机器学习的100道练习题

61-70
Q66. 如果回归模型中存在多重共线性(multicollinearity),应该如何解决这一问题而不丢失太多信息(多选)?
A. 剔除所有的共线性变量
B. 剔除共线性变量中的一个
C. 通过计算方差膨胀因子(Variance Inflation Factor,VIF)来检查共线性程度,并采取相应措施
D. 删除相关变量可能会有信息损失,我们可以不删除相关变量,而使用一些正则化方法来解决多重共线性问题,例如 Ridge 或 Lasso 回归。
答案:BCD
解析:如果回归模型中存在共线性变量,那么可以采取相应措施,剔除共线性变量中的一个。为了检验多重共线性,我们可以创建一个相关矩阵来识别和去除相关度在 75% 以上的变量(阈值大小可人为设置)。此外,我们可以使用计算方差膨胀因子(VIF)来检查多重共线性的存在。若 VIF <= 4 则没有多重共线性,若 VIF>10 值意味着严重的多重共线性。此外,我们可以使用容忍度作为多重共线性的指标。
方差膨胀因子(Variance Inflation Factor,VIF):是指解释变量之间存在多重共线性时的方差与不存在多重共线性时的方差之比。VIF 跟容忍度是倒数关系。详细介绍可自行查阅统计学资料。
但是,去除相关变量可能导致信息的丢失。为了保留这些变量,我们可以使用正则化来“惩罚”回归模型,如 Ridge 和 Lasso 回归。此外,我们可以添加一些随机噪声相关变量,使变量变得彼此不同。但是,增加噪声可能会影响预测精度,因此应该谨慎使用这种方法。
Q67. 评估完模型之后,发现模型存在高偏差(high bias),应该如何解决?
A. 减少模型的特征数量
B. 增加模型的特征数量
C. 增加样本数量
D. 以上说法都正确
答案:B
解析:如果模型存在高偏差(high bias),意味着模型过于简单。为了使模型更加健壮,我们可以在特征空间中添加更多的特征。而添加样本数量将减少方差。

Q68. 在构建一个决策树模型时,我们对某个属性分割节点,下面四张图中,哪个属性对应的信息增益最大?
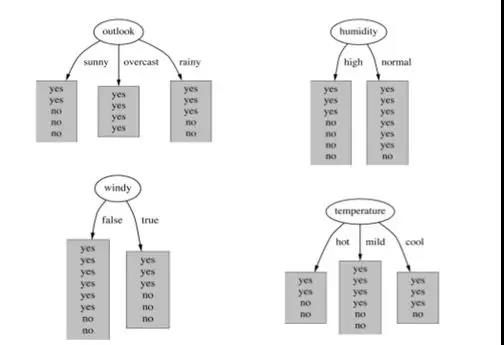
A. outlook
B. humidity
C. windy
D. temperature
答案:A
解析:李航的《统计学习方法》中,对信息增益有如下定义:特征 A 对训练数据集 D 的信息增益 g(D,A),定义为集合 D 的经验熵 H(D) 与特征 A 给定条件下 D 的经验条件熵 H(D|A) 之差,即
g(D,A) = H(D) - H(D|A)
这一题,我们先计算经验熵 H(D):
H(D) = -9/14 * log(9/14) - 5/14 * log(5/14)
= 0.6518
图一中,经验条件熵 H(D|A) 为:
H(D|A) = 5/14 * (-2/5*log(2/5)-3/5*log(3/5))
+ 4/14 *(-1*log(1)-0)
+ 5/14 * (-3/5*log(3/5)-2/5*log(2/5))
= 0.4807
图一的信息增益为:
g(D,A) = H(D) - H(D|A) = 0.6518 - 0.4807
= 0.1711
图二中,经验条件熵 H(D|A) 为:
H(D|A) = 7/14 * (-3/7*log(3/7)-4/7*log(4/7))
+ 7/14 * (-6/7*log(6/7)-1/7*log(1/7))
= 0.5465
图二的信息增益为:
g(D,A) = H(D) - H(D|A) = 0.6518 - 0.5465
= 0.1053
图三中,经验条件熵 H(D|A) 为:
H(D|A) = 8/14 * (-6/8*log(6/8)-2/8*log(2/8))
+ 6/14 * (-3/6*log(3/6)-3/6*log(3/6))
= 0.6184
图三的信息增益为:
g(D,A) = H(D) - H(D|A) = 0.6518 - 0.6184
= 0.0334
图四中,经验条件熵 H(D|A) 为:
H(D|A) = 4/14 * (-2/4*log(2/4)-2/4*log(2/4))
+ 6/14 *(-4/6*log(4/6)-2/6*log(2/6))
+ 4/14 * (-3/4*log(3/4)-1/4*log(1/4))
= 0.6315
图四的信息增益为:
g(D,A) = H(D) - H(D|A) = 0.6518 - 0.6315
= 0.0203
显然,图一 outlook 对应的信息增益最大。
Q69. 在决策树分割结点的时候,下列关于信息增益说法正确的是(多选)?
