FPN的pytorch代码实现
论文地址:Feature Pyramid Networks for Object Detection
项目地址:FPN_pytorch
0x00 前言
我们在做目标检测和超分辨率重建等问题的时候,我们一般是对同一个尺寸的图片进行网络训练。我们希望我们的网络能够适应更多尺寸的图片,我们传统的做法使用图像金字塔,但是这种做法从侧面提升了计算的复杂度,我们希望可以改善这个问题,所以本文就提出了一种在特征图金字塔的方法,我们称这种网络结构叫做FPN。
0x01 论文分析
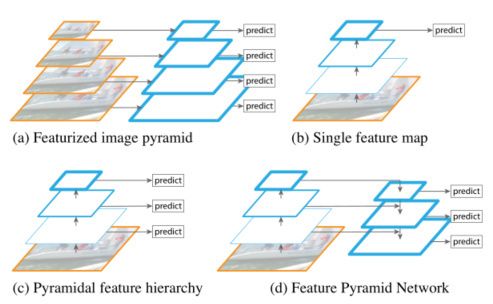
传统的图像金字塔任务是将不同尺度的图片进行特征提取(图a),主要使用人工提取特征,在人工提取特征的时代,大量使用特征化图像金字塔。它们非常重要,以至于像DPM这样的物体检测器需要密集的比例采样才能获得好的结果。但是这种做法变相的增加了训练数据,提高了运算耗时,所以这种做法已经很少被使用。
对于识别任务,工程特征已经被深度卷积网络(ConvNets)计算的特征大部分所取代。除了能够表示更高级别的语义,ConvNets不同层的特征图尺度也不同,从而有助于从单一输入尺度上计算的特征识别(图b)。但是这种做法的缺陷在于只使用了高分辨率特征,因为不同层之间的语义差别很大,最后一层主要都是高分辨率的特征,所以对于低分辨率的特征表现力不足。
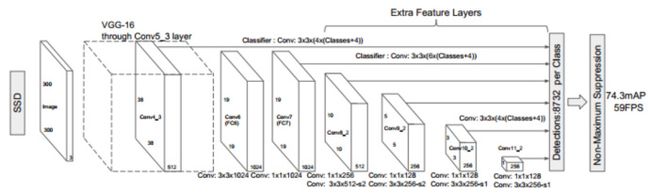
接着为了改善上面的做法,一个很简洁的改进就是对不同尺度的特征图都进行利用,这也是SSD算法中使用的方法(图c)。理想情况下,SSD风格的金字塔将重复使用正向传递中计算的不同层次的多尺度特征图。但为了避免使用低层次特征,SSD会从偏后的conv4_3开始构建特征金字塔,这种做法没有对conv4_3之前的层进行利用,而这些层对于检测小目标很重要。
本文提出一种新的做法(图d),通过高层特征进行上采样和低层特征进行自顶向下的连接,而且每一层都会进行预测。
0x02 网络结构
作者这里做了一个有意思的比较。如果我们不是对不同尺寸的特征图进行预测,而是将不同尺寸的特征图融合后进行预测,会怎么样呢?
