Python常用标准库(二)
系统环境
- Linux Ubuntu 14.04
- Python 3.6
- Ipython
- PyCharm
本实验共包含Queue、StringIO、logging、ConfigParser、urllib与urllib2、json、time、datetime等8个标准库
实验步骤
1.Queue模块:
队列,数据存放在内存中,一般用于交换数据。
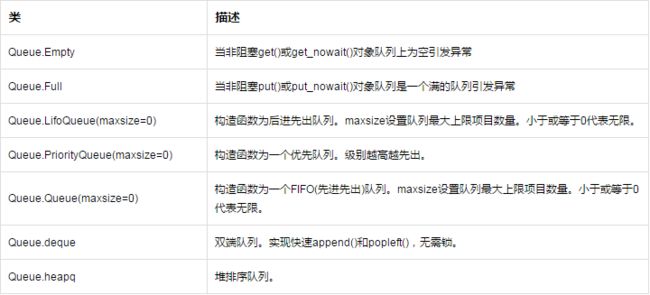
其中常用类为Queue.Queue,它提供了一下方法:
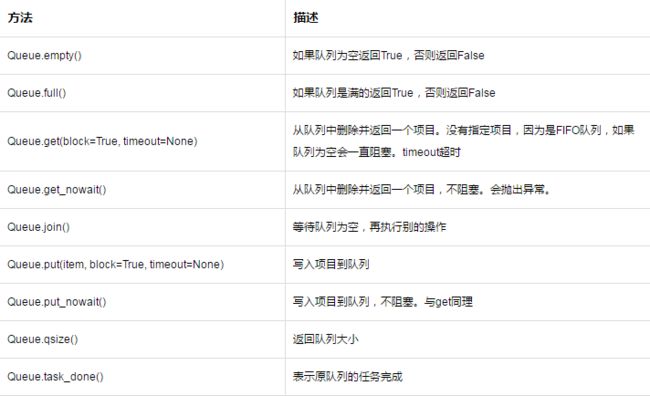
1.举例:
import queue
q = queue.Queue()
#向队列中写入字符串
q.put('test')
#返回队列大小
q.qsize()
#返回字符串
q.get()
#返回队列大小
q.qsize()
#判断队列是否为满
q.full()
#判断队列是否为空
q.empty() 
2.StringIO模块:
StringIO库将字符串存储在内存中,像操作文件一样操作。主要提供了一个StringIO类
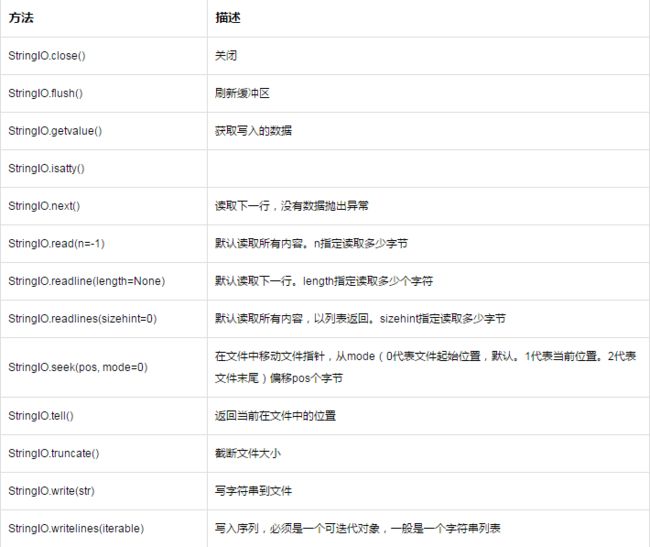
可以看到,StringIO方法与文件对象方法大部分都一样
1.示例:
from io import StringIO
f = StringIO()
#写字符串到文件
f.write('hello')
f.write(' ')
f.write('world!')
#获取写入的数据
f.getvalue()

用一个字符串初始化StringIO,可以像读文件一样读取:
2.示例:
f = StringIO('hello\nworld!')
f.read()
s = StringIO('hello world!')