A. 纯度高的结点需要更多的信息来描述它
B. 信息增益可以用”1比特-熵”获得
C. 如果选择一个属性具有许多特征值, 那么这个信息增益是有偏差的
答案: BC
Q70. 如果一个 SVM 模型出现欠拟合,那么下列哪种方法能解决这一问题?
A. 增大惩罚参数 C 的值
B. 减小惩罚参数 C 的值
C. 减小核系数(gamma参数)
答案:A
解析:SVM模型出现欠拟合,表明模型过于简单,需要提高模型复杂度。
Soft-Margin SVM 的目标为:

C 值越大,相应的模型越复杂。接下来,我们看看 C 取不同的值时,模型的复杂程度。
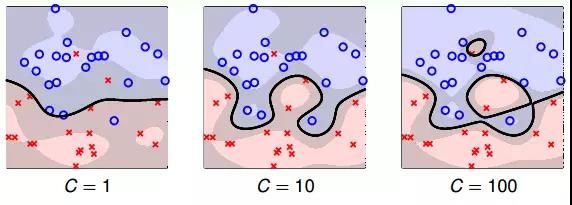
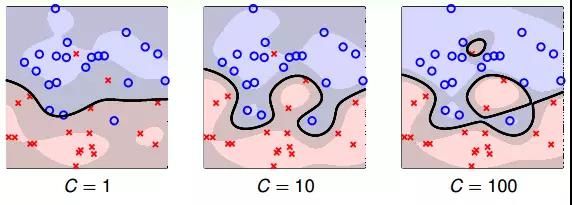
从上图可以看出,C=1 时,模型比较简单,分类错误的点也比较多,发生欠拟合。当 C 越来越大的时候,模型越来越复杂,分类错误的点也在减少。但是,当 C 值很大的时候,虽然分类正确率提高,但很可能把 noise 也进行了处理,从而可能造成过拟合。
而对于 SVM 的核函数,同样,核系数越大,模型越复杂。举个例子,核系数分别取 1, 10, 100 时对应的分类效果如下:

从图中可以看出,当核系数比较小的时候,分类线比较光滑。当核系数越来越大的时候,分类线变得越来越复杂和扭曲,直到最后,分类线变成一个个独立的小区域。为什么会出现这种区别呢?这是因为核系数越大,其对应的核函数越尖瘦,那么有限个核函数的线性组合就比较离散,分类效果并不好。所以, SVM 也会出现过拟合现象,核系数的正确选择尤为重要,不能太小也不能太大。
71-80
Q71. 假设我们在支持向量机(SVM)算法中对 Gamma(RBF 核系数 γ)的不同值进行可视化。由于某种原因,我们忘记了标记伽马值的可视化。令 g1、g2、g3 分别对应着下面的图 1、图 2 和图 3。则关于 g1、g2、g3 大小下列说法正确的是?
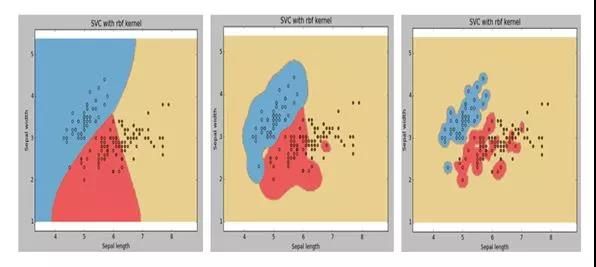
A. g1 > g2 > g3
B. g1 = g2 = g3
C. g1 < g2 < g3
D. g1 > g2 = g3
E. g1 < g2 = g3
答案:C
解析:本题考查的是 Kernel SVM 中 Gamma γ 对模型形状的影响。
SVM 中为了得到更加复杂的分类面并提高运算速度,通常会使用核函数的技巧。径向基核函数(RBF)也称为高斯核函数是最常用的核函数,其核函数的表达式如下所示:
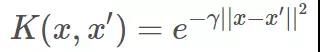
形式与高斯分布类似,Gamma γ 是高斯分布中标准差 Sigma σ 的导数。我们知道在高斯分布中,σ 越小,对应的高斯曲线就越尖瘦。也就是说 γ 越大,高斯核函数对应的曲线就越尖瘦。这样,运用核技巧得到的 SVM 分类面就更加曲折复杂,甚至会将许多样本隔离成单个的小岛。
下面是 γ 分别取 1、10、100 时对应的 SVM 分类效果:

值得一提的是,γ 过小容易造成欠拟合,γ 过大容易造成过拟合。
Q72. 我们知道二元分类的输出是概率值。一般设定输出概率大于或等于 0.5,则预测为正类;若输出概率小于 0.5,则预测为负类。那么,如果将阈值 0.5 提高,例如 0.6,大于或等于 0.6 的才预测为正类。则准确率(Precision)和召回率(Recall)会发生什么变化(多选)?
