Linux内存管理原理
=============================硬件原理及分页管理===============================
1.分页机制
分页机制是现代CPU实现内存寻址的一种机制(早期的intel芯片内存寻址实现机制有分段机制);
早期的CPU对内存的寻址是直接对物理内存(内存条)进行寻址,但这种在intel保护模式及现代CPU中已经很少使用,现代的CPU不会直接对物理内存(内存条)寻址,而是以虚拟地址(在intel保护模式下称为线性地址)进行内存寻址。CPU发出虚拟地址,借助内存管理单元MMU(硬件结构)和页表(软件数据结构)实现虚拟地址到物理地址的转换获得虚拟地址对应的物理地址,然后以获得的物理地址访问物理内存(内存条),即实现对物理内存(内存条)的寻址,具体如下图,其中的页表存放对页的说明,包括此页的虚实地址映射关系、是否命中(即虚拟地址是否分配物理内存)、RWX权限及kenerl/user权限等,每一个进程对应一张页表(或一系列页表),这张(或这些)页表能够覆盖全部的虚拟地址(对应32位芯片,则这些页表覆盖0~0xFFFFFFFF,即0~4G的虚拟地址);MMU中的页表地址寄存器存放页表地址,在多进程运行的芯片上,页表地址寄存器存放当前进程的页表地址,当CPU发出当前进程的虚拟地址给MMU后即可获得对应的物理内存(内存条)的地址。
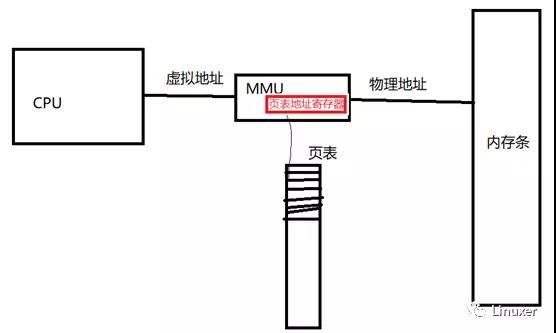
结合下图,比如CPU发出虚拟地址0x12345670给MMU,MMU从页表地址寄存器中存放的页表中查找0x12345670/4kB行,找到该行后根据是否命中及权限取出物理地址,如果没有命中引发page fault给虚拟地址分配物理内存,如果没有权限,会引发segv。
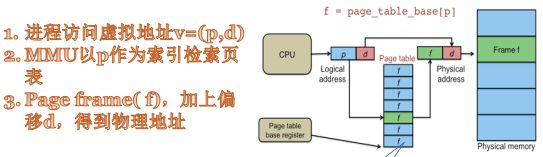
下图为页表的结构示意图

其中第0行、第1行...表示虚拟地址,每行相差4kByte(即一页的大小)
2.内存的Zone分区
内存分Zone是针对物理内存(内存条),分为ZONE_HIGH,ZONE_NORMAL和DMA_ZONE,其中ZONE_NORMAL和DMA_ZONE合成ZONE_LOW;
因为有的DMA硬件只能访问内存条的低32M的地址,因此分出DMA_ZONE用于弥补DMA硬件缺陷,如果DMA硬件可访问的内存条足够大,则不需要DMA_ZONE,这时内存条只分为ZONE_HIGH和ZONE_LOW;
Linux开机的时候,将ZONE_LOW的物理内存线性映射到虚拟地址为3G~4G的区域,linux内核在运行时使用3G~4G的虚拟地址,对应访问ZONE_LOW的物理内存;映射仅仅指在页表中完成了虚实地址的转换,但物理内存没有分配给内核,即没有命中,当内核运行时申请内存时才将物理内存分配给内核,同时应用程序在申请内存时也可以分配到ZONE_LOW的物理内存。
3.Buddy算法
Linux内核对物理内存(内存条)的管理使用Buddy算法,其他内存分配API如kmalloc/vmalloc/kmap以及maolloc都是基于Buddy算法之上进行二级内存管理,这些API不直接面对物理内存(内存条)。
Buddy算法将内存条的空闲页放到一些列的链表中,这些链表分别存放连续空闲1页、连续空闲2页、连续空闲24页、连续空闲28页、连续空闲216页、连续空闲232页内存等,如下图

当程序需要1页内存时,可以从1页空闲页链表中取出1页,如果需要4页内存时,可以从2页空闲页链表中取出2个2页,也可以从4页空闲页链表中取出1个4页。同时当程序释放1页内存时,这页空闲页会返还给1页空闲页链表中,当程序释放4页内存时,如果释放的4页内存和内存条中4页连续内存相邻,则将合并为8页,放入8页空闲页链表中,否则放入4页空闲页链表中。
查看空闲页链表的方法 cat /proc/buddyinfo

