kaggle入门(python数据处理)
目前入坑机器学习machine learning,kaggle算是最著名的机器学习比赛(其实主要是特征工程),所以如果想走算法岗,光理论肯定不行,一定要实战,就拿kaggle开刀了,不求多好的结果,但求通过参与的过程对数据挖掘有更好的贴近数据项目的体验,最近与DC的Oliver组成了jo-team。开始一步一步踏坑了,下面是我看到的一些数据处理以及训练的方法,主要是python的。
best paactices
Performing feature correlation analysis early in the project.在项目初期进行特征相关分析。
Using multiple plots instead of overlays for readability.使用多个绘图而不是覆盖可读性。
data analysis and wrangling数据分析和清洗
import pandas as pd
import numpy as np
import random as rnd
visualization可视化
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
machine learning机器学习
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
获取数据
pandas包是数据处理的非常重要的包,可以用来获取处理和清理
train_df = pd.read_csv(‘../input/train.csv’)
test_df = pd.read_csv(‘../input/test.csv’)
combine = [train_df, test_df]
df.columns.size #获取列数
df.iloc[:, 0].size #获取行数
直接导出列名
print(train_df.columns.values)
[‘PassengerId”Survived”Pclass”Name”Sex”Age”SibSp”Parch”Ticket”Fare”Cabin”Embarked’]
列出数据集的各特征的类型,可以方便我们选取
train_df.info() 列出列名,数量,数据类型
train_df.head() 开始5行
train_df.tail() 结束5行
可以很好的看到数据的分布,或者检查是否有数据缺失
train_df.describe() 数据的描述(总数,平均值,std,最大\小值25%,50%,75%)对于数据的快速统计汇总
找出特征有几个出现的不同值,以及频率最高
train_df.describe(include=[‘O’])
通过groupby找出该特征与目标之间的关联
train_df[[‘Pclass’,Survived’]].groupby([‘Pclass’],as_index=False).mean().sort_values(by=’Survived’, ascending=False)
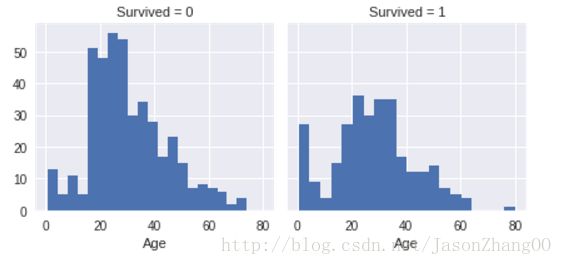
通过可视化工具,可以查看到一些特征,比如各年龄段和生存的相关性
g = sns.FacetGrid(train_df, col=’Survived’)
g.map(plt.hist, ‘Age’, bins=20)
比如age小于4的生存几率高,80岁的生存,大部分乘客是15-35,且15-25大量没有生存
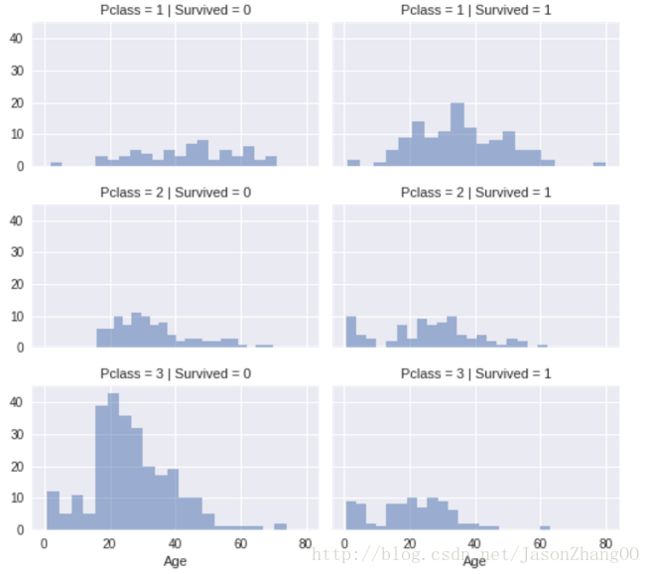
直方图纵向扩展,可以组合看到多个类别的比较
grid = sns.FacetGrid(train_df, col=’Survived’, row=’Pclass’, size=2.2, aspect=1.6)
grid.map(plt.hist, ‘Age’, alpha=.5, bins=20)
grid.add_legend();
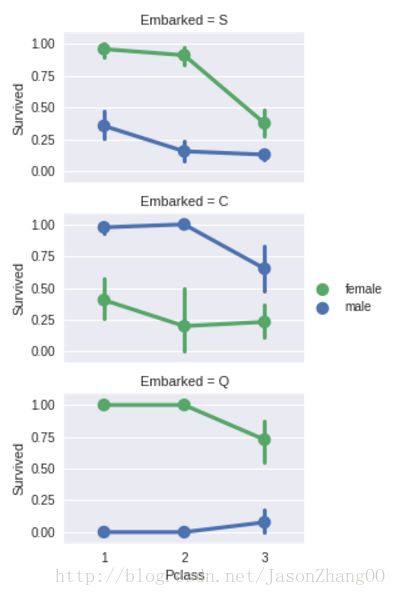
散点图将非数字型的特征进行关联(是否登记和性别对生存的影响)