A. 准确率(Precision)增加或者不变
B. 准确率(Precision)减小
C. 召回率(Recall)减小或者不变
D. 召回率(Recall)增大
答案:AC
Q73. 点击率预测是一个正负样本不平衡问题(例如 99% 的没有点击,只有 1% 点击)。假如在这个非平衡的数据集上建立一个模型,得到训练样本的正确率是 99%,则下列说法正确的是?
A. 模型正确率很高,不需要优化模型了
B. 模型正确率并不高,应该建立更好的模型
C. 无法对模型做出好坏评价
D. 以上说法都不对
答案:B
解析:这一题延续了上题中准确率和召回率的知识点,考查了正负样本分布不均问题。
模型训练过程中正负样本分布不均是常见的问题。这时候不能单独只看预测正确率。对于此题来说,如果我们预测的结果是 100% 没有点击,0% 点击,那么可以说正确率是 99%,因为只有 1% 的点击预测错误。但是,我们其实更关心的那 1% 的点击率并没有预测出来。可以说这样的模型是没有任何意义的。
对应正负样本不平衡的情况需要做一些数据处理,主要包括:采样、数据合成、惩罚因子加权、一分类。其中,一分类即是在正负样本分布极不平衡的时候,把它看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。这类方法的重点不在于捕捉类间的差别,而是为其中一类进行建模,经典的工作包括 One-class SVM 等。
Q74. 假设我们使用 kNN 训练模型,其中训练数据具有较少的观测数据(下图是两个属性 x、y 和两个标记为 “+” 和 “o” 的训练数据)。现在令 k = 1,则图中的 Leave-One-Out 交叉验证错误率是多少?
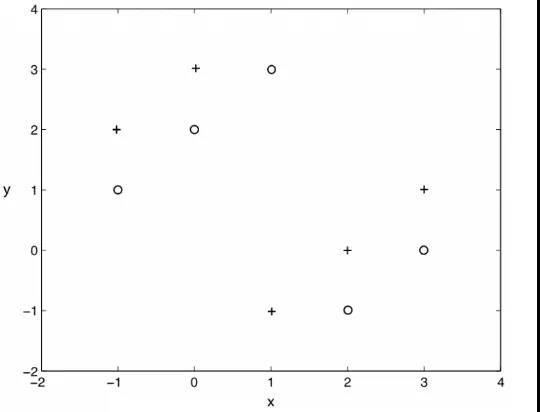
A. 0%
B. 20%
C. 50%
D. 100%
答案:D
解析:本题考查的是 kNN 算法和 Leave-One-Out 交叉验证。
kNN 算法是标记类算法,取当前实例最近邻的 k 个样本,k 个样本中所属的最多类别即判定为该实例的类别。本题中 k = 1,则只需要看最近邻的那一个样本属于“+” 还是“o”即可。
Leave-One-Out 交叉验证是一种用来训练和测试分类器的方法,假定数据集有N 个样本,将这个样本分为两份,第一份 N-1 个样本用来训练分类器,另一份 1 个样本用来测试,如此迭代 N 次,所有的样本里所有对象都经历了测试和训练。
分别对这 10 个点进行观察可以发现,每个实例点最近邻的都不是当前实例所属的类别,因此每次验证都是错误的。整体的错误率即为 100%。
Q75. 如果在大型数据集上训练决策树。为了花费更少的时间来训练这个模型,下列哪种做法是正确的?
A. 增加树的深度
B. 增加学习率
C. 减小树的深度
D. 减少树的数量
答案:C
解析:本题考查的是决策树相关概念。
一般用决策树进行分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点。这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分类,直至达到叶结点。最后将实例分到叶结点的类中。—— 引自李航 《统计学习方法》
决策树深度越深,在训练集上误差会越小,准确率越高。但是容易造成过拟合,而且增加模型的训练时间。对决策树进行修剪,减小树的深度,能够提高模型的训练速度,有效避免过拟合。
单决策树中,学习率不是一个有效参数。
决策树是单树,随机森林由多个决策树组成。
Q76. 关于神经网络,下列说法正确的是?
