selenium - 元素的定位和添加等待
注意: 本文使用的是火狐的webdriver, 要求火狐浏览器必须是 54 一下版本
getckodriver也最好不要下载最新的版本
1.chromedriver 下载地址:https://code.google.com/p/chromedriver/downloads/list
2.Firefox的驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/
3.IE的驱动IEdriver 下载地址:http://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
最简单的脚本
# coding=utf-8
from selenium import webdriver
import time
# 选择浏览器 这里选择谷歌,IE,或者火狐都可以,不过要安装对应的webdriver
browser = webdriver.Firefox()
# 需要打开的网页,输入URL
browser.get("http://www.baidu.com")
# 根据当前网页的唯一特性定位输入框,百度的首页比较简单,输入框id为"kw"且不重复,所以我们使用id来定位
# send_keys(value) 是向这个输入框中输入value值
browser.find_element_by_id("kw").send_keys("selenium")
# 为了能使我们看到效果,我们让网页睡眠3秒
time.sleep(3)
# 通过id寻找按钮框,这里的"su"也是唯一的
# click() 是点击事件
browser.find_element_by_id("su").click()
time.sleep(3)
# 利用quit关闭窗口且释放资源
browser.quit()值得注意的是
-
我们定位一个位置时,必须确保你查找的依据是唯一的

我们打开到开发者工具,定位到搜索框,看到这里的id是"kw",且根据观察,发现这个id只出现了一次,所以用id来定位
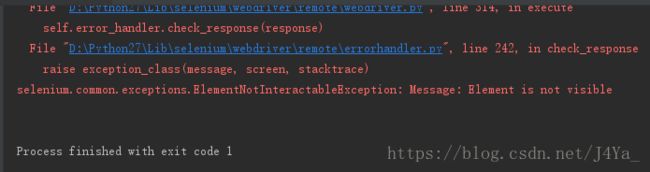
举一个会定位失败的例子:
browser.find_element_by_tag_name("input").send_keys("selenium") # 将面的 by_id 换成 by_tag_name,这里的 tag_name 是 input 标签

显然,这个网页中的 input 标签很多,运行以后,页面停止到打开百度首页,编译器报错
元素的定位
| id |
find_element_by_id() |
|
| name |
find_element_by_name() |
|
| class name |
find_element_by_class_name() |
|
| link text |
find_element_by_link_text() | 有时候我们要定位的不是一个输入框,也不是一个按键,而是一个文字,这时候就可以用link_text获取 |
| partial link text |
find_element_by_partial_link_text() |
进行部分定位,比如上面的好123,我们可以定位hao |
| tag name |
find_element_by_tag_name() |
|
| xpath |
find_element_by_xpath() | 可通过chrome的F12开发者模式中的Element-右键-copy-copy xpath获取 |
| css seletor |
find_element_by_css_seletor() |
可通过chrome的F12开发者模式中的Element-右键-copy-copy seletor获取 |
注意: 不管是哪种方式,必须保证页面上该属性的唯一性
上面的定位方式中,只有 xpath 是一定一定唯一的
这是百度输入框的属性:
-
find_element_by_id("kw")
- find_element_by_name("wd")
- find_element_by_tag_name("input")
-
find_element_by_class_name("s_ipt")
-
find_element_by_css_seletor("#kw")
-
find_element_by_xpath("//*[@id="kw"]")
-
find_element_by_link_text("hao123")
browser = webdriver.Firefox()
browser.get("http://www.baidu.com")
browser.find_element_by_link_text("hao123").click()
time.sleep(2)
browser.quit()添加等待
上面我们已经看到了一种等待方式
import time
time.sleep(5)
智能等待: 相比较 time.sleep() 的固定等待时间, implicitly_wait() 似乎更只能一些,可以在一个固定范围内等待
用法:
browser.implicitly_wait(30)