DMA行中6表示ZONE_DMA中1页空闲有6*1页,此行中4表示ZONE_DMA中2页空闲有4*2页,此行中1表示ZONE_DMA中4页空闲有1*4页
Normal行中100表示ZONE_NORMAL中1页空闲有100*1页,此行中32表示ZONE_NORMAL中2页空闲有32*2页,此行中28表示ZONE_NORMAL中4页空闲有28*4页...
Buddy算法缺陷:内存的碎片化,内存条有100M的空闲内存,但找不到连续的2页内存;
DMA引擎没有iommu时,在做DMA时,往往需要大块的连续内存,因此内存的碎片化会影响DMA;
解决Buddy算法的内存碎片化造成DMA没法申请到大块的连续内存,有两个解决方法:
(1)reserved内存 (预留内存)
(2)CMA(连续内存分配器)
reserved内存在dts中配置,如下:
- reserved-memory {
- #address-cells = <2>;
- #size-cells = <2>;
- ranges;
- reserved: buffer@0 {
- compatible = "shared-dma-pool";
- reusable;
- reg = <0x0 0x70000000 0x0 0x1000000>;
- linux, cma-default;
- };
如果reserved-memory下节点的compatible=
reserved-memory内存有可能进入系统CMA, 是否做为CMA, 依赖以下几个条件:
(1) compatible 必须为shared-dma-pool
(2) 没有定义no-map属性
(3) 定义了resuable属性
4.CMA机制
如下图,CMA工作机制:CMA获取大块连续内存,这部分大块连续内存平时给应用程序和movable页使用,当DMA申请大块连续内存时,应用程序占有的CMA区域的内存和在CMA区域的movable页从CMA区域移走,空出CMA内存区域给DMA使用;DMA申请大块连续内存时不需要调用CMA API,CMA API集成在DMA的API(如dma_alloc_coherent)中,CMA区域在物理内存

===========================动态内存的申请和释放===============================
1.内存的slab分配
工程实际中往往需要几个或几十个字节的内存,并且这些内存会频繁的分配和释放,Buddy算法按页分配内存,使用Buddy算法分配几个或几十个字节的内存会造成内存空间和分配时间的浪费,同时造成内存碎片,因此使用slab算法分配内存,解决分配内存时间和内存碎片的问题。
在/proc/slabinfo文件中有对内核slab情况的记录,如下图:

从上图可以看到内核常规结构的小块内存的slab分配情况,如UDPv6/TCPv6等,其中
2.kmalloc/kfree, malloc/free等API和slab的关系

如上图,用户空间分配内存API(malloc/free)和slab无关,用户空间的内存分配调用libc的API malloc,malloc调用系统调用brk/mmap从Buddy算法的API分配到物理内存;用户空间分配内存后,内核不会立刻给用空空间对应大小的物理内存,只有在用空空间真正使用那部分分配的内存时,内核的page fault才给用户空间真正的物理内存,这是linux内存申请的lazy机制,即用户空间申请的内存空间只在真正使用的时候,内核才会给用户空间分配物理内存,物理内存没有使用分配的内存时,用户空间没有真正的物理内存;当释放用户空间的内存时,不会将内存立刻还给物理内存,而是将分配的内存继续缓存在用户空间,直到空闲内存达到某个阈值时,才将内存返还给物理内存,设置阈值的API为mallopt;
内核空间的内存分配API(kmalloc/kfree)通过slab分配内存,具体的,slab从Buddy算法分配到物理内存,如2页内存,然后kmalloc从分配的2页内存中获取一块的小内存,如sizeof(UDPv6)大小的内存;kmalloc分配内存会立刻获得对应大小的物理内存;当内核空间kfree内存时,内存返还给slab,但不会立刻返还给物理内存,直到通过slab分配到的内存,如2页内存,全部空闲时,再将2页内存返还给物理内存。
3.vmalloc/kmalloc/ioremap和内存空间的关系

