大数据是什么?学大数据要掌握的基础是?(简单的介绍)
一、学习大数据需要的基础
javaSE,EE(SSM)
90%的大数据框架都是java写的
如:MongoDB--最受欢迎的,跨平台的,面向文档的数据库。
Hadoop--用Java编写的开源软件框架,用于分布式存储,并对非常大的数据集进行分布式处理。
Spark --Apache Software Foundation中最活跃的项目,是一个开源集群计算框架。
Hbase--开放源代码,非关系型,分布式数据库,采用Google的BigTable建模,用Java编写,并在HDFS上运行。
MySQL(必须需要掌握的)
SQLon Hadoop又分:
batch SQL(Hive):一般用于复杂的 ETL 处理,数据挖掘,高级分析。
interactive SQL:交互式 SQL 查询,通常在同一个表上反复的执行不同的查询
operation SQL:通常是单点查询,延时要求小于 1 秒,该类系统主要是HBase。
Linux
Linux(一种操作系统,程序员必须掌握的,我的博客里有我对Linux的介绍)
大数据的框架安装在Linux操作系统上
二、需要学什么
第一方面:大数据离线分析
一般处理T+1数据:
Hadoop:(common、HDFS、MapReduce、YARN)重点中的重点。
Hadoop的框架最核心的设计就是:HDFS 和 MapReduce,
Hadoop :主要是的环境搭建
Hadoop的思想:处理数据的思想。
Hadoop用Java编写的开源软件框架,用于分布式存储,并对非常大的数据集进行分布式处理,
用户可以在不了解分布式底层细节的情况下,开发分布式程序,
充分利用集群进行高速运算和存储。
百度百科找到的:


Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。
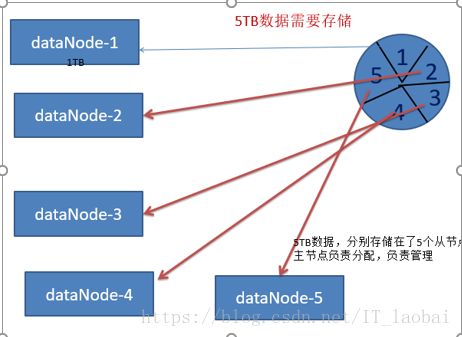
HDFS:
HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。
这些节点包括NameNode(仅一个),它在 HDFS 内部提供元数据服务;
DataNode,它为 HDFS 提供存储块。
由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。
这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定 NameNode 可以控制所有文件操作。
NameNode:
NameNode 是一个通常在HDFS实例中的单独机器上运行的软件,
它负责管理文件系统名称空间和控制外部客户机的访问。
NameNode 决定是否将文件映射到 DataNode 上的复制块上。
对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。
DataNode:
DataNode 也是一个通常在HDFS实例中的单独机器上运行的软件。
Hadoop 集群包含一个 NameNode 和大量 DataNode。
DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。
Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度
MapReduce:
概念"Map(映射)"和"Reduce(归约)"
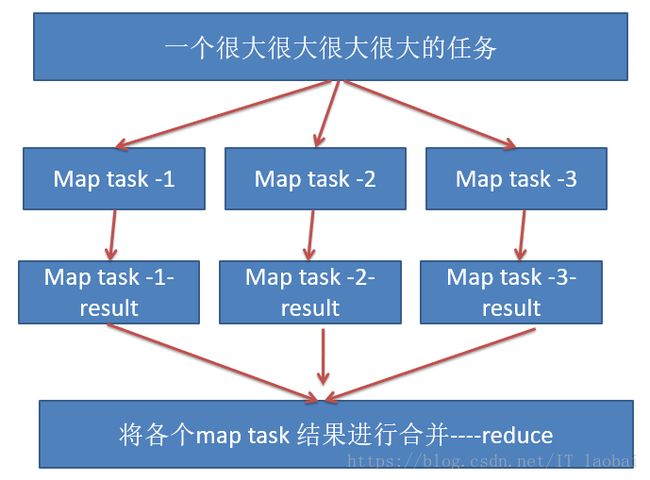
MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。
2)MapReduce是一个并行计算与运行软件框架(Software Framework)
3)MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。
Hive(MPP架构):
大数据数据仓库
通过写SQL对数据进行操作,类似于mysql数据库中的sql
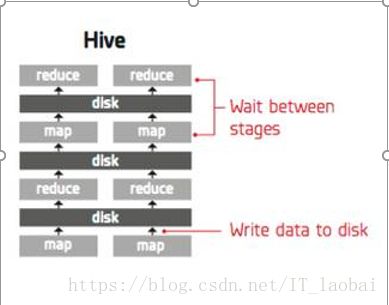
扩展:
MPP架构:MPP 架构的优点是查询速度快,通常在秒计甚至毫秒级以内就可以返回查询结果。
(但MPP 架构不适合大规模部署)
HBase(博客中有 这个重要)
基于HDFS的NOSQL数据库
面向列的存储
列存储:
列存储的思想是将元组垂直划分为列族集合,每一个列族独立存储,列族可以退化为只仅包含
一个列的平凡列族。当查询少量列时,列存储模型可以极大的减少磁盘IO 操作,提高查询性能。
当查询的列跨越多个列族时,需要将存储在不同列族中列数据拼接成原始数据,由于不同列族
存储 在不同的 HDFS 节点上,导致大量的数据跨越网络传输,从而降低查询性能。
扩展前沿框架:
协作框架:
sqoop(桥梁:HDFS 《==》RDBMS)
Sqoop(发音:skup)是一款开源的工具,一个用来将Hadoop和关系型数据库中的数据相互转移的工具,
主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,
可以将一个关系型数据库(例如 :MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS
中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop介绍:
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,
也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
RDBMS:
RDBMS即关系数据库管理系统(Relational Database Management System),
是将数据组织为相关的行和列的系统而管理关系数据库的计算机软件就是关系数据库管理系统,
常用的数据库软件有Oracle、SQL server等。
RDBMS 是SQL 的基础,同样也是所有现代数据库系统的基础
RDBMS 中的数据存储在被称为表(tables)的数据库对象中。
表是相关的数据项的集合,它由列和行组成。
RDBMS的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
flume:收集日志文件中信息
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
调度框架anzkaban,了解
crontab(Linux自带)
crontab命令常见于Unix和类Unix的操作系统之中,用于设置周期性被执行的指令。
该命令从标准输入设备读取指令,并将其存放于“crontab”文件中,以供之后读取和执行。
Kylin(中国自主知识产权操作系统)
Kylin操作系统是国家高技术研究发展计划(863计划)的重大成果之一,
是以国防科技大学为主导,与中软、联想等单位联合设计和开发的具有完全自主版权,
可支持多种微处理器和多种计算机体系结构,具有高性能、高可用性和高安全性,
并与Linux应用二进制兼容的国产中文服务器操作系统。
Impala:
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,
能查询存储在Hadoop的HDFS和HBase中的PB级大数据。
已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,
仍然是一个批处理过程,难以满足查询的交互性。重要的是它查询的很快
ElasticSearch(ES)
ElasticSearch是一个基于Lucene的搜索服务器。
它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
ES概念:
cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,
主从节点是对于集群内部来说的。
es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,
因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
了解:
Shards
Replicas
Recovery
River
Gateway
Discovery.zen
Transport
下一篇大数据常识正在找资料完善中。