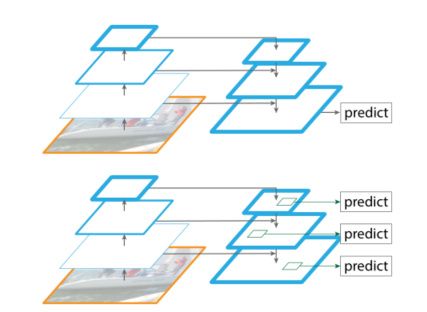
作者通过实验发现后者做法(也就是本文的做法)结果上会好很多。
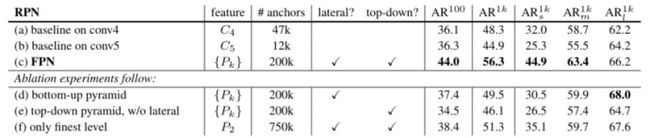
上图中的(f only finest level)就上通过不同尺度特征图融合后,只采用最后一层预测的结果。(d bottom-up pyramid)表示没有采用自顶向下的过程得到的结果。
作者的主网络是使用的ResNet,而特征图金字塔分成三个部分,一个自底向上的路径(左边),一个自顶向下的路径(右边)和中间的连接部分。
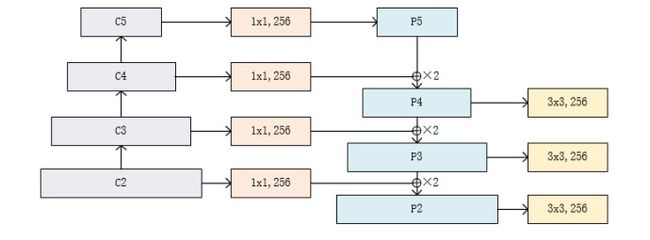
自底向上的路径:自下而上的路径是卷积网络的前馈计算,该算法计算由不同比例的特征映射组成的特征层级,其缩放步长为2。通常有许多层产生相同大小的输出映射,并且我们说这些层 处于相同的网络阶段。 对于我们的特征图金字塔,为每个阶段定义一个金字塔等级, 然后选择每个阶段的最后一层的输出作为我们特征图的参考集。 这种选择是自然的,因为每个阶段的最深层应具有最强的特征。
具体而言,对于ResNets,我们使用每个阶段的最后一个residual block输出的特征激活输出。 对于conv2,conv3,conv4和conv5输出,我们将这些最后residual block的输出表示为{C2,C3,C4,C5},并且它们相对于输入图像具有{4, 8, 16, 32} 的步长。 由于其庞大的内存占用,我们不会将conv1纳入金字塔中。
自顶向下的路径:自顶向下的路径通过对在空间上更抽象但语义更强高层特征图进行上采样来幻化高分辨率的特征。随后通过侧向连接从底向上的路径,使得高层特征得到增强。每个横向连接自底向上路径和自顶向下路径的特征图具有相同的尺寸。将低分辨率的特征图做2倍上采样(为了简单起见,使用最近邻上采样)。然后通过按元素相加,将上采样映射与相应的自底而上映射合并。这个过程是迭代的,直到生成最终的分辨率图。
为了开始迭代,我们只需在C5上附加一个1×1卷积层来生成低分辨率图P5。最后,我们在每个合并的图上附加一个3×3卷积来生成最终的特征映射,这是为了减少上采样的混叠效应。这个最终的特征映射集称为{P2,P3,P4,P5},分别对应于{C2,C3,C4,C5},它们具有相同的尺寸。
由于金字塔的所有层次都像传统的特征化图像金字塔一样使用共享分类器/回归器,因此我们在所有特征图中固定特征维度(通道数,记为d)。我们在本文中设置d = 256,因此所有额外的卷积层都有256个通道的输出。
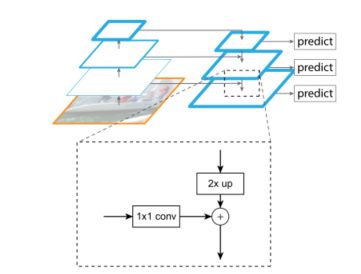
中间连接:采用1×1的卷积核进行连接(减少特征图数量)。
0x03 网络的具体实现
我们这里参考了pytorch的resnet的设计,关于resent的设计可以参看这篇ResNet理论基础与具体实现(详细教程)
class FPN(nn.Module):
def __init__(self, block, layers):
super(FPN, self).__init__()
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Bottom-up layers
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
# Top layer
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# Smooth layers
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != block.expansion * planes:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, block.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(block.expansion * planes)
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.upsample(x, size=(H,W), mode='bilinear') + y
def forward(self, x):
# Bottom-up
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
c1 = self.maxpool(x)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
# Top-down
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# Smooth
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
关于FPN的全部代码在这里:FPN_pytorch
如有任何问题,希望大家指出!!!