内存空间包括:物理内存和寄存器空间
kmalloc 申请的物理内存位于low memory物理内存,申请内存时不用修改页表
vmalloc 申请整个物理内存,申请内存时需要修改页表
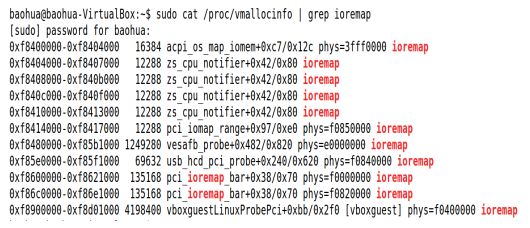
ioremap 寄存器空间映射到vmalloc映射区,调用ioremap时,修改页表建立vmalloc映射区的地址(虚拟地址)和寄存器空间间的对应关系,查看寄存器和vmalloc映射区对应关系存放在vmallocinfo 文件中,如下图:
4.oom(out of memory)
当物理内存不够时,linux 触发oom,将进程杀掉;linux依据oom打分因子oom score选择需要杀掉的进程;oom打分因子oom score取决于进程使用内存的大小,进程使用内存越大,oom score 越大,越会被杀掉;同时oom score 打分还会考虑进程的权限;打分因子oom score具体通过调用badness()函数进行打分;oom打分因子的调整方法有:
(1) /proc/pid/oom_score_adj 加减几分
(2) /proc/pid/oom_adj oom 打分的系数(-15~15),oom_adj越大,打分越大
===============================进程的内存====================================
进程的内存消耗 包括实、虚、共享
进程消耗的内存 指用户空间消耗的内存,不包括内核空间消耗的内存
1.进程的虚拟地址空间VMA
进程的VMA是一段一段的分布在0~3G地址空间,这些VMA以链表的形势保存在mm_struct的vm_area struct mmap域中,如下图:

如下图:进程的栈、内存映射段(libc.so等库的映射)、堆、、BSS段、数据段、代码段等分别对应一个VMA

查看进程的VMA的情况方式:
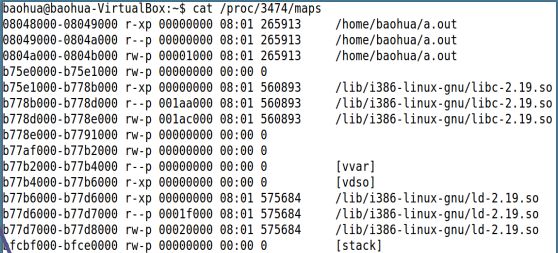
(1)在/proc/pid/maps中记录了进程的VMA情况,如下图,记录了每个VMA的起始地址、权限、大小等信息
(2)pmap 命令也可以查看VMA情况,如下图:
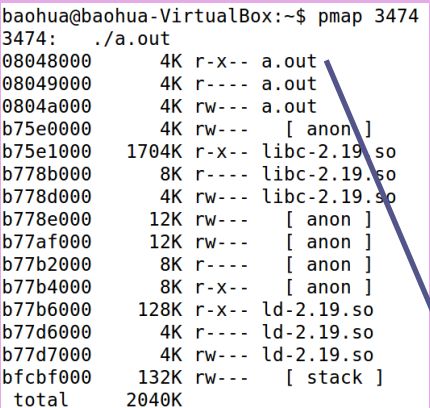
(3)在/proc/pid/smaps有详细的信息,如下图:

从上面三幅图看出,进程的VMA不连续,中间有空白区域
在VMA的区域不一定在物理内存中,如malloc一个100M的空间,则会多出一个100M的VMA,但进程没有100M的物理内存
2.page fault的几种可能性
当发生page fault时会在寄存器中记录在哪个地址发生page fault、发生page fault的原因,发生page fault时的权限;
page fault的几种可能性如下图:

