TCP粘包/拆包与Netty解决方案
【1】TCP粘包/拆包
TCP是个“流”协议,所谓流,就是没有界限的一串数据。大家可以想象河里的流水,它们是连成一片的,其间并没有分界线。TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。
① TCP粘包/拆包问题说明
我们可以通过图解对TCP粘包和拆包问题进行说明,粘包问题示例如图所示。

假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取的字节数是不定的,故可能存在以下四种情况。
(1) 服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包;
(2) 服务端一次接收到了两个数据包,D1和D2粘合在一起,被称为TCP粘包;
(3) 服务端分两次读取到了两个数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这被称为TCP拆包;
(4) 服务端分两次读取到了两个数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余内容D1_2和D2包的整包。
如果此时服务端TCP接收滑窗非常小,而数据包D1和D2比较大,很有可能会发生第5种可能,即服务端分多次才能将D1和D2包接收完全,期间发生多次拆包。
② TCP粘包/拆包发生的原因
问题产生的原因有三个,分别如下:
- 应用程序write写入的字节大小大于套接口发送缓冲区大小;
- 进行MSS大小的TCP分段;
- 以太网帧的payload大于MTU进行IP分片;

③ 粘包问题的解决策略
由于底层的TCP无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案,可以归纳如下。
- (1) 消息定长,例如每个报文的大小为固定长度200字节,如果不够,空位补空格;
- (2) 在包尾增加回车换行符进行分割,例如FTP协议;
- (3) 将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段,通常设计思路为消息头的第一个字段使用int32来表示消息的总长度;
- (4) 更复杂的应用层协议。
【2】Netty半包解码器解决TCP粘包/拆包问题
为了解决TCP粘包/拆包导致的半包读写问题,Netty默认提供了多种编解码器用于处理半包,使其解决TCP粘包问题变得非常容易,主要有:
- LineBasedFrameDecoder
- DelimiterBasedFrameDecoder(添加特殊分隔符报文来分包)
- FixedLengthFrameDecoder(使用定长的报文来分包)
- LengthFieldBasedFrameDecoder
① LineBasedFrameDecoder解码器
LineBasedFrameDecoder是回车换行解码器,如果用户发送的消息以回车换行符作为消息结束的标识,则可以直接使用Netty的LineBasedFrameDecoder对消息进行解码,只需要在初始化Netty服务端或者客户端时将LineBasedFrameDecoder正确的添加到ChannelPipeline中即可,不需要自己重新实现一套换行解码器。
LineBasedFrameDecoder的工作原理是它依次遍历ByteBuf中的可读字节,判断是否有“\n”或“\r\n”,如果有,就以此位置为结束位置,从可读索引到结束位置区间的字节就组成了一行。它是以换行符为结束标志的解码器,支持携带结束符或不携带结束符两种解码方式,同时支持配置单行的最大长度。如果连接读取到最大长度后仍然没有发现换行符,就会抛出异常,同时忽略掉之前读到的异常码流。防止由于数据报没有携带换行符导致接收到 ByteBuf 无限制积压,引起系统内存溢出。
通常LineBasedFrameDecoder会和StringDecoder搭配使用。StringDecoder的功能非常简单,就是将接收到的对象转换成字符串,然后继续调用后面的Handler。LineBasedFrameDecoder+StringDecoder组合就是按行切换的文本解码器,它本设计用来支持TCP的粘包和拆包。对于文本类协议的解析,文本换行解码器非常实用,例如对 HTTP 消息头的解析、FTP 协议消息的解析等。
使用起来十分简单,只需要在ChannelPipeline 中添加即可,如下所示:
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.childHandler(new ChannelInitializer() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(new LineBasedFrameDecoder(1024));
p.addLast(new StringDecoder());
p.addLast(new StringEncoder());
p.addLast(new LineServerHandler());
}
});
② DelimiterBasedFrameDecoder解码器
DelimiterBasedFrameDecoder是分隔符解码器,用户可以指定消息结束的分隔符,它可以自动完成以分隔符作为码流结束标识的消息的解码。回车换行解码器实际上是一种特殊的DelimiterBasedFrameDecoder解码器。
