elasticsearch学习之IK分词器
本人目前由于公司需要,需要使用elasticsearch开发一个搜索引擎,由于之前没有接触过,所以需要学习这个框架,写这篇博客的目的,一是记录和分享自己的学习心得,与同样正在学习Es的同仁们一起学习,共同提高,其二在于抛砖引玉,希望可以听听各位大牛们的意见,所以篇中难免有错误之处,希望各位看官大牛们能及时帮我斧正,在此感激不尽。
进入正文:
Ik分词器是搜索引擎的一个很重要的插件,他为搜索引擎提供了分词服务,将一个词语拆分为多个词语,便于索引,比如,将“中华人民共和国”拆分成“中华”、“中华人民”、“共和国”等词汇,并保存至自己的词库中,方便用户进行索引服务。
IK分词器之学习:
首先在github下载到IK分词器的源码,由于我的ealsticsearch的版本是5.0.0,所以,相对我下载的IK分词器版本也是5.0.0版本。
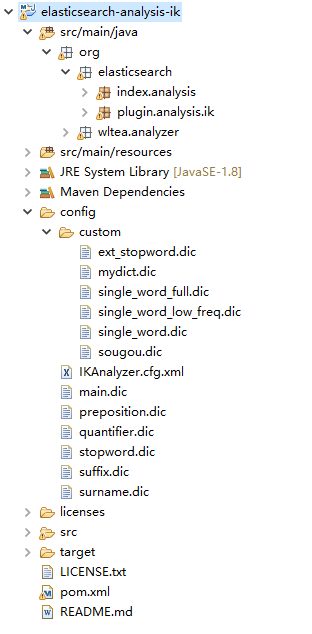
这是我在gitHub上下载到的IK分词器源码,使用maven导入后得到的目录树。
了解IK源码:

这是IK分词器的配置文件,我们调用IK分词器时,其相关内容,就是从这个配置文件当中查找的。
打开这个配置文件,我们会看到这一行,这个就是我们指定的IK分词器的地址
![]()
对应到pom.xml中,可以看到,我们指定的ik分词器的名称实际上是这个:
![]()
那么,对应到的java文件就是这个了:
![]()
这个就是我们的ik分词器源码,我们点开查看:
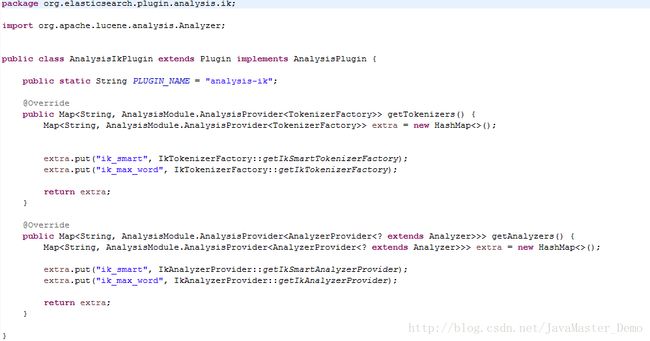
这其中的IkTokenizerFactory便是IK分词器工厂的具体类,实际上,我们的分词操作便是在这个类中完成的,我们查看这个类的源码:

可以看到,这个类有一个私有的变量,一个带参数的构造方法,值得注意的是
getIkTokenizerFactory和getIkSmartTokenizerFactory方法,这两个方法实际上是根据不同的分词方式而调用这两个不同的方法所获得的不同的ik工厂类,然后通过下面的getIkAnalyzerProvider和getIkSmartAnalyzerProvider分别得到各自的ik分词器对象,当然有关于这两种不同的分词器,我从gitHub上看到的他们的区别在这里:
所以,就不多做赘述。
当然,我们平时在公司中开发引擎的时候,一般来讲,由于信息的时效性,我们需要针对数据源定时的进行分词以便于索引,所以,这个方法我们还需要对其进行一些改动,在其中添加一个定时任务,来定时对IK词库进行添加分词操作。
所以,我们查看IkAnalyzerProvider类。
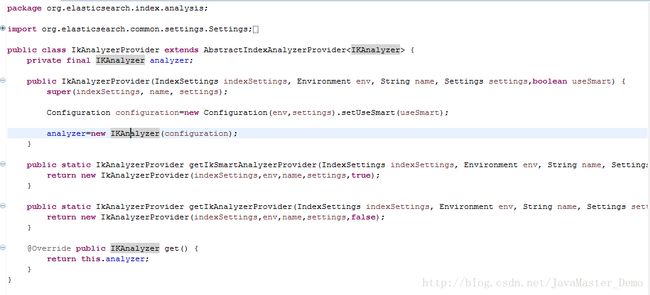
发现IKnalzeryzer对象需要一个Configuration参数来进行初始化,我们查看一下Configuration对象:
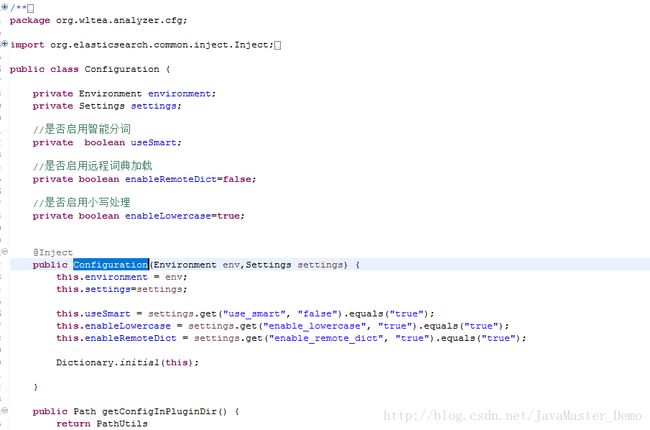
看到这里面其实已经初始化了一个Dictionary的词库对象了,所以,我们要将外部数据定时导入到该词库中,在这个地方添加一个定时任务就可以了。