1.当进程访问malloc区域或堆、栈的VMA时,会page fault,然后给进程分配物理内存;
2.当进程访问VMA的空白区域时,会segv;
3.当进程访问的VMA区域的权限不对,会segv;
4.当进程访问代码段并且有权限,会page fault,然后给进程分配物理内存;
也就是page fault分为三种情况:非法区域、合法区域权限不对、合法区域权限对,其中1和4情况是合法区域权限对,1情况称为minor的page fault,耗时少,4情况称为major的page fault,需要从硬盘中读取代码段,耗时多。
3.进程瓜分内存以及 vss/rss/pss/uss
进程按下图所示瓜分物理内存,图中有三个进程及三张页表,图中间部分为内存条,图中VMA有1044进程的堆、bash代码段、libc代码段,1045进程的堆、bash代码段、libc代码段,1054进程的堆、cat代码段、libc代码段,进程的VMA通过页表映射到内存条,在内存条中驻留了libc代码段、bash代码段、1044进程的堆、1045进程的堆、1054进程的堆以及cat代码段其中libc代码段被三个进共同程映射(共享内存),bash代码段被两个进程共同映射(共享内存),三个进程的堆在内存条中各有一份映射,cat代码段是进程1054独占。
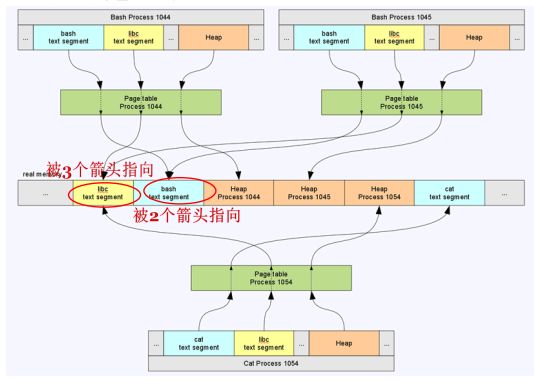
介绍四个概念:
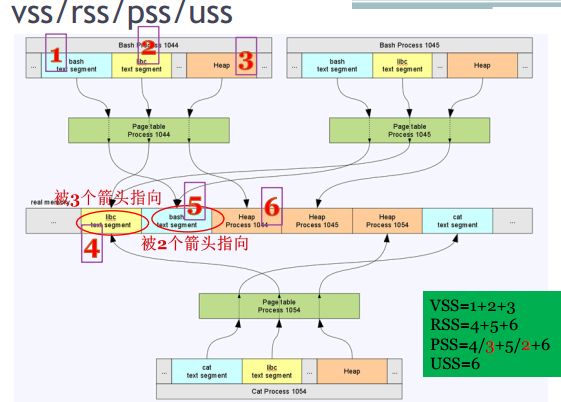
VSS- Virtual Set Size 虚拟地址空间,对应各个进程的VMA
RSS- Resident Set Size 驻留地址空间,对应上图中内存条上的libc代码段、bash代码段、堆、cat代码段PSS- Proportional Set Size 比例地址空间,对共享内存的描述,如上图中的libc代码段、bash代码段
USS - Unique Set Size 独占地址空间,对应上图的堆、cat代码段
VSS /RSS /PSS /USS 的大小如下图,具体到进程1044如下:
VSS = 1+2+3
RSS = 4+5+6
PSS = 4/3 + 5/2 + 6
USS = 6
使用工具smam可以查看进程的RSS /PSS /USS大小,如下图:

RSS /PSS /USS 大小可以用饼状图、柱状图呈现
假设一份可执行文件运行一次,即一份可执行文件对应一个进程,在smem中RSS为1000
那运行两次,即有一份可执行文件对应两个进程1和2,则在smem中RSS变成原来的一半即500
4.内存泄漏及检测工具valgrind/asan(addresssanitizer)
内存泄漏: 连续多点采样法,随时间越久,进程内存消耗越大,则存在内存泄漏,如下图

检测内存泄漏的工具有:valgrind/asan(addresssanitizer)
===============================内存与I/O交换================================
本节包括page cache、交换机制、回收机制
1. page cache
为加快对磁盘上映像和数据的访问,linux使用page cache缓存从磁盘上读取的映像和数据,这里page cache指内存充当磁盘的缓存常见的读取磁盘上文件的,page cache机制如下图,应用1和2第一次取磁盘上文件时,会读磁盘,并在内核中建立该文件的page cache,应用1和2后面再次取文件时,不会再读磁盘,仅从page cache中取文件,也就是说应用程序取文件是对内存取文件,不是去磁盘中文件,内存中文件和磁盘的交换机制为swap,由内核维护,不需要应用程序维护

page cache有两种形式,如下图:
(1)cached:以文件系统中的文件为背景的page cache
(2)buffers:以裸分区(如/dev/sdax)为背景的page cache,如mnt、dd命令时就是buffes
访问裸分区的情况有:文件系统本身访问裸分区和应用程序直接打开裸分区
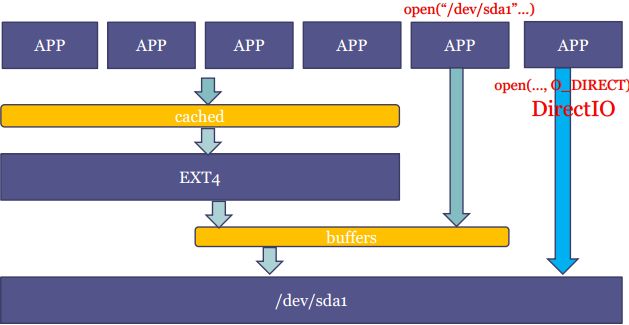
free命令可以查看page cache两种形式的情况,如下图,free中可以看出buffers、cached