A. 增加网络层数,可能会增加测试集分类错误率
B. 增加网络层数,一定会增加训练集分类错误率
C. 减少网络层数,可能会减少测试集分类错误率
D. 减少网络层数,一定会减少训练集分类错误率
答案:AC
解析:本题考查的是神经网络层数对训练误差和测试误差的影响。
一般来说,神经网络层数越多,模型越复杂,对数据的分类效果越好。所以,从最简单的层数开始,增加网络层数都能使得训练误差和测试误差减小。但是,神经网络层数过多容易造成过拟合,即对训练样本分类效果很好,误差小,但是测试误差很大。
为了避免发生过拟合,应该选择合适的神经网络层数并使用正则化技术来让神经网络更加稳健。
Q77. 假设我们使用原始的非线性可分版本的 Soft-SVM 优化目标函数。我们需要做什么来保证得到的模型是线性可分离的?
A. C = 0
B. C = 1
C. C 正无穷大
D. C 负无穷大
答案:C
解析:本题考查的是 SVM 和 Soft-SVM 之间的联系和彼此转化条件。
Soft-SVM 在原来的 SVM 基础上增加了分类错误项,如下式:

其中,第二项即为分类错误项。C 为参数类似于正则化中的惩罚因子。其中, ξn 表示每个点犯错误的程度,ξn = 0,表示没有错误,ξn 越大,表示错误越大,即点距离边界(负的)越大。参数 C 表示尽可能选择宽边界和尽可能不要犯错两者之间的权衡,因为边界宽了,往往犯错误的点会增加。large C 表示希望得到更少的分类错误,即不惜选择窄边界也要尽可能把更多点正确分类;small C 表示希望得到更宽的边界,即不惜增加错误点个数也要选择更宽的分类边界。因此,C 正无穷大时,可以实现没有分类错误的点,模型线性可分。
从另一方面来看,线性可分 SVM 中,对偶形式解得拉格朗日因子 αn≥0;而在 Soft-SVM 中,对偶形式解得拉格朗日因子 0 ≤ αn ≤ C。显然,当 C 无正无穷大的时候,两者形式相同。
值得一提的是,当 C 值很大的时候,虽然分类正确率提高,但很可能把 noise 也进行了处理,从而可能造成过拟合。也就是说 Soft-SVM 同样可能会出现过拟合现象,所以参数 C 的选择非常重要。下图是 C 分别取1、10、100时,相应的分类曲线:
Q78. 在训练完 SVM 之后,我们可以只保留支持向量,而舍去所有非支持向量。仍然不会影响模型分类能力。这句话是否正确?
A. 正确
B. 错误
答案:A
解析:本题考查的是对支持向量机 SVM 的概念理解。
其实,刚学习支持向量机时会有个疑问,就是为什么会叫这个名字。该算法决定分类面的一般是关键的几个点,这几个点构建了分类面,因此被称为支持向量。该算法也就叫支持向量机了。训练完毕之后,其它非支持向量对分类面并无影响,去掉无妨。
对于线性可分的 SVM,可以根据拉格朗日因子 αn 数值来判断当前样本 (xn, yn) 是否为 SV。
- 若 αn = 0:不是 SV
- 若 αn > 0:是 SV,且分类正确

对于 Soft-SVM(线性不可分),可以根据拉格朗日因子 αn 数值与参数 C 的关系来判断当前样本 (xn, yn) 是否为 SV。
- 若 αn = 0:不是 SV,且分类正确
- 若 0 < αn < C:是 SV
- 若 αn = C:不是 SV,且分类错误(或恰好位于分类面上)

对 SVM 概念不太清楚的同学可以看看林轩田机器学习技法 1-6 对 SVM 的讲解,通俗易懂,内容翔实。对应的笔记可以在本公众号查阅,放上第 1 讲链接:
Q79. 下列哪些算法可以用来够造神经网络(多选)?
A. kNN
B. 线性回归
C. 逻辑回归
答案:BC
解析:本题考查的是 kNN、线性回归、逻辑回归与神经网络之间的一些关系。
kNN 是一种基于实例的学习算法,不具有任何训练参数。因此不能用来构造神经网络。
线性回归和逻辑回归都可以用来构造神经网络模型,其实二者就是单神经元的神经网络。
Q80. 下列数据集适用于隐马尔可夫模型的是?
