Mycat作为中间件搭建Mysql主从复制---从选型到搭建的想法和记录
想了解本人简陋搭建过程的同学,可以忽略下面这一段:
**********************************************************************************************************************************************
首先,本次搭建的数据库架构没有很复杂,选型了 Mycat + Mysql 的 双主架构。
项目刚刚开始,考虑到业务量并不是很大,数据节点不需要很多,也不考虑分表、分库的情况。考虑太复杂,加大工作量的同时,项目使用的服务器等成本也会上升,从项目整体的角度来说,不合适。
但这个点也的确纳入到搭建时的考虑之中,因为毕竟mysql的性能下降点,应该在500W数据(没有实际验证过,网上查的资料),
公司发展顺利的话,大约两三年之后就会遇到该问题,尽量做到不给自己和后来的同时埋坑(但实际上肯定会有,这个点已经被无数次验证,当时觉得很好的东西,几年后回头就会觉得是一堆 xiang)。
Mycat 本身在我的理解来看,是一个基于java实现的 请求负载均衡中间件, 懂得java的同学应该会觉得很亲近,虽然我看到有人吐槽说这个中间件有坑,大神张老师也说:基于中间件的分布式都是伪分布式(现在还不是很明白这个概念)。嘛,不过我本身是学java的,当时项目考虑读写分离的时候,我也萌生过自己写一段基于拦截器的 读写分离模块,解析statement --- 判断使用哪一个数据源 --- 执行 --- 返回结果。 但真正往后考虑就发现, 有几个问题是老大难的: 1、 SQL 语句得了解的十分清楚,否则你写的解析部分会漏掉很多语句; 2、 分片规则、负载均衡问题 3、 读写分离模块和系统的耦合度太高。 所以这个想法在写了 select 和 insert 分发后,就基本停止了。 后来查资料了解到 Mycat , 买了本《分布式数据库架构及企业实践_基于Mycat中间件》 嗯,看了几章之后,发现自己写的那些的确是用不成,很多该考虑的地方都没有。
突然领悟到有些东西,如果你只停留在拿来即用的层面上,你是永远无法知道自己和大神有多大差距的。自己写写,你才会发觉:哦!原来我还有这么多不懂得地方。 这可能是之前开发的惯性所致,导入包,直接用方法,简单快捷,还能完成高效的完成工作任务,得克服自己的惰性。
******************************************************************************************************************************************
正篇开始:
mysql的安装可以参考这个: 里面有个网址,可以根据硬件条件生成my.cnf ,适合我们这种开发小白,刚入门的新手使用,不需要太了解 innodb 引擎原理,也基本能把默认设置的数据库,优化 50% 性能(jmeter自己测试的,见过开发做性能压测吗?哈哈,这个在后面一篇写,虽然我知道 jmeter 我只用了 1% 的功能,但好歹一天之内拿出了压测报告啊,现学现卖TT)
https://blog.csdn.net/Jerry_Pan1990/article/details/83822917
一、 搭建两台主主复制的mysql服务,网上有很多类似的教程,大家可以找一下,这里只写一下我觉得的关键点:
1、 mysql 服务的配置 my.cnf 中,关于复制的部分:
我采用的还是很老的复制方式,基于 file 和 偏移量的复制。 后期我了解到还有一种 GTID 复制方式,该方式基于全局事务,在主机上生成全局唯一的 事务 ID,并将该 ID 发送给 从机,进行主从复制。 这里由于本人是新手,且项目中开发很紧张,到完工的时候才了解到这种先进的方法,那时系统集成测试已经完成,不敢动了,所以还是介绍一下我实际中用到的 复制方式。
server-id=1 #主从的 id 应不一样
log-bin=master1_3306_log #主机日志
binlog-do-db=testdb1 # 需要进行主从复制的库
binlog-do-db=testdb2 # 多个数据库这么写
relay_log=testdb_relay-bin # 中级日志sync_binlog=1
# 满多少次事务进行主从复制
#(这个参数,我想尽可能快的复制,所以设置较小,但比较担心主从是否会交互太频繁,影响性能,待验证)
log-slave-updates=1
#表示, M1 ,和 M2 主主复制后, 是否对 各自主节点下的 从节点进行 复制;
2、 需要建立主从复制的用户: 我这里开得权限有点大:*.* 因为我发现仅指定某个库表时,会报错。
额,难道是同步时也要复制同步元数据? 希望有路过的大神指点一下。
由于这个权限开得很大哦,授权的时候一定得指定 IP 进行授权,否则你会发现别人用这个账户把你root密码给改了,哈哈。
create user 'mysql';