上图中used5 = 1 - 3 -4;free6 = 2 + 3 + 4
在新的linux中free命令有变化,如下图,取消了buffers和cached的区别和-/+ buffers/cache行,增加available,available用于评估有多少内存给应用程序使用

2.mmap和read/write
应用程序取文件有两种方式mmap和read/write
mmap的本质如下图,应用程序将磁盘上文件mmap到VMA,应用程序对磁盘文件的操作貌似是直接操作磁盘上文件,本质上是操作物理内存上的page cache,代码段的本质是将elf从磁盘中mmap到VMA
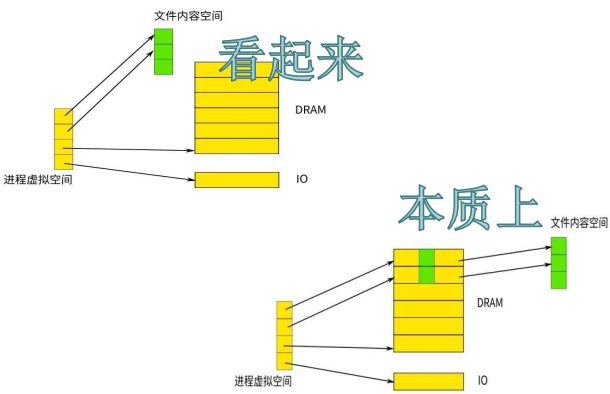
3.交换机制
用于page cache的内存页不会常驻内存,会被交换出去到磁盘中,当再次需要的时候再交换进内存,即交换机制
内存中页分为两类:文件背景的页File-backed和匿名页anonymous page(没有文件背景的页),有文件背景的内存的页可以和磁盘上的页进行交换,没有文件背景的内存的页为了实现交换机制,linux 伪造了文件背景,这个伪造的文件背景在磁盘中分一个区作为匿名页的文件背景,这个分区称为swap分区,也有在磁盘中建立swap file作为匿名页的文件背景,如下图:

交换机制在内核用kswapd实现
kswapd对有文件背景的页和匿名页做的内存和磁盘交换swap,当confige swap关掉,仅关掉匿名页的swap,有文件背景
的内存也仍然在swap,kswapd中用LRU算法选择需要交换的内存页
在windows中swap分区或swap文件称为虚拟内存,虚拟内存不是内存,是磁盘,虚拟内存也不是虚拟地址,虚拟地址是CPU方位内存
4.内存回收
内存回收指将内存页(包括有文件背景页和匿名页)交换出去到磁盘中,有两种方式:
(1)内核后台的kswapd
(2)直接回收direct reclaim
kswapd和direct reclaim何时使用如下图:
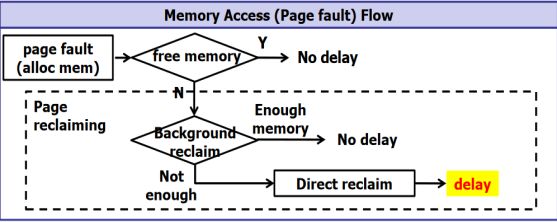
内存中有三个水位 min low high,当内存达到low水位时,kswapd开始回收内存,直到内存达到high水位时停止kswapd,如果kswapd回收速度小于内存消耗速度,内存水位下降到min水位,则direct reclaim开始回收内存,并会阻塞应用程序
内存回收选择回收文件背景内存页还是选择匿名页,通过swappiness进行配置,swappiness值大,回收匿名页多一点,swappiness值小,回收有文件背景的内存页多一点
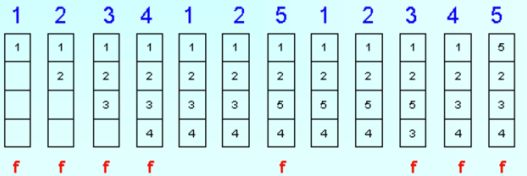
回收的算法使用LRU(最近最不活跃的页)算法,回收掉最近最不活跃页,如下图,在第7列中访问5页时,3页是最不活跃页,因此将3页抛掉,并将5页放到3页位置
zRAM Swap:嵌入式系统中flash速度慢、寿命小,如果kswapd频繁交换匿名页,会造成程序运行速度慢、加快flash损坏,因此在嵌入式系统中不使用磁盘的swap分区交互匿名页,而是在内存中划出一个区域(比如60M内存),模拟成磁盘分区,这个分区具有透明压缩功能,当匿名页交换进zRAM 时,linux自动压缩匿名页并存到zRAM 中再次访问交换进zRAM 的内存页时,发生page fault,linux自动解压之前压缩的匿名,并交换进内存中
===============================其他工程问题==================================
1.DMA和cache一致性
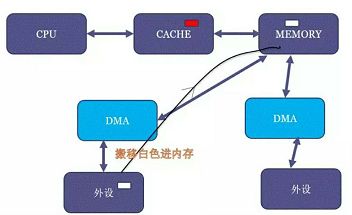
DMA一致性是指CPU中cache和内存中的内容一致性,具体如下面两幅图,内存中有一块红色区域,CPU读取这块红色区域,那这块红色区域进入cache中,然后DMA将外设的一块白色区域搬到内存的红色区域,这时cache和内存间就不一致;另一方面,CPU写内存时有write back和write through两种方式,cpu采用write through写内存时,cpu直接写到内存,采用write back时,先写到cache,cache硬件采用LRU算法再写到内存中,write through性能较差,CPU一般采用write back,所以cpu写内存时,只是写到cache,并没有立即写到内存,即CPU中cache和内存中的内容不一致;