A. 基因数据
B. 影评数据
C. 股票市场价格
D. 以上所有
答案:D
解析:本题考查的是隐马尔可夫模型适用于解决哪类问题。
隐马尔可夫模型(Hidden Markov Model,HMM)是关于时序的概率模型,描述一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观察而产生观测随机序列的过程。因此,隐马尔可夫模型适用于解决时间序列问题。
81-90
Q81. 我们想要训练一个 ML 模型,样本数量有 100 万个,特征维度是 5000,面对如此大数据,如何有效地训练模型(多选)?
A. 对训练集随机采样,在随机采样的数据上建立模型
B. 尝试使用在线机器学习算法
C. 使用 PCA 算法减少特征维度
答案:ABC
解析:本题考查的是如何解决样本数量和特征维度过大的问题。
在有限的内存下,如何处理高特征纬度的训练样本是一项非常艰巨的任务。下面这些方法可以用来解决这一问题。
我们可以随机抽样数据集,包括样本数量和特征数量。这意味着,我们可以创建一个更小的数据集,比如说,有 1000 个特征和 300000 个样本进行训练。
使用在线学习(online learning)算法
使用主成分分析算法(PCA)挑选有效的特征,去除冗余特征。
关于在线学习与离线学习,离线学习是我们最为常见的一种机器学习算法模式,使用全部数据参与训练。训练完成,整个模型就确定了;而在线学习一般每次使用一个数据或是小批量数据进行训练,每次训练都会优化模型,模型处于不断优化更改状态。
PCA(principal Component Analysis),是一种使用最广泛的数据压缩算法。在PCA中,数据从原来的坐标系转换到新的坐标系,由数据本身决定。转换坐标系时,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。第一个新坐标轴选择的是原始数据中方差最大的方法,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向。重复该过程,重复次数为原始数据的特征维数。
什么是冗余特征呢?比如汽车数据中,里面既有以“千米/每小时”度量特征,也有“英里/小时”的特征,显然这两个特征有一个是多余的。
Q82. 我们希望减少数据集中的特征数量。你可以采取以下哪一个步骤来减少特征(多选)?
A. 使用正向选择法(Forward Selection)
B. 使用反向消除法(Backward Elimination)
C. 逐步选择消除法(Stepwise)
D. 计算不同特征之间的相关系数,删去相关系数高的特征之一
答案:ABCD
解析:本题考查的是机器学习模型中特征选择问题。
正向选择(Forward Selection)是首先选择一个特征,每个特征都试一遍,选择对模型准确率提升最高的那个特征;然后再在这个特征基础上添加另外一个特征,方法类似,直到模型准确率不再提示为止。
反向消除(Backward Elimination)是首先包含了所有的特征,然后尝试删除每个特征,最终删掉对模型准确率提升最高的一个特征(因为删除这个特征,模型准确率反而增加了,说明是无用特征)。如此类推,直到删除特征并不能提升模型为止。
相对于 Forward Selection,Backward Elimination 的优点在于其允许一些低贡献值的特征能够进到模型中去(有时候低贡献值的特征能在组合中有更大的贡献值,而 Forward Selection 忽略了这种组合的可能性),因此Backward Elimination能够避免受一两个占主导地位的特征的干扰。
另外还有一种特征选择方法是 Stepwise,该方法结合上述两者的方法,新加入一个特征之后,再尝试删去一个特征,直至达到某个预设的标准。这种方法的缺点是,预设的标准不好定,而且容易陷入到过拟合当中。
除此之外,也可以使用基于相关性的特征选择,可以去除多重线性特征。例如上一题中“千米/每小时”和“英里/小时”是相关性很大的特征,可删其一。
Q83. 下面关于 Random Forest 和 Gradient Boosting Trees 说法正确的是?
A. Random Forest 的中间树不是相互独立的,而 Gradient Boosting Trees 的中间树是相互独立的
B. 两者都使用随机特征子集来创建中间树
C. 在 Gradient Boosting Trees 中可以生成并行树,因为它们是相互独立的
D. 无论任何数据,Gradient Boosting Trees 总是优于 Random Forest
答案:B
解析:本题考查的是随机森林和梯度提升树(GBDT)的基本概率和区别。
Random Forest 是基于 Bagging 的,而 Gradient Boosting Trees 是基于 Boosting 的。Bagging 和 Boosting 的区别在于:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等。
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成。
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
因此,Gradient Boosting Trees 的中间树不是相互独立的,因为前一棵树的结果影响下一棵树。Random Forest 的中间树相互独立,因此可以并行生成这些树。
在这两种算法中,我们使用随机特征集来生成中间树。
Gradient Boosting Trees 并不总比 Random Forest 好,依赖于数据。
Q84. “对于 PCA 处理后的特征,其朴素贝叶斯特征相互独立的假设一定成立,因为所有主成分都是正交的,所以不相关”。这句话是否正确?
