《C标准库》——之
在没读
比如:
int isdigit(int c){
return ( ((char)c >= '0' && (char)c <='9') ? 1 : 0 );
}在没有阅读源码之前,可能大多数人都会这么做,其实这样做是正确的。但是我在看了源码之后,才发现标准库并不是这样来实现这些函数的。是靠转换表来高效的实现的。
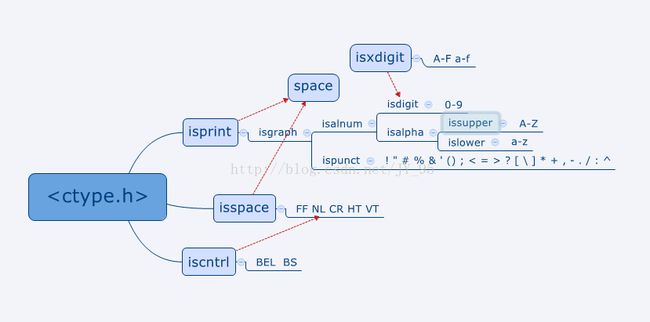
这是的字符类别(第一次用Xmind6这玩意...)
内容:
isalnum(int c): 判别所有isalpha或者isdigit判别为真的字符。
isalpha(int c): 判别所有isupper或者islower判别为真的字符,或者那些实现定义的字符集中的iscntrl、isdigit、ispunct、和isspace判别都不为真的字符。
iscntrl(int c); 判别所有的控制字符。
isdigit(int c); 判别所有的十进制数字字符。
isgraph(int c); 判别除空格(' ')之外的所有打印字符。
islower(int c); 判别所有的小写字母。
isprint(int c); 判别包括空格(' ')在内的所有打印字符。
ispunct(int c); 判别除空格(' ')和isalnum判别为真的字符之外的所有打印字符。
isspace(int c); 判别所有标准的空白字符,或者由实现定义的字符集中isalnum判别为假的字符。标准空白字符有:空格(' ')、换页('\f')、换行('\n')、回车('\r')、水平制表符('\t')和垂直制表符('\v')。
isupper(int c); 判别所有的大写字母。
isxdigit(int c); 判别所有的十六进制数字字符。
tolower(int c); 函数tolower把一个大写字母转换为小写字母。
toupper(int c); 函数toupper把一个小写字母转换为大写字母。
实现:大部分好的实现都把EOF值定义为-1,所以转换表中元素的数目一定比字符类型所能表示的所有字符的数目多1。所以一个转换表中一定至少包含257个元素。#ifndef _CTYPE
#define _CTYPE
/* _Ctype code bits */
#define _XA 0X200/* extra alphabetic */
#define _XS 0x100 /* extra space */
#define _BB 0x80 /* BEL, BS, etc. */
#define _CN 0x40 /* CR, FF, HT, NL, VT */
#define _DI 0x20 /* '0' - '9' */
#define _LO 0x10 /* 'a' - 'z' */
#define _PU 0x08 /* punctuation */
#define _SP 0x04 /* space */
#define _UP 0x02 /* 'A' - 'Z' */
#define _XD 0x01 /* '0' - '9', 'A' - 'F', 'a' - 'f' */
/* declarations */
int isalnum(int), int alpha(int),int iscntrl(int), int isdigit(int);
int isgraph(int), int islower(int),int isprint(int), int ispunct(int);
int isspace(int), int isupper(int),int isxdigit(int);
int tolower(int), inttoupper(int);
extern const short *_Ctype, *_Tolower, *_Toupper;
/* macro */
#define isalnum(c)(_Ctype[(int)c] & (_DI | _LO | _UP | _XA))
#define isalpha(c)(_Ctype[(int)c] & (_LO | _UP | _XA))
#define iscntrl(c)(_Ctype[(int)c] & (_BB | _CN))
#define isdigit(c)(_Ctype[(int)c] & (_DI))
#define isgraph(c)(_Ctype[(int)c] & (_DI | _LO | _PU | _UP | _XA))
#define islower(c)(_Ctype[(int)c] & (_LO))
#define isprint(c)(_Ctype[(int)c] & (_DI | _LO | _PU | _SP | _UP | _XA))
#define ispunct(c)(_Ctype[(int)c] & (_PU))
#define isspace(c)(_Ctype[(int)c] & (_CN | _SP | _XS))
#define isupper(c)(_Ctype[(int)c] & (_UP))
#define isxdigit(c)(_Ctype[(int)c] & (_XD))
#define tolower(c)_Tolower[(int)c]
#define toupper(c)_Toupper[(int)c]
#endif /* _CTYPE */还有这些函数的文件就不写了,举个例子,其他的都一样:int isalnum (int c)
{
return (_Ctype[(int)c] & (_DI | _LO | _UP | _XA));
}xctyoe.c 文件:
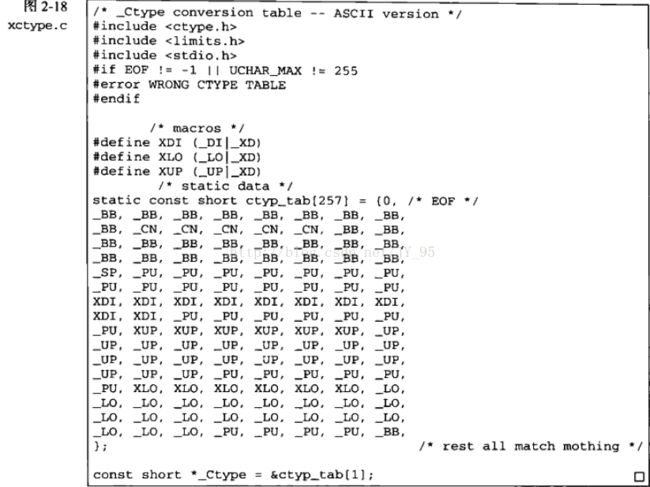
在这个转换表里的前面,我们还看到了三个宏定义:
#define XDI (_DI | _XD)
#define XLO (_LO | _XD)
#define XUP (_UP | _XD)加上这个三个宏定义后,我们在判断十六进制和十进制的'0' - '9'时,和判断十六进制的'A' - 'F'或'a' - 'f'和英文字母时,都可以得到正确的结果。
另外,xctype.c的最下面有个const指针,指向了转换表的第二个元素,因此转换表的第一个元素存储的就是EOF了。
下面来看看tolower和toupper函数,它们也各有一张转换表:
xtolower.c :

xupper.c :

在xtolower.c中,我们看到从ASCII码值为65开始,是小写字母,从97开始,依然是小写字母,所以这张表,当tolower函数传进去的是大写字母时,被转换为对应的小写字母,如果传进去的是小写字母,则不变。同理,xtoupper.c也是这样。至于表中剩余其它的值,我们不用管。
我们可能会想,自己写像如开头那样的函数实现也可以啊,转化表一做感觉代码挺长的,其实,