解决一致性采用两类API:一致性DMA缓存区API dma_alloc_coherent和流式DMA API dma_map_sg/dma_map_single,使用dma_alloc_coherent时DMA内存由自己申请,如果soc没有硬件自动同步cache功能,申请时在在页表中做虚实映射,申请到ZONE_HIGH区域(CMA区域),映射在vmalloc映射区,并在页表中说明不带cache,申请到ZONE_NORMAL区域,则仅将页表改为不带cache,如果soc有硬件自动同步cache,dma_alloc_coherent申请的内存时,不需要修改页表中的cache项;
dma_alloc_coherent仅是一个前端,后端如下图,有alloc_pages/cma/iommu,dma_alloc_coherent可以拿连续的内存(包括DMA_ZONE区域的内存或CMA内存),页可以拿不连续的内存(取决于带不带iommu),页表可以带cache,也可以不带cache(取决于是否有硬件自动同步cache)

下图为iommu图,不带iommu一般从CMA拿内存,带iommu的可以拿非连续的物理内存,通过iommu映射给DMA为连续的内存

流式API dma_map_sg/dma_map_single适用于DMA内存不是自己分配,因此DMA的内存可能会不带cache一致性,那在做DMA时需要先调dma_map_sg或dma_map_single(取决于DMA引擎是否支持聚集散列操作),告诉linux做从外设到内存的DMA即cache的invalid,或从内存到外设的DMA即flush,DMA结束时调dma_unmap_sg或dma_unmap_single
2.内存的cgroup
在/sys/fs/cgroup/memory/ 中设置内存cgroup,放在cgroup中的进程具有相同的内存行为,如所有仅回收有文件背景的内存页,不回收匿名页
3.dirty页的写回
写回机制基于时间和空间,基于时间:脏页在内存中时间达到dirty_expire_centisecs就写回,内核中有写回线程,写回线程启动间隔为dirty_writeback_centisecs,基于空间:脏页在内存中比例达到dirty_background_ratio后台开始写回,如果脏页继续增加达到dirty_ratio(应用程序写内存的速度大于脏页回收到磁盘的速度),就需要阻塞应用程序的write,等待脏页写回
4.内存回收的水位设置
每个ZONE内存水位分为:min/low/high,在/proc/sys/vm/min_free_kbytes中设置min水位,low = 5/4min,high = 6/4min,当内存达到low水位时,kswapd开始回收内存,直到内存达到high水位时停止kswapd,如果kswapd回收速度小于内存消耗速度,内存水位下降到min水位,则direct reclaim开始回收内存,并会阻塞应用程序
5.swappiness
在/proc/sys/vm/swappiness中设置swappiness,swappiness越大,回收有文件背景的内存页多一点,swappiness越小,回收匿名页多一点;
设置swappiness=0时,只会回收有文件背景的页,仅在回收完有文件背景页的时候,内存水位依然低于high时,才回收匿名页内存;
6.调试工具getdelays
位置:Documentation/accounting/getdelays.c,用于分析等待CPU调度、等待IO,等待swap等所需要的时间
7.调试工具vmstat
vmstat可以展现给定时间间隔的服务器的状态值,包括Linux的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况,用于分析磁盘的压力在哪里,在swap,还是在load文件等