A. True
B. False
答案:B
解析:本题考查的是 PCA 和 朴素贝叶斯的基本概率和区别。
这句话有两处错误:一是 PCA 转换之后的特征不一定不相关;二是不相关并不等价于相互独立。
正交和不相关没有必然关系,只有当一个随机变量的统计平均等于零时,正交和不相关等价。
独立则必定不相关,而不相关却不一定互相独立,只有是高斯时独立和不相关才等价。
Q85. 下列关于 PCA 说法正确的是(多选)?
A. 在使用 PCA 之前,我们必须标准化数据
B. 应该选择具有最大方差的主成分
C. 应该选择具有最小方差的主成分
D. 可以使用 PCA 在低维空间中可视化数据
答案:ABD
解析:本题考查的是主成分分析(PCA)的基本概念和推导原理。
PCA 对数据中变量的尺度非常敏感,因此我们需要对各个变量进行标准化。方法是减去各自变量的均值,除以标准差。
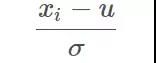
举个例子,假如某个变量单位从 km 改成 cm,大大增加了其方差,那么该变量可能就成为了主成分。这是我们不希望看大的。
B 是正确的,因为我们总是选择方差最大的主成分。可以这么来理解,方差越大,说明在该特征上分布越广泛,说明该特征月有用,影响越大。
PCA 有时在较低维度上绘制数据是非常有用。例如我们可以提取前 2 个主要组成部分,然后在二维平面上使用散点图可视化数据。
Q86. 下图中,主成分的最佳数目是多少?

A. 10
B. 20
C. 30
D. 无法确定
答案:C
解析:本题考查的是 PCA 的基本概念。
显然,当主成分数目为 30 的时候,积累的方差比例最大。
Q87. 数据科学家经常使用多个算法进行预测,并将多个机器学习算法的输出(称为“集成学习”)结合起来,以获得比所有个体模型都更好的更健壮的输出。则下列说法正确的是?
A. 基本模型之间相关性高
B. 基本模型之间相关性低
C. 集成方法中,使用加权平均代替投票方法
D. 基本模型都来自于同一算法
答案:B
解析:本题考查的是集成学习的基本原理。
集成学习,顾名思义,通过将多个单个学习器集成/组合在一起,使它们共同完成学习任务。
举个例子来说明,假如你有 T 个朋友,每个朋友向你预测推荐明天某支股票会涨还是会跌,那么你该选择哪个朋友的建议呢?第一种方法是从 T 个朋友中选择一个最受信任,对股票预测能力最强的人,直接听从他的建议就好。这是一种普遍的做法,对应的就是 validation 的思想,即选择犯错误最小的模型。第二种方法,如果每个朋友在股票预测方面都是比较厉害的,都有各自的专长,那么就同时考虑 T 个朋友的建议,将所有结果做个投票,一人一票,最终决定出对该支股票的预测。这种方法对应的是 uniformly 思想。第三种方法,如果每个朋友水平不一,有的比较厉害,投票比重应该更大一些,有的比较差,投票比重应该更小一些。那么,仍然对 T 个朋友进行投票,只是每个人的投票权重不同。这种方法对应的是 non-uniformly 的思想。第四种方法与第三种方法类似,但是权重不是固定的,根据不同的条件,给予不同的权重。比如如果是传统行业的股票,那么给这方面比较厉害的朋友较高的投票权重,如果是服务行业,那么就给这方面比较厉害的朋友较高的投票权重。以上所述的这四种方法都是将不同人不同意见融合起来的方式,这就是集成思想,即把多个基本模型结合起来,得到更好的预测效果。
通常来说,基本模型之间的相关性越低越好,因为每个模型有各自的特长,集成起来才更加强大。
Q88. 如何在监督式学习中使用聚类算法(多选)?
A. 首先,可以创建聚类,然后分别在不同的集群上应用监督式学习算法
B. 在应用监督式学习算法之前,可以将其类别 ID 作为特征空间中的一个额外的特征
C. 在应用监督式学习之前,不能创建聚类
D. 在应用监督式学习算法之前,不能将其类别 ID 作为特征空间中的一个额外的特征
答案:AB
解析:本题考查的是聚类算法与监督式学习。
我们可以为不同的集群构建独立的机器学习模型,并且可以提高预测精度。将每个类别的 ID 作为特征空间中的一个额外的特征可能会提高的精度结果。
Q89. 下面哪句话是正确的?