s.seek(5) # 指针移动到第五个字符,开始写入
s.write('-')
s.getvalue()

3.logging模块:
记录日志库。
常用类:

日志级别:
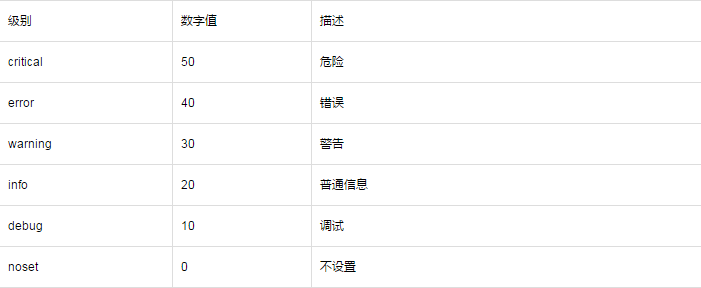
Formatter类可以自定义日志格式,默认时间格式是%Y-%m-%d %H:%M:%S,有以下这些属性:
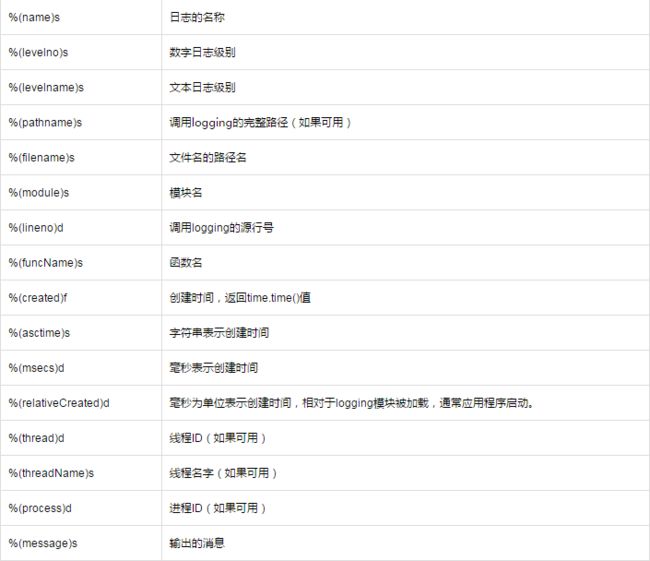
示例:
1.使用vim编辑一个log.py文件,内容为:
#!/usr/bin/python
# -*- coding: utf-8 -*-
#--------------------------------------------------
# 日志格式
#--------------------------------------------------
# %(asctime)s 年-月-日 时-分-秒,毫秒 2013-04-26 20:10:43,745
# %(filename)s 文件名,不含目录
# %(pathname)s 目录名,完整路径
# %(funcName)s 函数名
# %(levelname)s 级别名
# %(lineno)d 行号
# %(module)s 模块名
# %(message)s 消息体
# %(name)s 日志模块名
# %(process)d 进程id
# %(processName)s 进程名
# %(thread)d 线程id
# %(threadName)s 线程名
import logging
format = logging.Formatter('%(asctime)s - %(levelname)s %(filename)s [line:%(lineno)d] %(message)s')
# 创建日志记录器
info_logger = logging.getLogger('info')
# 设置日志级别,小于INFO的日志忽略
info_logger.setLevel(logging.INFO)
# 日志记录到磁盘文件
info_file = logging.FileHandler("/data/info.log")
# info_file.setLevel(logging.INFO)
# 设置日志格式
info_file.setFormatter(format)
info_logger.addHandler(info_file)
error_logger = logging.getLogger('error')
error_logger.setLevel(logging.ERROR)
error_file = logging.FileHandler("/data/error.log")
error_file.setFormatter(format)
error_logger.addHandler(error_file)
# 输出控制台(stdout)
console = logging.StreamHandler()
console.setLevel(logging.DEBUG)
console.setFormatter(format)
info_logger.addHandler(console)
error_logger.addHandler(console)
if __name__ == "__main__":
# 写日志
info_logger.warning("info message.")
error_logger.error("error message!")
2.运行log.py文件
python log.py
可以在目录下看见生成了error.log和info.log两个文件
上面代码实现了简单记录日志功能。分别定义了info和error日志,将等于或高于日志级别的日志写到日志文件中。在小项目开发中把它单独写一个模块,很方面在其他代码中调用。
需要注意的是,在定义多个日志文件时,getLogger(name=None)类的name参数需要指定一个唯一的名字,如果没有指定,日志会返回到根记录器,也就是意味着他们日志都会记录到一起。
4.ConfigParser模块:
配置文件解析。
这个库我们主要用到ConfigParser.ConfigParser()类,对ini格式文件增删改查。
ini文件固定结构:有多个部分块组成,每个部分有一个[标识],并有多个key,每个key对应每个值,以等号"="分隔。值的类型有三种:字符串、整数和布尔值。其中字符串可以不用双引号,布尔值为真用1表示,布尔值为假用0表示。注释以分号";"开头。
示例:
1.创建一个config.ini文件,内容为:
[host1]
host = 192.168.1.1
port = 22
user = zhangsan
pass = 123
[host2]
host = 192.168.1.2
port = 22
user = lisi
pass = 456
[host3]
host = 192.168.1.3
port = 22
user = wangwu
pass = 789
2.使用vim编辑一个config.py文件,内容为:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from configparser import ConfigParser
conf = ConfigParser()
conf.read("/data/config.ini")
section = conf.sections()[0] # 获取随机的第一个部分标识
options = conf.options(section) # 获取部分中的所有键
key = options[2]
value = conf.get(section, options[2]) # 获取部分中键的值
print(key, value)
print(type(value))
3.运行config.py文件
python config.py
结果为:
user zhangsan
这里有意打出来了值的类型,来说明下get()方法获取的值都是字符串,如果有需要,可以getint()获取整数。测试发现,ConfigParser是从下向上读取的文件内容!
