGET, LOG_CHECKPOINT_INTERVAL 设置的不合理,致checkpoint太频繁
3、日志文件太小
4、数据文件太多
5、sql写的不合理
解决办法是增大redo空间解决问题。
附二
一些sql便于查询分析问题。
select to_char(first_time,'yyyy-mm-dd') day1,count(*) from v$log_history where first_time>=to_date('2014-01-03','yyyy-mm-dd') group by to_char(first_time,'yyyy-mm-dd')
查询每天日志switch的数量。
SELECT to_char(b.begin_interval_time, 'yyyymmddhh24mi') begin_snapshot_time,
c.DB_TIME
FROM (SELECT a.snap_id,
to_char(TRUNC((DB_TIME - lag(DB_TIME, 1, DB_TIME)
over(PARTITION BY stat_name,
instance_number ORDER BY snap_id)) / 1000000/60,2)) DB_TIME
FROM (SELECT a.snap_id,
a.dbid,
a.instance_number,
a.stat_name,
SUM(a.value) DB_TIME
FROM DBA_HIST_SYS_TIME_MODEL a
WHERE a.stat_name = 'DB time'
AND a.instance_number = ---这个地方要检查实例1和实例2
GROUP BY a.snap_id, a.dbid, a.instance_number, a.stat_name) a) c,
dba_hist_snapshot b
WHERE b.instance_number = 1 ---这个地方要检查实例1和实例2
AND c.snap_id = b.snap_id
ORDER BY 1, 2;
查看每小时dbtime的大小
select
b.recid,to_char(b.first_time,'yyyy-mon-dd hh24:mi:ss') start_time,
a.recid,to_char(a.first_time,'yyyy-mon-dd hh24:mi:ss') end_time,
round(((a.first_time-b.first_time)*25)*60,2) minutes
from v$log_history a,v$log_history b
where a.recid=b.recid+1
order by a.first_time asc;
查看redo log之间切换的时间