NLP自然语言处理中英文分词工具集锦与基本使用
目录
NLP分词工具集锦
分词实例用文件
一、中文分词工具
(1)Jieba
(2)snowNLP分词工具
(3)thulac分词工具
(4)pynlpir 分词工具
(5)StanfordCoreNLP分词工具
(6)Hanlp分词工具
二、英文分词工具
1. NLTK:
2. SpaCy:
3. StanfordCoreNLP:
NLP分词工具集锦
分词实例用文件
Chinese=open("Chinese.txt",'r').read()
English=open("English.txt",'r').read()央视315晚会曝光湖北省知名的神丹牌、莲田牌“土鸡蛋”实为普通鸡蛋冒充,同时在商标上玩猫腻,分别注册“鲜土”、注册“好土”商标,让消费者误以为是“土鸡蛋”。3月15日晚间,新京报记者就此事致电湖北神丹健康食品有限公司方面,其工作人员表示不知情,需要了解清楚情况,截至发稿暂未取得最新回应。新京报记者还查询发现,湖北神丹健康食品有限公司为农业产业化国家重点龙头企业、高新技术企业,此前曾因涉嫌虚假宣传“中国最大的蛋品企业”而被罚6万元。
Trump was born and raised in the New York City borough of Queens and received an economics degree from the Wharton School. He was appointed president of his family's real estate business in 1971, renamed it The Trump Organization, and expanded it from Queens and Brooklyn into Manhattan. The company built or renovated skyscrapers, hotels, casinos, and golf courses. Trump later started various side ventures, including licensing his name for real estate and consumer products. He managed the company until his 2017 inauguration. He co-authored several books, including The Art of the Deal. He owned the Miss Universe and Miss USA beauty pageants from 1996 to 2015, and he produced and hosted The Apprentice, a reality television show, from 2003 to 2015. Forbes estimates his net worth to be $3.1 billion.一、中文分词工具
(1)Jieba
import jieba
seg_list = jieba.cut(Chinese, cut_all=False)
print("Jieba:Default Mode: \n" + "/ ".join(seg_list)) # 精确模式(2)snowNLP分词工具
from snownlp import SnowNLP
snow = SnowNLP(Chinese).words
print("snowNLP分词:\n",snow)(3)thulac分词工具
import thulac
thu1 = thulac.thulac(seg_only=True).cut(Chinese) #只进行分词,不进行词性标注
print("thulac分词:\n",thu1)(4)pynlpir 分词工具
import pynlpir
pynlpir.open()
s=pynlpir.segment(Chinese)
print("pynlpir分词:\n",s)(5)StanfordCoreNLP分词工具
注意,下面的路径是我个人下载文件的路径,详细参见https://github.com/Lynten/stanford-corenlp
from stanfordcorenlp import StanfordCoreNLP
with StanfordCoreNLP(r'E:\Users\Eternal Sun\PycharmProjects\1\venv\Lib\stanford-corenlp-full-2018-10-05', lang='zh') as nlp:
print("stanfordcorenlp分词:\n",nlp.word_tokenize(Chinese))(6)Hanlp分词工具
from pyhanlp import *
print("HanLP分词:\n",HanLP.segment(Chinese))分词结果如下:
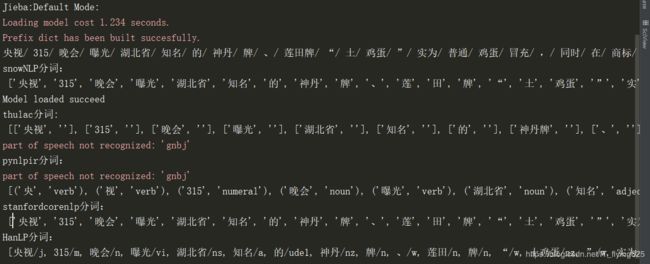
二、英文分词工具
1. NLTK:
#先分句再分词
import nltk
sents = nltk.sent_tokenize(English)
word = []
for sent in sents:
word.append(nltk.word_tokenize(sent))
print("NLTK先分句再分词:\n",word)
#分词
text = nltk.word_tokenize(English)
print("NLTK直接进行分词:\n",text)二者之间的区别在于,如果先分句再分词,那么将保留句子的独立性,即生成结果是一个二维列表,而对于直接分词来说,生成的是一个直接的一维列表,结果如下:

2. SpaCy:
import spacy
from spacy.tokens import Doc
class WhitespaceTokenizer(object):
def __init__(self, vocab):
self.vocab = vocab
def __call__(self, text):
words = text.split(' ')
# All tokens 'own' a subsequent space character in this tokenizer
spaces = [True] * len(words)
return Doc(self.vocab, words=words, spaces=spaces)
nlp = spacy.load('en_core_web_sm')
nlp.tokenizer = WhitespaceTokenizer(nlp.vocab)
doc = nlp(English)
print("spacy分词:")
print([t.text for t in doc])3. StanfordCoreNLP:
from stanfordcorenlp import StanfordCoreNLP
nlp=StanfordCoreNLP(r'E:\Users\Eternal Sun\PycharmProjects\1\venv\Lib\stanford-corenlp-full-2018-10-05')
print ("stanfordcorenlp分词:\n",nlp.word_tokenize(English))分词结果