4.遍历文件中的每个部分的每个字段,使用vim编辑一个config2.py,内容为:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from configparser import ConfigParser
conf = ConfigParser()
conf.read("/data/config.ini")
sections = conf.sections() # 获取部分名称 ['host3', 'host2', 'host1']
for section in sections:
options = conf.options(section) # 获取部分名称中的键 ['user', 'host', 'port', 'pass']
for option in options:
value = conf.get(section, option) # 获取部分中的键值
print (option + ": " + value)
print("-------------")
5.运行config2.py文件
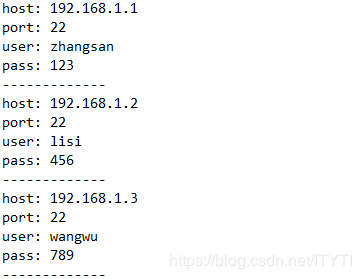
通过上面的例子,熟悉了sections()、options()和get(),能任意获取文件的内容了。
5.urllib与urllib2模块:
打开URL。urllib2是urllib的增强版,新增了一些功能,比如Request()用来修改Header信息。但是urllib2还去掉了一些好用的方法,比如urlencode()编码序列中的两个元素(元组或字典)为URL查询字符串。一般情况下这两个库结合着用,但是在Python3中将urllib和urllib2合并为了urllib。
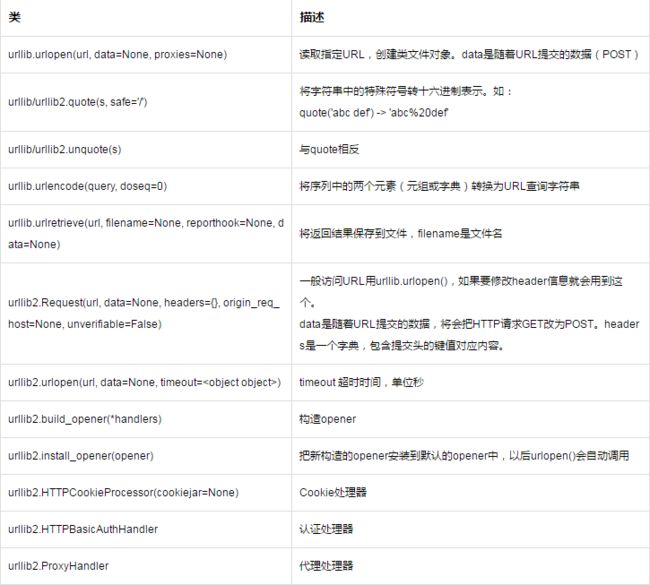
urllib.urlopen()有几个常用的方法:

示例:
抓取页面
1.抓取百度页面,使用vim编辑一个test.py文件
import urllib.request
file=urllib.request.urlopen('http://www.baidu.com') # 获取的网站页面源码
data=file.read() #读取全部
dataline=file.readline() #读取一行内容
fhandle=open("/data/baidu.html","wb") #将爬取的网页保存在本地
fhandle.write(data)
fhandle.close()
2.运行test.py文件,可以在目录下找到baidu.html文件
python test.py
模拟浏览器
有些网页为了防止别人恶意采集其信息所以进行了一些反爬虫的设置,因此我们想要获取这些网页就需要设置一些Headers信息(User-Agent),模拟成浏览器去访问这些网站。