grant all privileges on *.* to 'mysql'@'xx.x.x.xxx' identified by 'gxxxxxxxx';
3、 开启 主库 A、 从库 B
进入到 A 中,通过 show master status; 查看 master 的 数据文件名 及 偏移量。
并把 查到的 这个数据放到 这个命令中,并在 B 库执行
CHANGE MASTER TO
MASTER_HOST='127.0.0.1', # A 的 IP
MASTER_PORT=3306, # A 的 端口
MASTER_USER='repl1', # A 的 复制账号
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=3917;
需要注意的是: 除非你确保当前库没有人使用,否则,你应该执行下面的锁库命令, 否则有人插入数据,你之前的一系列操作就白费了,因为 数据偏移量已经完全不对了。
FLUSH TABLES WITH READ LOCK; # 全局锁,注意执行完后别把窗口关闭, 因为这个命令只有当前session有效。
unlock tables; # 解锁
4、 start slave;
5、 验证;
二、 搭建mycat:
这个超级简单,下载 Mycat, 然后 tar -zxvf 解压后, 在 bin 目录下找到 mycat 可执行脚本:
./bin/mycat start 就OK了。 Mycat 的难点,在于其配置文件。
Mycat 的配置文件可以使用 Zookeeper 管理,如果要做多个 mycat 的架构,可以考虑,
我这里只使用了单节点,所以配置文件都是我这里写好了扔上去的。
引用《分布式数据库架构及企业实践_基于Mycat中间件》 中的一个图:
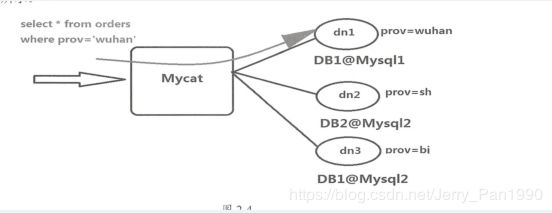
mycat 的核心原理:
1、 分片分析;
2、 路由分析;
3、读写分离分析;
4、缓存分析
这些功能的具体参数,都是在配置文件中实现的:
1、 schema.xml :
逻辑库、逻辑表(schema)、ER表(Table、childTable)、
分片表、分片节点(schema、dataNode) 、 分片主机、读写分离(dataHost)
(再引用一张哈)
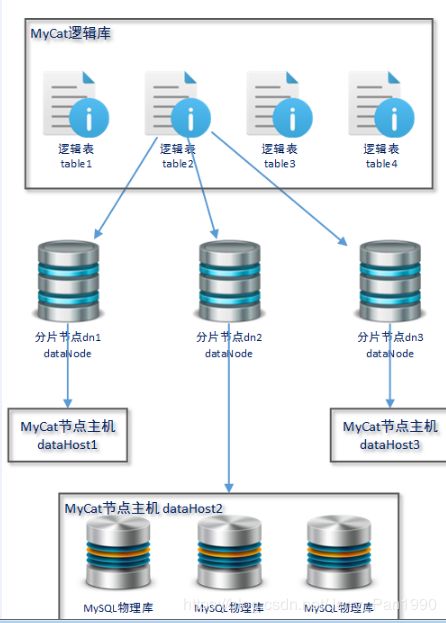
mycat 是通过在 物理库上 抽象出来 一个 数据节点层 , 进而抽象出 逻辑库的。
其透明性依赖于逻辑库层。
想弄明白 schema, 就得明白上面的图。 具体配置的配置参数,可以参考这两位大神的教程:
我自己生产的配置就不贴出来了。
https://blog.csdn.net/qq_35423294/article/details/78312669
https://blog.csdn.net/sds15732622190/article/details/72190120
2、 server.xml:
系统参数, 优化 mycat 的主要配置文件
需要注意,这个配置文件,应该是基于 schema 的, 可以这么说,你个人认为得先设计 数据节点结构、表结构、全局序列、分片算法后,再来配置、优化这个文件。
主要有三个标签:
(1)system 优化mycat
这里只说我自己,通过优化这三个参数,读性能在性能测试时较默认配置提升了近一倍,大家阔以试一下。

processors 我们服务器是 8 核,所以这里设置 8;
processorBufferChunk 使用的默认值;
processorBufferPool = 8 * 4096 * 100
(2) user: 需要注意,为什么说 server 的配置是基于 schema ,就是因为 user 配置的 库,其实都是抽象出来的逻辑库。
另外这个标签还可以配置这个用户的读写权限、连接数、是否加密
(3) quarantine 防火墙,指定白名单、黑名单
3、 log4j.xml 文件: mycat 的日志输出级别及目录修改;
以下这两个配置文件,主要用来切分数据节点: 本次我只有一个数据节点,没做切分,下面的知识没有实践过,仅仅是了解,大家随便参考一下:
4、 sequence: 全局序列文件,我本次没有使用,仅仅了解了一下: 其作用是解决 分库分表时的 自增主键问题;
一般有两种维护方式:
(1) 本地维护,sequence_conf.properties ,缺点是每次重启mycat,序列号重置(个人感觉会有问题)
(2) 固化到数据库:建立存放序列的表,
![]()
并插入一条数据:
![]()
current_value 为当前值, increment 为步长
创建函数,实现三个功能: 获取当前 sequence值,设置 sequence 值、 获取下一个sequence值。
需要注意, 这些东东都应该同一个数据节点完成,并在 sequence_conf.properties 中,通过 USER_SEQ=数据节点 指定。
5、 rule文件: 分表分库规则文件; 算法很多啦,这个就不做搬运工了,
大家有兴趣可以在教材中看一下,选取适合自己的分片算法。