Hadoop开发插件安装
相关知识
Eclipse 是一个开放源代码的、基于 Java 的可扩展开发平台。就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境。幸运的是Eclipse 附带了一个标准的插件集,包括 Java 开发工具(Java Development Tools,JDT)。
Eclipse的插件机制是轻型软件组件化架构。在客户机平台上,Eclipse使用插件来提供所有的附加功能,例如支持Java以外的其他语言。 已有的分离的插件已经能够支持C/C++(CDT)、Perl、Ruby,Python、telnet和数据库开发。插件架构能够支持将任意的扩展加入到现有环境中,例如配置管理,而决不仅仅限于支持各种编程语言。
Eclipse的设计思想是:一切皆插件。Eclipse核心很小,其它所有功能都以插件的形式附加于Eclipse核心之上。
Eclipse基本内核包括:图形API (SWT/Jface), Java开发环境插件(JDT ),插件开发环境(PDE)等。
Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率。但是,它也有一些缺点,如编码、调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高,开发难度大。
因此,Hadoop的开发者为了降低Hadoop的难度,开发出了Hadoop Eclipse插件,它可以直接嵌入到Hadoop开发环境中,从而实现了开发环境的图形界面化,降低了编程的难度。
Hadoop Eclipse是Hadoop开发环境的插件,在安装该插件之前需要首先配置Hadoop的相关信息。用户在创建Hadoop程序时,Eclipse插件会自动导入Hadoop编程接口的jar文件,这样用户就可以在Eclipse插件的图形界面中进行编码、调试和运行Hadop程序,也能通过Eclipse插件查看程序的实时状态、错误信息以及运行结果。除此之外,用户还可以通过Eclipse插件对HDFS进行管理和查看。总而言之,Hadoop Eclipse插件不仅安装简单,使用起来也很方便。它的功能强大,特别在Hadoop编程方面为开发者降低了很大的难度,是Hadoop入门和开发的好帮手!
Eclipse插件的安装方法大体有以下四种:第一种:直接复制法,第二种:使用link文件法,第三种:使用eclipse自带图形界面安装,第四种:使用dropins安装插件,本实验Hadoop开发插件安装使用了eclipse自带图形界面安装。
系统环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4
eclipse-java-juno-SR2-linux-gtk-x86_64
任务内容
在已经安装好Hadoop和Eclipse环境中,将Hadoop插件安装到Eclipse工具上并对插件进行配置。
任务步骤
1.Eclipse开发工具以及Hadoop默认已经安装完毕,安装在/apps/目录下。
2.在Linux本地创建/data/hadoop3目录,用于存放所需文件。
mkdir -p /data/hadoop3 切换目录到/data/hadoop3目录下,并使用wget命令,下载所需的插件hadoop-eclipse-plugin-2.6.0.jar。