使用起来十分简单,只需要在ChannelPipeline 中添加即可,如下所示:
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.childHandler(new ChannelInitializer() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(new DelimiterBasedFrameDecoder(1024, Unpooled.copiedBuffer(Constants.DELIMITER.getBytes())));
p.addLast(new StringDecoder());
p.addLast(new StringEncoder());
p.addLast(new DelimiterServerHandler());
}
});
首先将“$_”转换成 ByteBuf 对象,作为参数构造 DelimiterBasedFrameDecoder,将其添加到 ChannelPipeline 中,然后依次添加字符串解码器(通常用于文本解码)和用户 Handler,请注意解码器和 Handler 的添加顺序,如果顺序颠倒,会导致消息解码失败。
DelimiterBasedFrameDecoder 原理分析:解码时,判断当前已经读取的 ByteBuf 中是否包含分隔符 ByteBuf,如果包含,则截取对应的 ByteBuf 返回,源码如下:
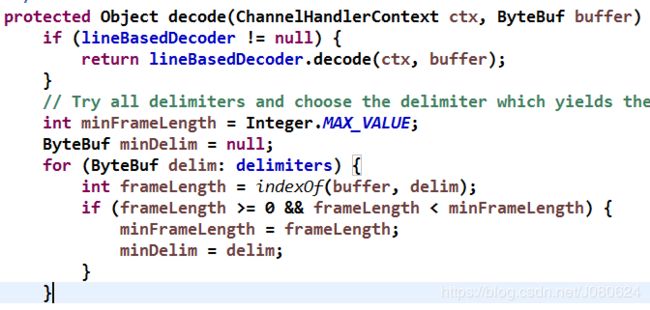
③ FixedLengthFrameDecoder解码器
FixedLengthFrameDecoder是固定长度解码器,它能够按照指定的长度对消息进行自动解码,开发者不需要考虑TCP的粘包/拆包等问题,非常实用。
对于定长消息,如果消息实际长度小于定长,则往往会进行补位操作,它在一定程度上导致了空间和资源的浪费。但是它的优点也是非常明显的,编解码比较简单,因此在实际项目中仍然有一定的应用场景。
使用起来十分简单,只需要在ChannelPipeline 中添加即可,如下所示:
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 100)
.handler(new LoggingHandler(LogLevel.INFO))//配置日志输出
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(new FixedLengthFrameDecoder(1<<5));
ch.pipeline().addLast(new StringDecoder());
ch.pipeline().addLast(new StringEncoder());
ch.pipeline().addLast(new ServerHandler());
}
});
利用 FixedLengthFrameDecoder 解码器,无论一次接收到多少数据报,它都会按照构造函数中设置的固定长度进行解码,如果是半包消息,FixedLengthFrameDecoder 会缓存半包消息并等待下个包到达后进行拼包,直到读取到一个完整的包。
④ LengthFieldBasedFrameDecoder解码器
大多数的协议(私有或者公有),协议头中会携带长度字段,用于标识消息体或者整包消息的长度,例如SMPP、HTTP协议等。由于基于长度解码需求的通用性,以及为了降低用户的协议开发难度,Netty提供了LengthFieldBasedFrameDecoder,自动屏蔽TCP底层的拆包和粘包问题,只需要传入正确的参数,即可轻松解决“读半包“问题。
下面我们看看如何通过参数组合的不同来实现不同的“半包”读取策略。第一种常用的方式是消息的第一个字段是长度字段,后面是消息体,消息头中只包含一个长度字段。它的消息结构定义如图所示:
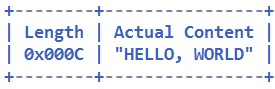
解码前的字节缓冲区(14 字节)
使用以下参数组合进行解码:
-
lengthFieldOffset = 0;
-
lengthFieldLength = 2;
-
lengthAdjustment = 0;
-
initialBytesToStrip = 0。
解码后的字节缓冲区内容如图所示:
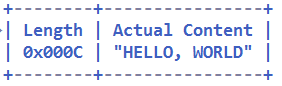
通过 ByteBuf.readableBytes() 方法我们可以获取当前消息的长度,所以解码后的字节缓冲区可以不携带长度字段,由于长度字段在起始位置并且长度为 2,所以将 initialBytesToStrip 设置为 2,参数组合修改为:
-
lengthFieldOffset = 0;
-
lengthFieldLength = 2;
-
lengthAdjustment = 0;
-
initialBytesToStrip = 2。
解码后的字节缓冲区内容如图所示:
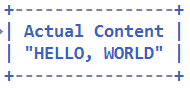
解码后的字节缓冲区丢弃了长度字段,仅仅包含消息体,对于大多数的协议,解码之后消息长度没有用处,因此可以丢弃。
参考博文:
Netty基础入门学习
Netty4TCP粘包&拆包解决方案
Netty系列之Netty编解码框架分析