grid = sns.FacetGrid(train_df, row=’Embarked’, size=2.2, aspect=1.6)
grid.map(sns.pointplot, ‘Pclass’, ‘Survived’, ‘Sex’, palette=’deep’)
grid.add_legend()
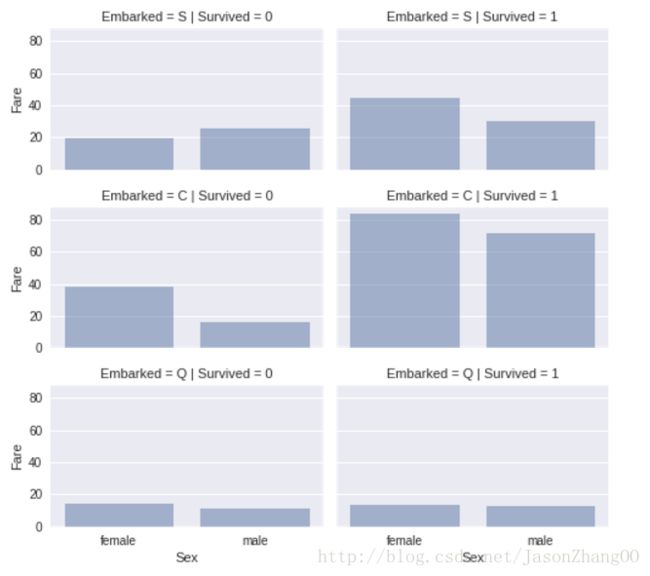
条形图将非数字型和数字型的特征进行关联,考虑将fare高低加入特征
grid = sns.FacetGrid(train_df, row=’Embarked’, col=’Survived’, size=2.2, aspect=1.6)
grid.map(sns.barplot, ‘Sex’, ‘Fare’, alpha=.5, ci=None)
grid.add_legend()
清洗数据
1.通过丢弃一些数据
这样我们可以处理更少的数据,可以加速我们的模型建立和训练,减轻了分析的任务,同时也避免了噪声的干扰。但是注意,最好训练和测试数据都要丢弃同样的数据
print(“Before”, train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop([‘Ticket’, ‘Cabin’], axis=1)
test_df = test_df.drop([‘Ticket’, ‘Cabin’], axis=1)
combine = [train_df, test_df]
2.从现有的数据中提取新特征
找出每个name缩写的人数
for dataset in combine:
dataset[‘Title’] = dataset.Name.str.extract(’ ([A-Za-z]+).’, expand=False)
pd.crosstab(train_df[‘Title’], train_df[‘Sex’])
可以将一些name进行合并成新的name,组成新特征
for dataset in combine:
dataset[‘Title’] = dataset[‘Title’].replace([‘Lady’, ‘Countess’,’Capt’, ‘Col’,\
‘Don’, ‘Dr’, ‘Major’, ‘Rev’, ‘Sir’, ‘Jonkheer’, ‘Dona’], ‘Rare’)
replace来替换-999这个值可能是一个表示缺失数据的标记值
dataset[‘Title’] = dataset[‘Title’].replace(‘Mlle’, ‘Miss’)
dataset[‘Title’] = dataset[‘Title’].replace(‘Ms’, ‘Miss’)
dataset[‘Title’] = dataset[‘Title’].replace(‘Mme’, ‘Mrs’)
train_df[[‘Title’, ‘Survived’]].groupby([‘Title’], as_index=False).mean()
一次性替换多个值,则传入一个由待替换值组成的列表以及替换值:data.replace([-999, -1000], np.nan)
对不同的值进行不同的替换,则传入一个替换关系组成的列表:data.replace([-999, -1000], [np.nan, 0])
传入的参数也可以是字典:data.replace({-999: np.nan, -1000: 0})
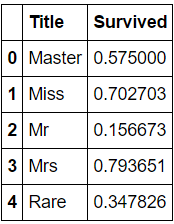
定义一个map函数,将字符型特征映射为数字型特征
fillna是填充缺失值
title_mapping = {“Mr”: 1, “Miss”: 2, “Mrs”: 3, “Master”: 4, “Rare”: 5}
for dataset in combine:
dataset[‘Title’] = dataset[‘Title’].map(title_mapping)
dataset[‘Title’] = dataset[‘Title’].fillna(0)
train_df.head()
3.转换字符型特征为数字型,使用map函数
4.填充缺失值
用cut将数据划分为各个面元bin