示例:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36'
}
request = urllib.request.Request(url, headers=header)
reponse = urllib.request.urlopen(request).read()
fhandle = open("/data/baidu.html", "wb")
fhandle.write(reponse)
fhandle.close()
设置代理服务器
使用同一个IP去爬取同一个网站上的网页,久了之后会被该网站服务器屏蔽,因此我们需要使用代理服务器。 (使用代理服务器去爬取某个网站的内容的时候,在对方的网站上,显示的不是我们真实的IP地址,而是代理服务器的IP地址)
3.示例:
def use_proxy(proxy_addr,url):
import urllib.request
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(url).read().decode('utf8')
return data
proxy_addr='61.163.39.70:9999'
data=use_proxy(proxy_addr,'http://www.baidu.com')
print(len(data))
cookie的使用
爬取的网页涉及登录信息。访问每一个互联网页面,都是通过HTTP协议进行的,而HTTP协议是一个无状态协议,所谓的无状态协议即无法维持会话之间的状态。
4.示例:
import urllib.request
import urllib.parse
import urllib.error
import http.cookiejar
url='http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=La2A2'
data={
'username':'zhanghao',
'password':'mima',
}
postdata=urllib.parse.urlencode(data).encode('utf8')
header={
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
request=urllib.request.Request(url,postdata,headers=header)
#使用http.cookiejar.CookieJar()创建CookieJar对象
cjar=http.cookiejar.CookieJar()
#使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象