A. 机器学习模型的精准度越高,则模型的性能越好
B. 增加模型的复杂度,总能减小测试样本误差
C. 增加模型的复杂度,总能减小训练样本误差
D. 以上说法都不对
答案:C
解析:本题考查的是机器学习模型的评判指标。
机器学习模型的精准度(Precision)越高,模型性能不一定越好,还要看模型的召回率(Recall),特别是在正负样本分布不均的情况下。一般使用 F1 score 评判标准。

增加模型复杂度,通常可能造成过拟合。过拟合的表现是训练样本误差减小,而测试样本误差增大。
Q90. 关于 GBDT 算法,下列说法正确的是(多选)?
A. 增加用于分割的最小样本数量,有助于避免过拟合
B. 增加用于分割的最小样本数量,容易造成过拟合
C. 减小每个基本树的样本比例,有助于减小方差
D. 减小每个基本树的样本比例,有助于减小偏差
答案:AC
解析:本题考查的是 GBDT 的基本概念。
节点中用于分割所需的最小样本数用来控制过拟合。过高的值可能导致欠拟合,因此,它应该使用交叉验证进行调整。
每个基本树选择的样本比例是通过随机抽样来完成的。小于1的值能够减小方差使模型具有鲁棒性。典型值 0.8 通常工作良好,但可以进一步精细调整。
GBDT 通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的,因为训练的过程是通过降低偏差来不断提高最终分类器的精度。
91-100
Q91. 下面哪个对应的是正确的 KNN 决策边界?
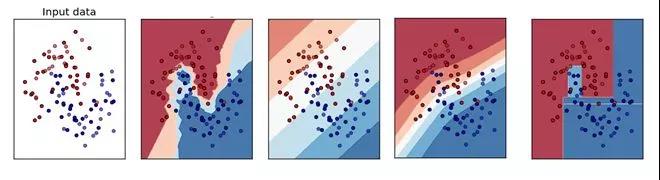
A. A
B. B
C. C
D. D
答案:A
解析:本题考查的是 KNN 的相关知识点。
KNN 分类算法是一个比较成熟也是最简单的机器学习(Machine Learning)算法之一。该方法的思路是:如果一个样本在特征空间中与K个实例最为相似(即特征空间中最邻近),那么这 K 个实例中大多数属于哪个类别,则该样本也属于这个类别。其中,计算样本与其他实例的相似性一般采用距离衡量法。离得越近越相似,离得越远越不相似。因此,决策边界可能不是线性的。
Q92. 如果一个经过训练的机器学习模型在测试集上达到 100% 的准确率,这是否意味着该模型将在另外一个新的测试集上也能得到 100% 的准确率呢?
A. 是的,因为这个模型泛化能力已经很好了,可以应用于任何数据
B. 不行,因为还有一些模型不确定的东西,例如噪声
答案:B
解析:本题考查的是机器学习泛化能力与噪声。
现实世界的数据并不总是无噪声的,所以在这种情况下,我们不会得到 100% 的准确度。
Q93. 下面是交叉验证的几种方法:
Bootstrap
留一法交叉验证
5 折交叉验证
重复使用两次 5 折交叉验证
请对上面四种方法的执行时间进行排序,样本数量为 1000。
A. 1 > 2 > 3 > 4
B. 2 > 4 > 3 > 1
C. 4 > 1 > 2 >3
D. 2 > 4 > 3 > 1
答案:D
解析:本题考查的是 k 折交叉验证和 Bootstrap 的基本概念。
Bootstrap 是统计学的一个工具,思想就是从已有数据集 D 中模拟出其他类似的样本 Dt。Bootstrap 的做法是,假设有 N 笔资料,先从中选出一个样本,再放回去,再选择一个样本,再放回去,共重复 N 次。这样我们就得到了一个新的 N 笔资料,这个新的 Dt 中可能包含原 D 里的重复样本点,也可能没有原 D 里的某些样本,Dt 与 D 类似但又不完全相同。值得一提的是,抽取-放回的操作不一定非要是 N,次数可以任意设定。例如原始样本有 10000 个,我们可以抽取-放回 3000 次,得到包含 3000 个样本的 Dt 也是完全可以的。因此,使用 bootstrap 只相当于有 1 个模型需要训练,所需时间最少。
留一法(Leave-One-Out)交叉验证每次选取 N-1 个样本作为训练集,另外一个样本作为验证集,重复 N 次。因此,留一法相当于有 N 个模型需要训练,所需的时间最长。
5 折交叉验证把 N 个样本分成 5 份,其中 4 份作为训练集,另外 1 份作为验证集,重复 5 次。因此,5 折交叉验证相当于有 5 个模型需要训练。
2 次重复的 5 折交叉验证相当于有 10 个模型需要训练。
Q94. 变量选择是用来选择最好的判别器子集, 如果要考虑模型效率,我们应该做哪些变量选择的考虑?(多选)
A. 多个变量是否有相同的功能
B. 模型是否具有解释性
C. 特征是否携带有效信息
D. 交叉验证
答案:ACD
解析:本题考查的是模型特征选择。
如果多个变量试图做相同的工作,那么可能存在多重共线性,影响模型性能,需要考虑。如果特征是携带有效信息的,总是会增加模型的有效信息。我们需要应用交叉验证来检查模型的通用性。关于模型性能,我们不需要看到模型的可解释性。
Q95. 下面有关分类算法的准确率,召回率,F1 值的描述,错误的是?