pd.qcut()将数据分为若干份,对应新的一列,元素为一个范围字符串,仍然需要量化
train_df[‘AgeBand’] = pd.cut(train_df[‘Age’], 5)
train_df[[‘AgeBand’, ‘Survived’]].groupby([‘AgeBand’],as_index=False).mean().sort_values(by=’AgeBand’, ascending=True)
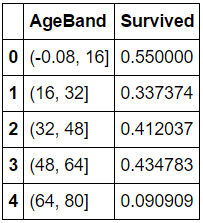
将age范围转换为数字型特征
for dataset in combine:
dataset.loc[ dataset[‘Age’] <= 16, ‘Age’] = 0
dataset.loc[(dataset[‘Age’] > 16) & (dataset[‘Age’] <= 32), ‘Age’] = 1
dataset.loc[(dataset[‘Age’] > 32) & (dataset[‘Age’] <= 48), ‘Age’] = 2
dataset.loc[(dataset[‘Age’] > 48) & (dataset[‘Age’] <= 64), ‘Age’] = 3
dataset.loc[ dataset[‘Age’] > 64, ‘Age’]
train_df.head()
5.组合旧特征创建新特征
组合sibsp和parch为familysize
for dataset in combine:
dataset[‘FamilySize’] = dataset[‘SibSp’] + dataset[‘Parch’] + 1
train_df[[‘FamilySize’, ‘Survived’]].groupby([‘FamilySize’], as_index=False).mean().sort_values(by=’Survived’, ascending=False)
根据familysize可以创建新特征isalone
for dataset in combine:
dataset[‘IsAlone’] = 0
dataset.loc[dataset[‘FamilySize’] == 1, ‘IsAlone’] = 1
使用dropna()函数来删除具有空数据的行或列
freq_port = train_df.Embarked.dropna().mode()[0]对于一列非数字,例如字符,要找到出现频率最高的字符赋值给missing值
我们对缺失值处理一般采用平均值填充(Mean/Mode Completer)
将信息表中的属性分为数值属性和非数值属性来分别进行处理。如果空值是数值型的,就根据该属性在其他所有对象的取值的平均值来填充该缺失的属性值;如果空值是非数值型的,就根据统计学中的众数原理,用该属性在其他所有对象的取值次数最多的值(即出现频率最高的值)来补齐该缺失的属性值。
模型预测,解决问题
常用模型:
Logistic Regression
Support Vector Machine
Naive Bayes classifier
Decision Tree
GBDT
Random Forest
xgboost
可以使用LR来验证我们的观察和假设
coeff_df = pd.DataFrame(train_df.columns.delete(0)) 删除第一列整型索引
coeff_df.columns = [‘Feature’] 增加新列
coeff_df[“Correlation”] = pd.Series(logreg.coef_[0])
coeff_df.sort_values(by=’Correlation’, ascending=False)
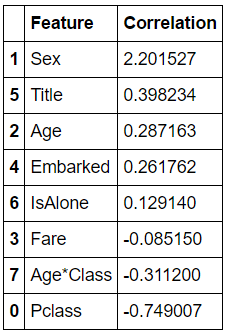
以下是一些可以尝试的优化模型的方法:
加入交互项(interaction)
减少特征变量
正则化(regularization)
使用非线性模型
参考:https://www.kaggle.com/startupsci/titanic/titanic-data-science-solutions