cd /data/hadoop3
wget 官网地址 3.将插件hadoop-eclipse-plugin-2.6.0.jar,从/data/hadoop3目录下,拷贝到/apps/eclipse/plugins的插件目录下。
cp /data/hadoop3/hadoop-eclipse-plugin-2.6.0.jar /apps/eclipse/plugins/ 4.进入ubuntu图形界面,双击eclipse图标,启动eclipse。
5.在Eclipse窗口界面,依次点击Window => Open Perspective => Other。
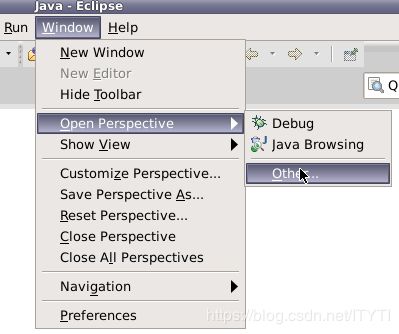
弹出一个窗口。
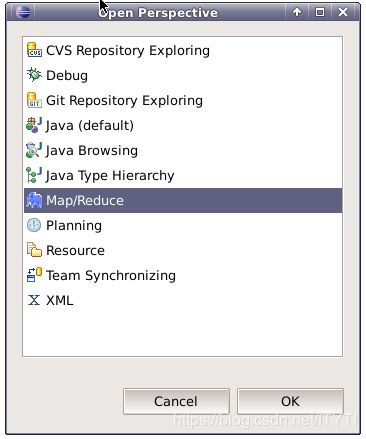
选择Map/Reduce,并点击OK,可以看到窗口中,有三个变化。(左侧项目浏览器、右上角操作布局切换、面板窗口)
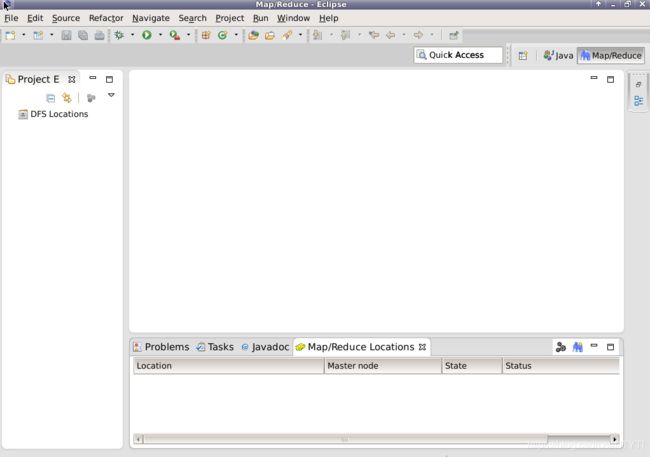
如果在windows下,则需要手动调出面板窗口Map/Reduce Locations面板,操作为,点击window => show view => Other。
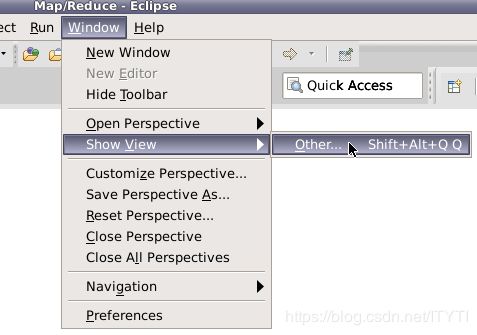
在弹出的窗口中,选择Map/Reduce Locations选项,并点击OK。
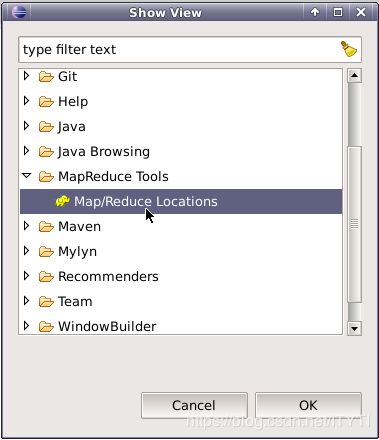
这样便可以调出视图窗口Map/Reduce Location。
6.添加Hadoop配置,连接Hadoop集群。
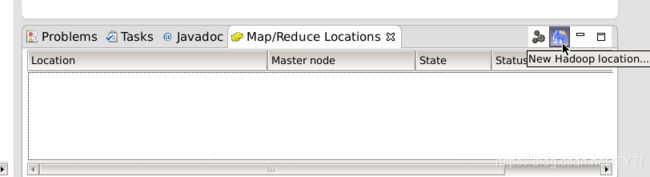
在这里添加Hadoop相关配置。
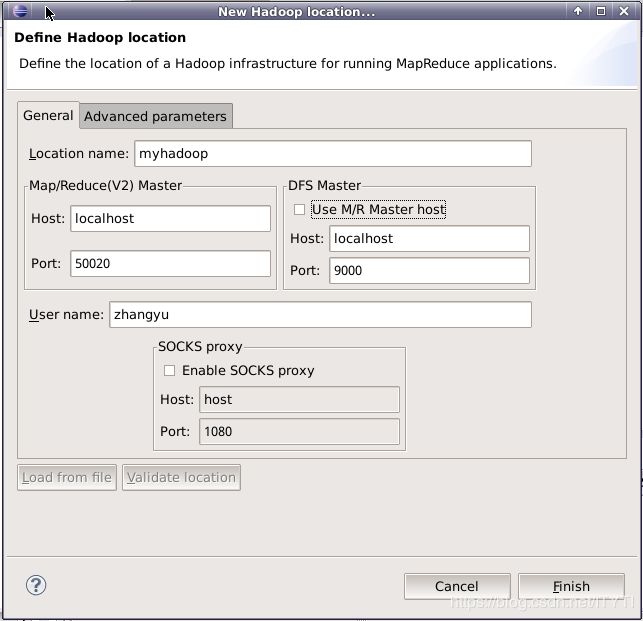
Location name,是为此配置起的一个名字。
DFS Master,是连接HDFS的主机名和端口号。
点击Finish保存配置。
7.另外还需保证Hadoop中的HDFS相关进程已经启动。在终端命令行输入jps查看进程状态。
jps
若不存在hdfs相关的进程,如Namenode、Datanode、secondarynamenode,则需要先切换到HADOOP_HOME下的sbin目录,启动hadoop。
cd /apps/hadoop/sbin
./start-all.sh 8.展开左侧项目浏览视图,可以看到HDFS目录结构。
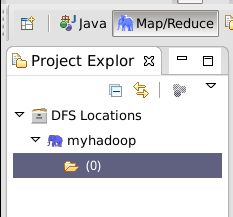
9.上图发现HDFS上,没有存放任何目录。那下面来创建一个目录,检测插件是否可用。
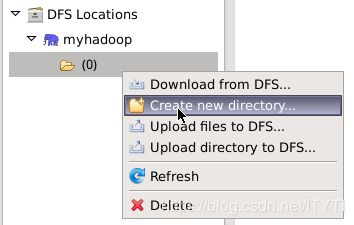
右键myhadoop下的文件夹,在弹出的菜单中,点击Create new directory。
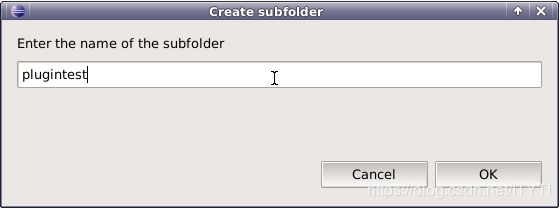
输入目录名称,点击OK则创建目录成功。
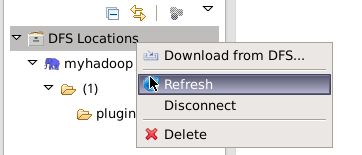
右键文件夹,点击Refresh,可用刷新HDFS目录。
或者在终端查看
hadoop fs -ls /到此Hadoop开发插件已经安装完毕!