A.准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率
B.召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率
C.正确率、召回率和 F 值取值都在 0 和 1 之间,数值越接近 0,查准率或查全率就越高
D.为了解决准确率和召回率冲突问题,引入了F1分数
答案:C
解析:对于二类分类问题常用的评价指标是精准度(precision)与召回率(recall)。通常以关注的类为正类,其他类为负类,分类器在测试数据集上的预测或正确或不正确,4种情况出现的总数分别记作:
TP——将正类预测为正类数
FN——将正类预测为负类数
FP——将负类预测为正类数
TN——将负类预测为负类数
精准率定义为:P = TP / (TP + FP)
召回率定义为:R = TP / (TP + FN)
F1值定义为: F1 = 2PR / (P + R)
精准率和召回率和 F1 取值都在 0 和 1 之间,精准率和召回率高,F1 值也会高,不存在数值越接近 0 越高的说法,应该是数值越接近 1 越高。
Q96.
Q97. 如下图所示,对同一数据集进行训练,得到 3 个模型。对于这 3 个模型的评估,下列说法正确的是?(多选)

A. 第一个模型的训练误差最大
B. 第三个模型性能最好,因为其训练误差最小
C. 第二个模型最稳健,其在测试集上表现应该最好
D. 第三个模型过拟合
答案:ACD
解析:本题考查的是机器学习模型欠拟合、过拟合概念。
很简单,第一个模型过于简单,发生欠拟合,训练误差很大,在训练样本和测试样本上表现都不佳。第二个模型较好,泛化能力强,模型较为健壮,在训练样本和测试样本上表现都不错。第三个模型过于复杂,发生过拟合,训练样本误差虽然很小,但是在测试样本集上一般表现很差,泛化能力很差。
模型选择应该避免欠拟合和过拟合,对于模型复杂的情况可以选择使用正则化方法。
Q98. 如果使用线性回归模型,下列说法正确的是?
A. 检查异常值是很重要的,因为线性回归对离群效应很敏感
B. 线性回归分析要求所有变量特征都必须具有正态分布
C. 线性回归假设数据中基本没有多重共线性
D. 以上说法都不对
答案:A
解析:本题考查的是线性回归的一些基本原理。
异常值是数据中的一个非常有影响的点,它可以改变最终回归线的斜率。因此,去除或处理异常值在回归分析中一直是很重要的。
了解变量特征的分布是有用的。类似于正态分布的变量特征对提升模型性能很有帮助。例如,数据预处理的时候经常做的一件事就是将数据特征归一化到(0,1)分布。但这也不是必须的。
当模型包含相互关联的多个特征时,会发生多重共线性。因此,线性回归中变量特征应该尽量减少冗余性。C 选择绝对化了。
Q99. 建立线性模型时,我们看变量之间的相关性。在寻找相关矩阵中的相关系数时,如果发现 3 对变量(Var1 和 Var2、Var2 和 Var3、Var3 和 Var1)之间的相关性分别为 -0.98、0.45 和 1.23。我们能从中推断出什么呢?(多选)
A. Var1 和 Var2 具有很高的相关性
B. Var1 和 Var2 存在多重共线性,模型可以去掉其中一个特征
C. Var3 和 Var1 相关系数为 1.23 是不可能的
答案:ABC
解析:本题考查的是相关系数的基本概念。
Q100. 如果自变量 X 和因变量 Y 之间存在高度的非线性和复杂关系,那么树模型很可能优于经典回归方法。这个说法正确吗?
A. 正确
B. 错误
答案:A
解析:本题考查的是回归模型的选择。
当数据是非线性的时,经典回归模型泛化能力不强,而基于树的模型通常表现更好。