【天池大数据竞赛】FashionAI全球挑战赛—服饰属性标签识别【决赛第21名解决方案】
项目在此:https://github.com/Jeremyczhj/FashionAI_Tianchi_2018
折腾了两个月的比赛终于结束了,名次出乎了最初的预料
但是也有些许不甘,毕竟前20都有奖励,尴尬的21名
想想有接近3000支队伍参赛,好像又心理平衡了不少![]()
比赛其实就是一个分类问题,给定衣服的图片然后分类到对应的标签上面去。数据集大致如下,看了两个月女装突然觉得自己可以去当个设计师,好多衣服都好丑好丑。


要进行分类的服装一共分成八个大类,每个大类下又细分成若干个子类,如下。如collar_design是一个大类,其下有5个子类。
task_list = {
'collar_design_labels': 5,
'neck_design_labels': 5,
'lapel_design_labels': 5,
'neckline_design_labels': 10,
'coat_length_labels': 8,
'skirt_length_labels': 6,
'pant_length_labels': 6,
'sleeve_length_labels': 9
}初赛思路:迁移学习
每个大类中,子类的样本相互独立。但是大类之间的样本不相互独立,最简单的办法就是对八个大类分别训练八个模型,相当于八个独立的分类器,再在测试集上用八个模型分别对八个类别进行预测。
优点:不用动脑;缺点:只用到当前大类的数据,而无法同时使用所有数据,泛化性能固然会差点
然后以77名进入复赛
复赛思路:迁移学习+多任务学习+模型融合
在此感谢杨培文大神在知乎提供的思路:
https://www.zhihu.com/question/48175729/answer/343242696
输入一张图片,有可能是识别这8个大类里面的任意一个类别。每一个输出都是一个softmax分类器,输入的图片将会在对应的分类器输出分类结果,也就是多输出。我将数据分成两个部分,一部分是包含领的所有类别,另一部分是包含长度的所有类别。然后训练两个模型,这两个模型都是多输出。结构如下图所示:
长度类别分类器模型结构:
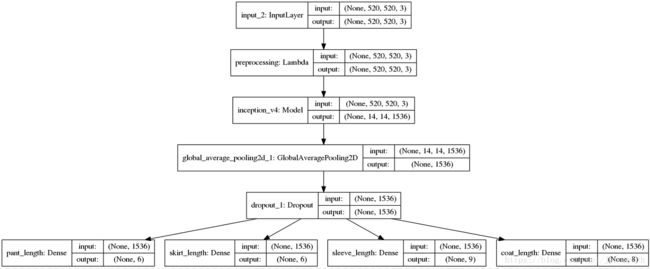
领子设计分类器模型结构:
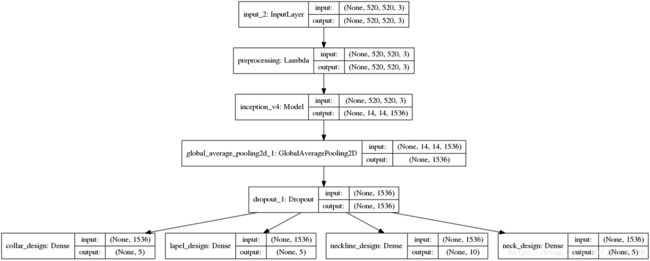
对应代码:
task_list_length = {
'pant_length_labels': 6,
'skirt_length_labels': 6,
'sleeve_length_labels': 9,
'coat_length_labels': 8
}
task_list_design = {
'collar_design_labels': 5,
'lapel_design_labels': 5,
'neckline_design_labels': 10,
'neck_design_labels': 5,
}base_model =inception_v4.create_model(weights='imagenet',width=width, include_top=False)
input = Input((width, width, 3))
x = input
x = Lambda(preprocess_input, name='preprocessing')(x)
x = base_model(x)
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = [Dense(count, activation='softmax', name=name)(x) for name, count in task_list.items()]
model = Model(input, x) 对应标签设定,分类不存在即设为0就行,会产生类似于[[0,0,0,0,0],[0,1,0,0,0,0],[0,0,0,0],[0,0,0,0,0]]的标签:
y = [np.zeros((n, task_list[x])) for x in task_list.keys()]训练两个模型并对预测结果取平均,得到更鲁棒的结果。
成绩提高技巧:
1、shuffle,打乱数据进行训练是必须的,防止相邻样本有较强相关性。
2、数据增广很重要,好的数据增广可以提高2-3个百分点,但是要注意方式,比如在这个问题上没有必要对图像上下反转。深度学习框架一般能够提供的图像增广方法很有限,需要使用额外的库进行,推荐imgaug,神器
