推荐系统算法-基于矩阵分解的CF算法实现(一):LFM
基于矩阵分解的CF算法实现(一):LFM
LFM也就是前面提到的Funk SVD矩阵分解
LFM原理解析
LFM(latent factor model)隐语义模型核心思想是通过隐含特征联系用户和物品,如下图:
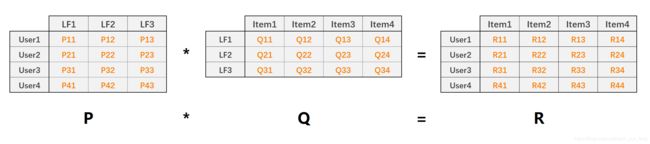




算法实现
- 数据加载
import pandas as pd
import numpy as np
dtype = [("userId", np.int32), ("movieId", np.int32), ("rating", np.float32)]
dataset = pd.read_csv("ml-latest-small/ratings.csv", usecols=range(3), dtype=dict(dtype))
- 数据初始化
# 用户评分数据 groupby 分组 groupby('userId') 根据用户id分组 agg(aggregation聚合)
users_ratings = dataset.groupby('userId').agg([list])
# 物品评分数据
items_ratings = dataset.groupby('movieId').agg([list])
# 计算全局平均分
global_mean = dataset['rating'].mean()
# 初始化P Q 610 9700 K值 610*K 9700*K
# User-LF 10 代表 隐含因子个数是10个
P = dict(zip(users_ratings.index,np.random.rand(len(users_ratings),10).astype(np.float32)
))
# Item-LF
Q = dict(zip(items_ratings.index,np.random.rand(len(items_ratings),10).astype(np.float32)
))
- 梯度下降优化损失函数
#梯度下降优化损失函数
for i in range(15):
print('*'*10,i)
for uid,iid,real_rating in dataset.itertuples(index = False):
#遍历 用户 物品的评分数据 通过用户的id 到用户矩阵中获取用户向量
v_puk = P[uid]
# 通过物品的uid 到物品矩阵里获取物品向量
v_qik = Q[iid]
#计算损失
error = real_rating-np.dot(v_puk,v_qik)
# 0.02学习率 0.01正则化系数
v_puk += 0.02*(error*v_qik-0.01*v_puk)
v_qik += 0.02*(error*v_puk-0.01*v_qik)
P[uid] = v_puk
Q[iid] = v_qik
- 评分预测
def predict(self, uid, iid):
# 如果uid或iid不在,我们使用全剧平均分作为预测结果返回
if uid not in self.users_ratings.index or iid not in self.items_ratings.index:
return self.globalMean
p_u = self.P[uid]
q_i = self.Q[iid]
return np.dot(p_u, q_i)
'''
LFM Model
'''
import pandas as pd
import numpy as np
# 评分预测 1-5
class LFM(object):
def __init__(self, alpha, reg_p, reg_q, number_LatentFactors=10, number_epochs=10, columns=["uid", "iid", "rating"]):
self.alpha = alpha # 学习率
self.reg_p = reg_p # P矩阵正则
self.reg_q = reg_q # Q矩阵正则
self.number_LatentFactors = number_LatentFactors # 隐式类别数量
self.number_epochs = number_epochs # 最大迭代次数
self.columns = columns
def fit(self, dataset):
'''
fit dataset
:param dataset: uid, iid, rating
:return:
'''
self.dataset = pd.DataFrame(dataset)
self.users_ratings = dataset.groupby(self.columns[0]).agg([list])[[self.columns[1], self.columns[2]]]
self.items_ratings = dataset.groupby(self.columns[1]).agg([list])[[self.columns[0], self.columns[2]]]
self.globalMean = self.dataset[self.columns[2]].mean()
self.P, self.Q = self.sgd()
def _init_matrix(self):
'''
初始化P和Q矩阵,同时为设置0,1之间的随机值作为初始值
:return:
'''
# User-LF
P = dict(zip(
self.users_ratings.index,
np.random.rand(len(self.users_ratings), self.number_LatentFactors).astype(np.float32)
))
# Item-LF
Q = dict(zip(
self.items_ratings.index,
np.random.rand(len(self.items_ratings), self.number_LatentFactors).astype(np.float32)
))
return P, Q
def sgd(self):
'''
使用随机梯度下降,优化结果
:return:
'''
P, Q = self._init_matrix()
for i in range(self.number_epochs):
print("iter%d"%i)
error_list = []
for uid, iid, r_ui in self.dataset.itertuples(index=False):
# User-LF P
## Item-LF Q
v_pu = P[uid] #用户向量
v_qi = Q[iid] #物品向量
err = np.float32(r_ui - np.dot(v_pu, v_qi))
v_pu += self.alpha * (err * v_qi - self.reg_p * v_pu)
v_qi += self.alpha * (err * v_pu - self.reg_q * v_qi)
P[uid] = v_pu
Q[iid] = v_qi
# for k in range(self.number_of_LatentFactors):
# v_pu[k] += self.alpha*(err*v_qi[k] - self.reg_p*v_pu[k])
# v_qi[k] += self.alpha*(err*v_pu[k] - self.reg_q*v_qi[k])
error_list.append(err ** 2)
print(np.sqrt(np.mean(error_list)))
return P, Q
def predict(self, uid, iid):
# 如果uid或iid不在,我们使用全剧平均分作为预测结果返回
if uid not in self.users_ratings.index or iid not in self.items_ratings.index:
return self.globalMean
p_u = self.P[uid]
q_i = self.Q[iid]
return np.dot(p_u, q_i)
def test(self,testset):
'''预测测试集数据'''
for uid, iid, real_rating in testset.itertuples(index=False):
try:
pred_rating = self.predict(uid, iid)
except Exception as e:
print(e)
else:
yield uid, iid, real_rating, pred_rating
if __name__ == '__main__':
dtype = [("userId", np.int32), ("movieId", np.int32), ("rating", np.float32)]
dataset = pd.read_csv("datasets/ml-latest-small/ratings.csv", usecols=range(3), dtype=dict(dtype))
lfm = LFM(0.02, 0.01, 0.01, 10, 100, ["userId", "movieId", "rating"])
lfm.fit(dataset)
while True:
uid = input("uid: ")
iid = input("iid: ")
print(lfm.predict(int(uid), int(iid)))