Hadoop简单集群搭建(适合初学者学习)
一、Linux环境搭建
1.注意事项
1.1 确认VmWare服务已启动
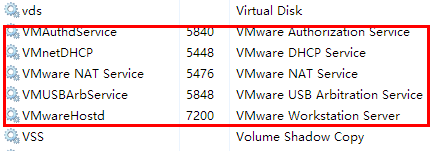
1.2 确认VmWare网关地址

1.3 确认宿主机IP地址和DNS

2.复制虚拟机
2.1 虚拟机拷贝
将虚拟机文件夹复制三份,并分别重命名, 并使用VM打开重命名

![[外链图片转存失败(img-Zh8XrZf3-1565960033439)(assets/1557934570545.png)]](http://img.e-com-net.com/image/info8/7da5c05fe6e94bf4b00fb754e415b1ec.png)
2.2设置三台虚拟机内存
- 需要三台虚拟机, 并且需要同时运行, 所以总体上的占用为: 每 台 虚 拟 机 内 存 × 3 每台虚拟机内存 \times 3 每台虚拟机内存×3
- 在分配的时候, 需要在总内存大小的基础上, 减去2G-4G作为系统内存, 剩余的除以3, 作为每台虚拟机的内存
每台机器的内存 = ( 总内存 - 4 ) / 3

3.启动虚拟机并修改Mac和IP
3.1 集群规划
| IP | 主机名 | 环境配置 | 安装 |
|---|---|---|---|
| 192.168.174.100 | node01 | 关防火墙和selinux, host映射, 时钟同步 | JDK |
| 192.168.174.110 | node02 | 关防火墙和selinux, host映射, 时钟同步 | JDK |
| 192.168.174.120 | node03 | 关防火墙和selinux, host映射, 时钟同步 | JDK |
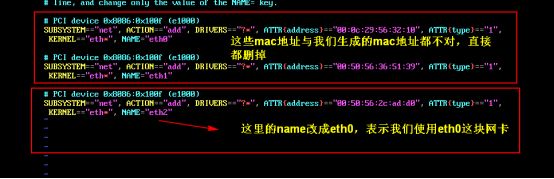
3.2 设置ip和Mac地址
每台虚拟机更改mac地址:
vim /etc/udev/rules.d/70-persistent-net.rules
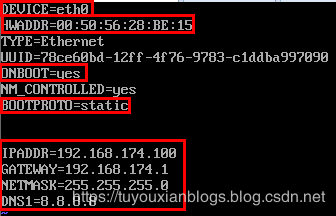
每台虚拟机更改IP地址:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
每台虚拟机修改对应主机名(重启后永久生效)
vi /ect/sysconfig/network
HOSTNAME=node01
每台虚拟机设置ip和域名映射
vim /etc/hosts

3.3 inux系统重启
关机重启linux系统即可进行联网了
第二台第三台机器重复上述步骤,并设置IP网址为192.168.174.110,192.168.174.120
4.关闭防火墙和SELinux
- 节点:集权中一台服务器就是一个节点
- node01.hadoop.com 全限定域名 FQDN
- 防火墙 – 端口号 22 8080等
- SELinux – 进程的权限
- 工作的生产环境 — 防火墙、用户(sudo)、selinux
4.1 关闭防火墙
三台机器执行以下命令(root用户来执行)
service iptables stop #关闭防火墙
chkconfig iptables off #禁止开机启动
4.2 三台机器关闭selinux
- 什么是SELinux
- SELinux是Linux的一种安全子系统
- Linux中的权限管理是针对于文件的, 而不是针对进程的, 也就是说, 如果root启动了某个进程, 则这个进程可以操作任何一个文件
- SELinux在Linux的文件权限之外, 增加了对进程的限制, 进程只能在进程允许的范围内操作资源
- 为什么要关闭SELinux
- 如果开启了SELinux, 需要做非常复杂的配置, 才能正常使用系统, 在学习阶段, 在非生产环境, 一般不使用SELinux
- SELinux的工作模式
enforcing强制模式permissive宽容模式disable关闭
# 修改selinux的配置文件
vi /etc/selinux/config

4.3 三台机器机器免密码登录

- 为什么要免密登录
- Hadoop 节点众多, 所以一般在主节点启动从节点, 这个时候就需要程序自动在主节点登录到从节点中, 如果不能免密就每次都要输入密码, 非常麻烦
- 免密 SSH 登录的原理
- 需要先在 B节点 配置 A节点 的公钥
- A节点 请求 B节点 要求登录
- B节点 使用 A节点 的公钥, 加密一段随机文本
- A节点 使用私钥解密, 并发回给 B节点
- B节点 验证文本是否正确
第一步:三台机器生成公钥与私钥
在三台机器执行以下命令,生成公钥与私钥
ssh-keygen -t rsa
执行该命令之后,按下三个回车即可

第二步:拷贝公钥到同一台机器
三台机器将拷贝公钥到第一台机器
三台机器执行命令:
ssh-copy-id node01
第三步:复制第一台机器的认证到其他机器
将第一台机器的公钥拷贝到其他机器上
在第一天机器上面指向以下命令
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh

4.4三台机器时钟同步
- 为什么需要时间同步
- 因为很多分布式系统是有状态的, 比如说存储一个数据, A节点 记录的时间是 1, B节点 记录的时间是 2, 就会出问题
## 安装
yum install -y ntp
## 启动定时任务
crontab -e
#查看时间与日期
date
随后在输入界面键入
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;#分钟、小时、天、月、星期
#每分钟与阿里的ntp4同步时间(到分种)
- 与springTask相似 * * * * * * *(到秒)
- /usr/sbin/ntpdate ntp4.aliyun.com – 时钟同步命令
- 可以用 date命令查看linux当前时间是否正确
二、辅助软件JDK&mysql
1.三台机器安装jdk
1.1 卸载自带openjdk
rpm -qa | grep java
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64
1.2 创建安装目录
#shell
mkdir -p /export/softwares #软件包存放目录
mkdir -p /export/servers #安装目录
1.3上传并解压
yum insatll -y lrzsz
rz
#上传jdk到/export/softwares路径下去,并解压
tar -zxvf jdk-8u141-linux-x64.tar.gz -C ../servers/
1.4 配置环境变量
vim /etc/profile
添加如下内容
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=:$JAVA_HOME/bin:$PATH
修改完成之后记得 source /etc/profile生效
source /etc/profile
scp -r jdk1.8.0 node02:/export/servers
2.mysql的安装
1.在线安装mysql相关软件
yum install mysql mysql-server mysql-devel
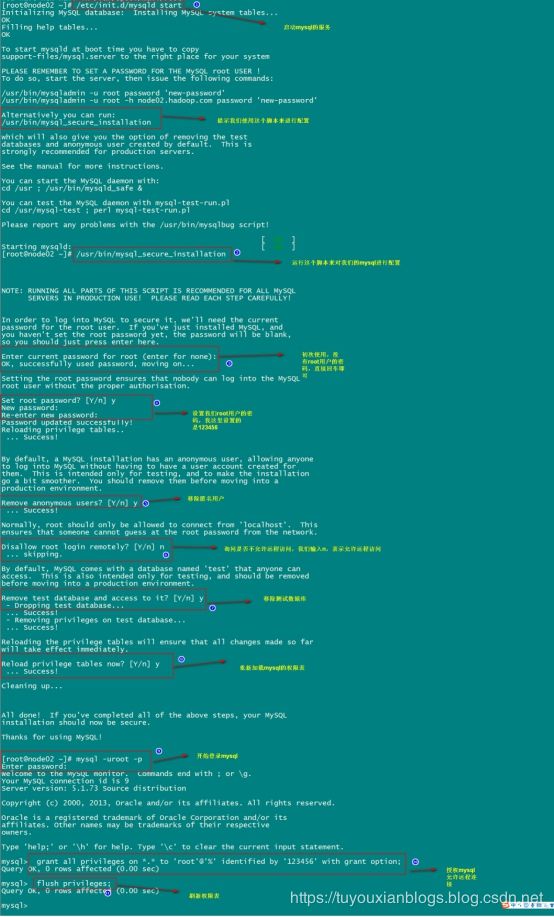
2.启动mysql的服务
/etc/init.d/mysqld start
#开机mysql服务自启
chkconfig --add mysqld
chkconfig --list(查看服务列表)
chkconfig --level 345 mysqld on
reboot
3.通过mysql自带脚本进行设置
/usr/bin/mysql_secure_installation
4.登陆mysql进行授权(远程访问)
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
flush privileges;
三、Hadoop安装
- 注意这里node01用来放置了namenode和datenode,正确搭建只能当做namenode
- 如果你的内存充足,想做一个namenode对应三datenode,可以去我主页查看另一篇搭建方法
集群规划
| 服务器IP | 192.168.174.100 | 192.168.174.110 | 192.168.174.120 |
|---|---|---|---|
| 主机名 | node01 | node02 | node03 |
| NameNode | 是 | 否 | 否 |
| SecondaryNameNode | 是 | 否 | 否 |
| dataNode | 是 | 是 | 是 |
| ResourceManager | 是 | 否 | 否 |
| NodeManager | 是 | 是 | 是 |
第一步:上传apache hadoop包并解压
解压命令
cd /export/softwares
tar -zxvf hadoop-2.7.5.tar.gz -C ../servers/
cd /export/servers/hadoop-2.7.5/
bin/hadoop.sh checknative

第二步:修改配置文件
修改core-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://node01:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatasvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
configuration>
修改hdfs-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node01:50090value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>node01:50070value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2value>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/editsvalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/namevalue>
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/editsvalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
configuration>
修改hadoop-env.sh
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.ubertask.enablename>
<value>truevalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node01:19888value>
property>
configuration>
修改yarn-site.xml
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>20480value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
configuration>
修改mapred-env.sh
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改slaves
修改slaves文件,然后将安装包发送到其他机器,重新启动集群即可
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim slaves
#配置从机
node01
node02
node03
第一台机器执行以下命令
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
安装包的分发
第一台机器执行以下命令
cd /export/servers/
scp -r hadoop-2.7.5 node02:$PWD
scp -r hadoop-2.7.5 node03:$PWD
第三步:配置hadoop的环境变量
三台机器都要进行配置hadoop的环境变量
三台机器执行以下命令
vim /etc/profile
export HADOOP_HOME=/export/servers/hadoop-2.7.5
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile
第四步:启动集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。
注意: 首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和
准备工作,因为此时的 HDFS 在物理上还是不存在的。
hdfs namenode -format 或者 hadoop namenode –format
准备启动
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
三个端口查看界面
http://node01:50070/explorer.html#/ 查看hdfs
http://node01:8088/cluster 查看yarn集群
http://node01:19888/jobhistory 查看历史完成的任务
- core-site.xml 集群的核心配置,namenode高可用
- hdfs-site.xml HDFS分布式文件系统的相关配置
- hadoop-env.sh jdk hdfs相关日志
- mapred-site.xml mapreduce相关设置
- yarn-site.xml yarn 资源平台设置
- mapred-env.sh jdk MR日志
- slaves datenode结点