附上使用的增广代码:
def customizedImgAug(input_img):
rarely = lambda aug: iaa.Sometimes(0.1, aug)
sometimes = lambda aug: iaa.Sometimes(0.25, aug)
often = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential([
iaa.Fliplr(0.5),
often(iaa.Affine(
scale={"x": (0.9, 1.1), "y": (0.9, 1.1)},
translate_percent={"x": (-0.1, 0.1), "y": (-0.12, 0)},
rotate=(-10, 10),
shear=(-8, 8),
order=[0, 1],
cval=(0, 255),
)),
iaa.SomeOf((0, 4), [
rarely(
iaa.Superpixels(
p_replace=(0, 0.3),
n_segments=(20, 200)
)
),
iaa.OneOf([
iaa.GaussianBlur((0, 2.0)),
iaa.AverageBlur(k=(2, 4)),
iaa.MedianBlur(k=(3, 5)),
]),
iaa.Sharpen(alpha=(0, 0.3), lightness=(0.75, 1.5)),
iaa.Emboss(alpha=(0, 1.0), strength=(0, 0.5)),
rarely(iaa.OneOf([
iaa.EdgeDetect(alpha=(0, 0.3)),
iaa.DirectedEdgeDetect(
alpha=(0, 0.7), direction=(0.0, 1.0)
),
])),
iaa.AdditiveGaussianNoise(
loc=0, scale=(0.0, 0.05 * 255), per_channel=0.5
),
iaa.OneOf([
iaa.Dropout((0.0, 0.05), per_channel=0.5),
iaa.CoarseDropout(
(0.03, 0.05), size_percent=(0.01, 0.05),
per_channel=0.2
),
]),
rarely(iaa.Invert(0.05, per_channel=True)),
often(iaa.Add((-40, 40), per_channel=0.5)),
iaa.Multiply((0.7, 1.3), per_channel=0.5),
iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5),
iaa.Grayscale(alpha=(0.0, 1.0)),
sometimes(iaa.PiecewiseAffine(scale=(0.01, 0.03))),
sometimes(
iaa.ElasticTransformation(alpha=(0.5, 1.5), sigma=0.25)
),
], random_order=True),
iaa.Fliplr(0.5),
iaa.AddToHueAndSaturation(value=(-10, 10), per_channel=True)
], random_order=True) # apply augmenters in random order
output_img = seq.augment_image(input_img)
return output_img3、图像标准化,计算数据集的std与mean,而不是直接使用imagenet的std与mean
4、增大图像的输入尺寸可获得客观的提升,本例最终使用了480*480的输入尺寸
4、选择合适的迁移学习方式,本例进行全局finetune比只训练最后1层或几层好很多
5、可以先用Adam快速收敛,后面阶段用SGD慢慢调
6、模型融合,举办方在复赛限制最多只能用两个模型是明智的,初赛都有队伍用接近10个模型进行融合,如此刷分就没意义了
7、对测试集图片进行增强,比如镜像,旋转,再预测并取平均。可以得到更鲁棒的结果。这里没有用到tencrop,因为样本有些特征在顶部或者底部,tencrop会将特征截走,导致成绩降低。
项目在此:https://github.com/Jeremyczhj/FashionAI_Tianchi_2018
赛组委送的伞,印着大大的fashion着实有点。。