cookie=urllib.request.HTTPCookieProcessor(cjar)
#构造opener
opener=urllib.request.build_opener(cookie)
#将opener安装为全局
urllib.request.install_opener(opener)
try:
reponse=urllib.request.urlopen(request)
except urllib.error.HTTPError as e:
print(e.code)
print(e.reason)
fhandle=open('./test1.html','wb')
fhandle.write(reponse.read())
fhandle.close()
#打开test2.html文件,会发现此时会保持我们的登录信息,为已登录状态。也就是说,对应的登录状态已经通过Cookie保存。
url2='http://bbs.chinaunix.net/forum-327-1.html'
reponse2=urllib.request.urlopen(url)
fhandle2=open('./test2.html','wb')
fhandle2.write(reponse2.read())
fhandle2.close()
6.JSON模块:
JSON是一种轻量级数据交换格式,一般API返回的数据大多是JSON、XML,如果返回JSON的话,将获取的数据转换成字典,方便在程序中处理。
json库经常用的有两种方法dumps和loads():
示例:
1.将字典转换为JSON字符串
import json
dict = {'user':[{'user1': 123}, {'user2': 456}]}
type(dict)
json_str = json.dumps(dict)
type(json_str)
2.将JSON字符串转换为字典
d = json.loads(json_str)
type(d)
JSON与Python解码后数据类型:
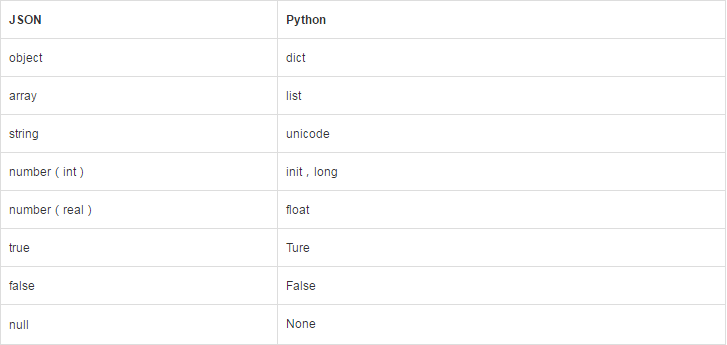
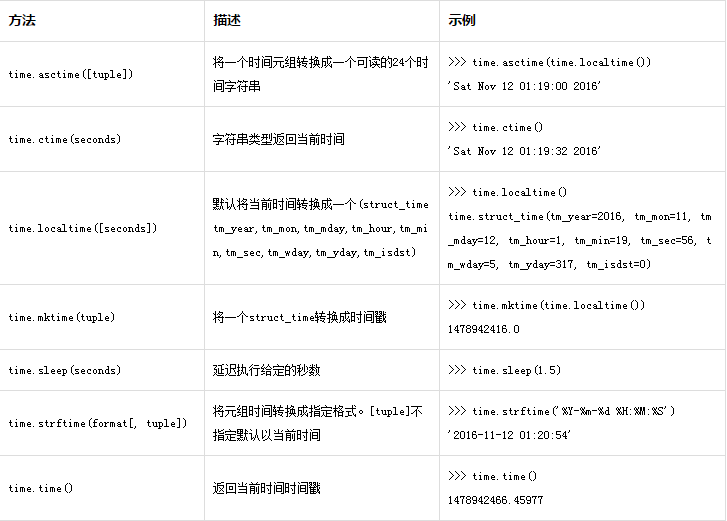
7.time模块:
time库提供了各种操作时间值
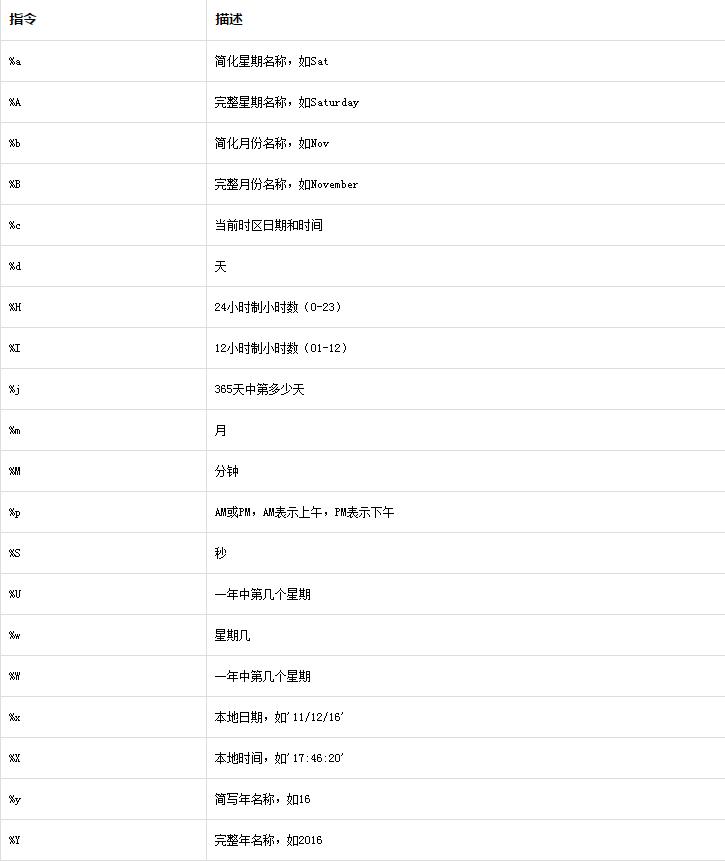
strftime():

8.datetime模块:
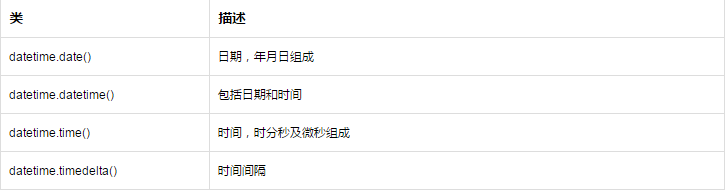
datetime.date()类:
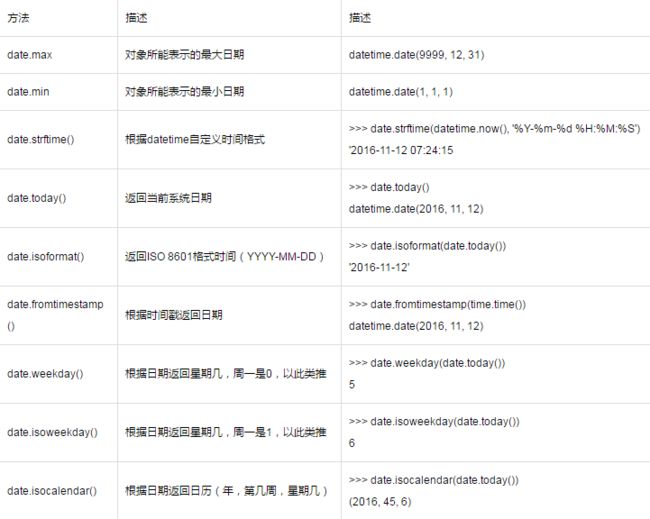
datetime.datetime()类:
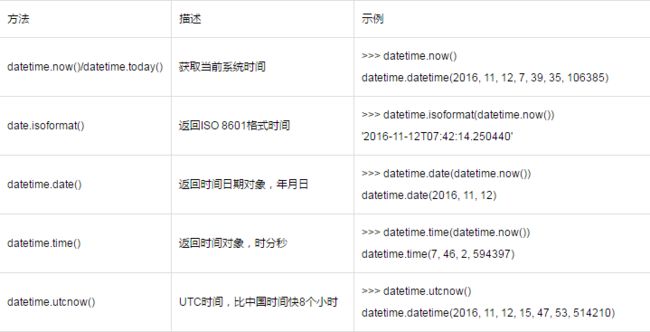
datetime.time()类:
