C语言和C++关键字总结——一篇就够了
C语言和C++关键字总结
- C语言和C 关键字总结
- 一、auto
* 1、C语言
* 2、C - 二、struct
- 三、static
* 1、程序的内存分配
* 2、局部静态变量
* 3、全局静态变量
* 4、静态函数
* 5、类的静态成员变量
* 6、类的静态成员函数
* 7、static const 成员 - 四、register
* 1、皇帝身边的小太监----寄存器
* 2、register修饰符暗示编译程序相应的变量将被频繁地使用
* 3、但是使用register修饰符有几点限制 - 五、const
* 1、const修饰普通类型的变量
* 2、const 修饰指针变量
* 3、const参数传递和函数返回值。
* 4、const修饰类成员函数 - 六、volatile
* 1、如何理解呢?
* 2、volatile将会用来修饰以下这些变量
* 3、当要求使用volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。 - 七、extern
* 1、基本解释
* 2、extern 变量
* 3 、单方面修改extern 函数原型
* 4、extern “C”
* 6、extern 和 static
* 7、extern 和const - 八、sizeof
* 1、与strlen()比较
* 2、指针与静态数组的sizeof操作
* 3、格式的写法
* 4、使用sizeof时string的注意事项
* 5、union 与struct的空间计算 - 九、new和delete
* 1、new 和 delete 到底是什么?
* 2、operator new 和 operator delete
* 3、new 和 delete 背后机制
* 4、如何申请和释放一个数组?
* 5、为什么 new/delete 、new []/delete[] 要配对使用? - 十、const_cast
- 十一、dynamic_cast
- 十二、reinterpret_cast
- 十三、static_cast
- 十四、explicit
- 十五、inline
* 1、引入inline关键字的原因
* 2、inline使用限制
* 3、inline仅是一个对编译器的建议
* 4、建议:inline函数的定义放在头文件中
* 5、类中的成员函数与inline
* 6、inline 是一种“用于实现的关键字”
* 7、慎用inline
* 8、总结 - 十六、operator
* 一、为什么使用操作符重载?
* 二、如何声明一个重载的操作符? - 十七、template
* C 模板
* 1、函数模板通式
* 2、类模板通式
* 3、模板的形参 - 十八、decltype
- 十九、throw、try、catch
- 二十、virtual
* 1、虚函数与运行多态
* 2、虚函数中默认参数
* 3、静态函数可以声明为虚函数吗?
* 4、构造函数可以为虚函数吗?
* 5、析构函数可以为虚函数吗?
* 6、虚函数可以为私有函数吗?
* 7、虚函数可以被内联吗?
* 7、纯虚函数与抽象类
- 一、auto
| 关键字 | 意义 | C/C++ |
|---|---|---|
| auto | 声明自动变量,缺省时编译器一般默认为auto(详细讲解见下方) | C/C++ |
| int | 声明整型变量 | C/C++ |
| double | 声明双精度变量 | C/C++ |
| long | 声明长整型变量 | C/C++ |
| char | 声明字符型变量 | C/C++ |
| float | 声明浮点型变量 | C/C++ |
| short | 声明短整型变量 | C/C++ |
| signed | 声明有符号类型变量 | C/C++ |
| unsigned | 声明无符号类型变量 | C/C++ |
| struct | 声明结构体变量(详细讲解见下方) | C/C++ |
| union | 声明联合数据类型 | C/C++ |
| enum | 声明枚举类型 | C/C++ |
| static | 声明静态变量(详细讲解见下方) | C/C++ |
| switch | 用于开关语句 | C/C++ |
| case | 开关语句分支 | C/C++ |
| default | 开关语句中的“其他”分支 | C/C++ |
| break | 跳出当前循环 | C/C++ |
| register | 声明寄存器变量(详细讲解见下方) | C/C++ |
| const | 声明只读变量(详细讲解见下方) | C/C++ |
| volatile | 说明变量在程序执行中可被隐含地改变(详细讲解见下方) | C/C++ |
| typedef | 用以给数据类型取别名(当然还有其他作用) | C/C++ |
| extern | 声明变量是在其他文件正声明(也可以看做是引用变量)(详细讲解见下方) | C/C++ |
| return | 子程序返回语句(可以带参数,也可不带参数) | C/C++ |
| void | 声明函数无返回值或无参数,声明空类型指针 | C/C++ |
| continue | 结束当前循环,开始下一轮循环 | C/C++ |
| do | 循环语句的循环体 | C/C++ |
| while | 循环语句的循环条件 | C/C++ |
| if | 条件语句 | C/C++ |
| else | 条件语句否定分支(与if 连用) | C/C++ |
| for | 一种循环语句(可意会不可言传) | C/C++ |
| goto | 无条件跳转语句 | C/C++ |
| sizeof | 计算对象所占内存空间大小(详细讲解见下方) | C/C++ |
| asm | asm (指令字符串):允许在 C++ 程序中嵌入汇编代码 | C++ |
| bool | C++ 中的基本数据结构,其值可选为 true(真)或者 false(假) | C++ |
| new | new(新建)用于新建一个对象(详细讲解见下方) | C++ |
| delete | delete(删除)释放程序动态申请的内存空间(详细讲解见下方) | C++ |
| const_cast | const、volatile类型转换(详细讲解见下方) | C++ |
| dynamic_cast | 动态转换(详细讲解见下方) | C++ |
| reinterpret_cast | 非相关类型转换(详细讲解见下方) | C++ |
| static_cast | 相关类型转换(详细讲解见下方) | C++ |
| export | 对模板类型,在定义这些模板类对象和模板函数时,使用标准 C++ 新增加的关键字 export(导出) | C++ |
| explicit | "禁止单参数构造函数"被用于自动型别转换,其中比较典型的例子是容器类型(详细讲解见下方) | C++ |
| friend | friend(友元)声明友元关系,友元可以访问与其有 friend 关系的类中的 private/protected 成员,提高了效率 | C++ |
| inline | inline(内联)函数的定义将在编译时在调用处展开,inline 函数一般由短小的语句组成,可以提高程序效率(详细讲解见下方) | C++ |
| mutable | mutable(易变的)只能用于类的非静态和非常量数据成员。与 const 相反 | C++ |
| namespace | namespace(命名空间)用于在逻辑上组织类,是一种比类大的结构 | C++ |
| class | class(类)是 C++ 面向对象设计的基础,使用 class 关键字声明一个类 | C++ |
| operator | operator(操作符)用于操作符重载(详细讲解见下方) | C++ |
| template | template(模板),C++ 中泛型机制的实现(详细讲解见下方) | C++ |
| decltype | 推断变量的类型(详细讲解见下方) | C++ |
| throw | throw(抛出)用于实现 C++ 的异常处理机制,可以"抛出"一个异常(详细讲解见下方) | C++ |
| try | try(尝试)用于实现 C++ 的异常处理机制。可以在 try 中调用可能抛出异常的函数,然后在 try 后面的 catch 中捕获并进行处理 | C++ |
| catch | catch 和 try 语句一起用于异常处理 | C++ |
| typeid | 指出指针或引用指向的对象的实际派生类型 | C++ |
| using | 表明使用 namespace | C++ |
| virtual | virtual(虚的),C++ 中用来实现多态机制(详细讲解见下方) | C++ |
| public | public(公有的),访问控制符,被标明为 public 的字段可以在任何类 | C++ |
| protected | protected(受保护的),访问控制符,被标明为 protected 的字段只能在本类以及其继承类和友元中访问 | C++ |
| private | private(私有的),访问控制符,被标明为 private 的字段只能在本类以及友元中访问 | C++ |
一、auto
1、C语言
在C语言中使用auto关键字声明一个变量为自动变量,是C语言中应用最广泛的一种类型,在函数内定义变量时,如果没有被声明为其他类型的变量都是自动变量,也就是说,省去类型说明符auto的都是自动变量。这里的其他类型指的是变量的存储类型即:静态类型变量(static )、寄存器类型变量(register)和外部类型变量(extern)。
在C语言中使用auto定义的变量可以不予初始化,但在C++中必须初始化。自动变量,在函数调用时分配存储空间,当完成调用是释放存储空间。 在C语言中,当省略数据类型,只使用auto修饰变量,在C语言中默认变量为int型。
void Test()
{
auto int x = 10; //定义自动变量x,auto可以省略
int y; //y和z都为自动变量,如果省略了auto 关键字则隐含表示为auto类型
double z;
}
2、C++
**C++**中的auto关键字是一个类型说明符,通过变量的初始值或者表达式中参与运算的数据类型来推断变量的类型。编程时通常需要把表达式值式赋给变量,这就要求在声明变量时清楚的知道表达式的类型,C++11新标准引入了auto 类型说明符,让编译器去分析表达式的类型。由于,需要编译器推断变量或表达式的类型,所以,auto定义的变量必须初始化。例如:
auto val = 5.2f; //编译器会根据初始化的值来推断val的数据类型为flaot,但要注意如果去掉f则编译器会认为val为double型变量
auto x = y + z; //x初始化为y和z相加的结果,由y和z的数据类型推断x的数据类型
auto num; //但如果在C++中出现这样的语句,会编译报错,提示“类型包含“auto符号”必须具有初始值设定项”
使用auto也能在一条语句中声明多个变量。因为一条语句声明时只能有一种基本数据类型,所以该语句中的所有变量初始基本数据类型必须一样,例如:
auto i = 0, *p = &i; //正确:i是整数、p是整形指针
auto sz = 0, pi = 3, 14; //错误:sz和pi的类型不一致
auto和 decltype 的作用有点相似,都可以推断某个表达式的具体类型,当我们希望从表达式的值推断出要定义的变量的类型,但不想用该表达式的值初始化变量时,可以使用 decltype ,作用是选择并返回操作数的数据类型,但并不计算表达式的值。如果 decltype 使用的表达式不是一个变量,则 decltype 返回表达式结果对用的类型,”如果我们仅仅是想根据初始值确定一个变量合适的数据类型,那么auto是最佳人选。而只有当我们需要推断某个表达式的数据类型,并将其作为一种新的数据类型重复使用(比如,定义多个相同类型变量)或者单独使用(比如,作为函数的返回值类型)时,我们才真正需要用到 decltype “。
在范围for语句中,经常会使用到auto关键字,正如文章开篇举得那个例子,范围for语句遍历给定序列中的每个元素并对序列中的每个值执行某种操作。其语法形式为:
/*
*declaration 部分定义一个变量,该变量用于访问序列中的基础元素,expression部分是一个对象,用于表示
*一个序列。每次迭代,declaration部分的变量会初始化为expression部分的下一个元素值,statment是对字
*符的操作语句
*/
for (declaration : expression)
{
statement
}
下面看一个例子,将上面介绍到的关键字和范围for语句梳理一下:
//编写一段程序,使用范围for语句将字符串内的所有字符用‘X’代替
#include
#include
using namespace std;
int main()
{
string str;
getline(cin, str); //从输入中读取一行赋值给str1
//auto 是一个类型说明符,通过变量的初始值来判断变量的类型
for (auto &c : str) //对于字符串str中的每一个c
{
//decltype 类型指示符,选择并返回操作数的数据类型,如果decltype使用
//的表达式不是一个变量,则decltype返回表达式结果对应的类型
for (decltype(str.size()) index = 0; index < str.size(); ++index)
{
str[index] = 'X';
}
}
cout << str << endl; //打印替换后的字符串
system("pause");
return 0;
}
简单分析:上面的代码完成的功能是,把字符串中的所有字符‘X’用代替。先从键盘读取一行字符串,然后使用范围for语句对其进行处理,在范围for语句中使用auto关键字推断变量c的数据类型,因为要改变字符串中的字符,所以将循环变量C定义为引用类型,然后使用for循环依次处理字符串str中的字符,将其修改为字符‘X’,在使用下标处理字符串中的字符是,我们需要知道字符串的长度,c++中的size()函数用于返回字符串的长度,即:字符串中字符的个数,类似于C语言中的strlen,字符串的下标从0开始,所以下标的取值大于等于0并且小于字符串的size()值,循环控制条件为:
index < str.size();
所以index为decltype(str.size())型的变量,这里使用decltype返回函数size()返回值类型,并且将其作为数据类型定义index作为字符串中字符的下标,(实际上size()返回的是一个size_t类型的值,个人认为,可以把 size_t 理解为unsigned int型),然后,在循环体内实现字符的替换,上面的代码中用到了本文中讲到的auto类型说明符,decltype类型指示符以及范围for语句,可以帮助我们简单的理解其简单应用。
二、struct
在C语言中,struct定义一个结构体,属于自定义类型,可包含不同类型的变量数据,同时采用内存对齐的方式。
struct Student{
char*name;//姓名
int age;//年龄
float height;//身高
};
struct Student stu;
注意:
- 不允许对结构体本身递归定义
- 结构体内可以包含别的结构体
- 定义结构体类型,只是说明了该类型的组成情况,并没有给它分配存储空间,就像系统不为int类型本身分配空间一样。只有当定义属于结构体类型的变量时,系统才会分配存储空间给该变量
- 结构体变量占用的内存空间是其成员所占内存之和,而且各成员在内存中按定义的顺序依次排列
问题:结合数据在内存的存储方式,当我们在栈上申请一块儿空间,作为数组或内置类型变量的存储空间,如何申请和开辟,按位怎么存放?堆上申请空间存放结构体变量呢?
首先,我们在栈上申请一块儿空间,栈的地址由低到高,每个字节8位,当我们存放int或者char类型的变量时,按字节对齐,小端模式下,int是32位,低地址存放数据的低位,高地址存放数据的高位,char是一个字节8位,直接存放,而数组是一个连续空间,先看数组元素类型,再存储。
在堆上开辟空间,无论是new还是malloc,底层都有malloc的实现,我们知道Windows下malloc底层是通过break指针实现内存的开辟,也就是说,内存已经被开好了,我们只需要去申请空间,而堆的地址由高地址到低地址,结构体到的存储按照内存对齐排列,所以按照结构体数据的顺序,高地址存放越前的数据,数据内部的存储按照大小端对齐,若结构体中有数组,数组的存储任然是低地址到高地址。
三、static
1、程序的内存分配
- 静态存储区,全局变量和静态变量的存储是在静态区,初始化的全局变量和静态变量在一块区域 .data,未初始化的全局变量和静态变量在相邻的另一块区域 .bss。程序结束后由系统释放。(相当于未初始化数据区和已初始化数据区)
- 栈区,由编译器自动分配释放,存放函数的参数值、局部变量等。
- 堆区,一般由程序员分配释放,即动态内存分配。
- 文字常量区,存放常量字符串,程序结束后由系统释放。
- 程序代码区,用于存放程序的二进制代码。
2、局部静态变量
在局部变量之前加上关键字 static,局部变量就变成一个局部静态变量。若不加static修饰,函数或者代码块中的变量在函数或者代码块执行完毕后就直接回收销毁了,每次执行都会重新分配内存,每次都会销毁;当static 作用于代码块内部的变量声明时,static关键字用于修改变量的存储类型。从自动变量变为静态变量,变量的属性和作用域不受影响。
在内存中的位置:静态存储区。
作用域:仍为局部作用域,当其所在的函数或者语句块结束的时候,作用域结束。然而局部静态变量离开作用域后,并没有被销毁,仍然驻留在内存中,只有该函数可以对其进行调用或者访问。也就是说,加 static 修饰,函数或者代码块中的变量在函数或者代码块执行第一次初始化分配内存后,就算函数或者代码块执行完毕,该变量也不会被回收销毁,直到程序结束 static 变量才会被回收。
3、全局静态变量
在全局变量前加上关键字 static,全局变量就变成了一个全局静态变量。
在内存中的位置:静态存储区。
初始化:未经初始化的全局静态变量被自动初始化为0。
作用域:全局静态变量在其所声明的文件之外是不可见的,准确的说是从定义处到文件末尾。
链接属性:当 static 作用于函数定义时,或者用于代码块之外的变量声明时,static关键字用于修改标识符的链接属性。外部链接属性变为内部链接属性,标识符的存储类型和作用域不受影响。也就是说变量或者函数只能在当前源文件中访问,不能在其他源文件中访问。
4、静态函数
在函数返回类型前加关键字 static,函数就被定义为静态函数,静态函数只在其所声明的文件中可见,不可被其他文件所使用。
链接属性:当 static 作用于函数定义时,或者用于代码块之外的变量声明时,static关键字用于修改标识符的链接属性。外部链接属性变为内部链接属性,标识符的存储类型和作用域不受影响。也就是说变量或者函数只能在当前源文件中访问,不能在其他源文件中访问。
5、类的静态成员变量
C++中,静态成员属于整个类而不是某个对象,静态成员变量只存储一份为所有类对象所公共。相比于全局变量,类的静态成员变量实现了多个对象之间的数据共享而不破坏隐藏的原则。类的静态成员,属于类,也属于对象,但终归属于类。
类的静态成员变量必须在类内定义,类外初始化。
6、类的静态成员函数
类的静态函数,不能访问类的私有成员,只能访问类的静态成员,用于管理静态成员。静态成员函数属于类,也属于对象,但终归属于类。
静态成员函数的意义,不在于信息共享和数据沟通,而在于管理静态数据成员,完成对静态数据成员的封装。
7、static const 成员
一个类的成员,既要实现共享,又要实现不可改变,则使用 static const 修饰,需要类内就地初始化。
问题:普通全局变量与 static 全局变量的区别?static 局部变量与普通局部变量的区别?static 函数与普通函数的区别?
- 两者都是静态存储方式,区别在于普通全局变量的作用域是整个原程序,静态全局变量的作用域是定义该变量的源文件。将全局变量改为静态全局变量,改变了其作用域,限制了其使用范围。
- 普通局部变量存储于栈空间,而静态局部变量=则存储于静态存储区。将局部变量改为静态局部变量后,改变了其存储方式,即改变了其生存期。
- 与普通函数作用域不同,静态函数仅在本文件。只在当前源文件中使用的函数应当被声明为内部函数 static,在当前源文件中声明和定义。对于可在当前源文件之外使用的函数,应当在一个头文件中声明,要使用这些函数的源文件包含该头文件即可。
特点: static局部变量的”记忆性”与生存期的”全局性”
所谓”记忆性”是指在两次函数调用时, 在第二次调用进入时, 能保持第一次调用退出时的值。
注意事项:
- “记忆性”, 程序运行很重要的一点就是可重复性, 而static变量的”记忆性”破坏了这种可重复性, 造成不同时刻至运行的结果可能不同.
- “生存期”全局性和唯一性. 普通的局部变量的存储空间分配在stack上, 因此每次调用函数时, 分配的空间都可能不一样, 而static具有全局唯一性的特点, 每次调用时, 都指向同一块内存, 这就造成一个很重要的问题——不可重入性
四、register
register:这个关键字请求编译器尽可能的将变量存在CPU内部寄存器中,而不是通过内存寻址访问,以提高效率。注意是尽可能,不是绝对。
因为,如果定义了很多register变量,可能会超过CPU的寄存器个数,超过容量。所以只是可能。
1、皇帝身边的小太监----寄存器
不知道什么是寄存器?那见过太监没有?没有?其实我也没有。没见过不要紧,见过就麻烦大了。_,大家都看过古装戏,那些皇帝们要阅读奏章的时候,大臣总是先将奏章交给皇帝旁边的小太监,小太监呢再交给皇帝同志处理。这个小太监只是个中转站,并无别的功能。
那我们再联想到我们的CPU。CPU 就是我们的皇帝同志,大臣就相当于我们的内存,数据从他这拿出来。那小太监就是我们的寄存器了(这里先不考虑CPU 的高速缓存区)。数据从内存里拿出来先放到寄存器,然后CPU 再从寄存器里读取数据来处理,处理完后同样把数据通过寄存器存放到内存里,CPU 不直接和内存打交道。这里要说明的一点是:小太监是主动的从大臣手里接过奏章,然后主动的交给皇帝同志,但寄存器没这么自觉,它从不主动干什么事。一个皇帝可能有好些小太监,那么一个CPU 也可以有很多寄存器,不同型号的CPU 拥有寄存器的数量不一样。
为啥要这么麻烦啊?就是因为速度。寄存器其实就是一块一块小的存储空间,只不过其存取速度要比内存快得多。进水楼台先得月,它离CPU 很近,CPU 一伸手就拿到数据了,比在那么大的一块内存里去寻找某个地址上的数据是不是快多了?那有人问既然它速度那么快,那我们的内存硬盘都改成寄存器得了呗。我要说的是:你真有钱!
2、register修饰符暗示编译程序相应的变量将被频繁地使用
如果可能的话,应将变量保存在CPU的寄存器中,以加快其存储速度。
3、但是使用register修饰符有几点限制
-
register变量必须是能被CPU所接受的类型。
这通常意味着register变量必须是一个单个的值,并且长度应该小于或者等于整型的长度。不过,有些机器的寄存器也能存放浮点数。
-
因为register变量可能不存放在内存中,所以不能用“&”来获取register变量的地址。“&”是用于内存地址的获取。
-
只有局部自动变量和形式参数可以作为寄存器变量,其它(如全局变量)不行。
在调用一个函数时占用一些寄存器以存放寄存器变量的值,函数调用结束后释放寄存器。此后,在调用另外一个函数时又可以利用这些寄存器来存放该函数的寄存器变量。
-
**局部静态变量不能定义为寄存器变量。**不能写成:register static int a, b, c;
-
由于寄存器的数量有限(不同的cpu寄存器数目不一),不能定义任意多个寄存器变量,而且某些寄存器只能接受特定类型的数据(如指针和浮点数),因此真正起作用的register修饰符的数目和类型都依赖于运行程序的机器,而任何多余的register修饰符都将被编译程序所忽略。
注意
早期的C编译程序不会把变量保存在寄存器中,除非你命令它这样做,这时register修饰符是C语言的一种很有价值的补充。register关键字请求让编译器将变量a直接放入寄存器里面,以提高读取速度,在C语言中register关键字修饰的变量不可以被取地址,但是c++中进行了优化。然而,随着编译程序设计技术的进步,在决定哪些变量应该被存到寄存器中时,现在的C编译环境能比程序员做出更好的决定。实际上,许多编译程序都会忽略register修饰符,因为尽管它完全合法,但它仅仅是暗示而不是命令。在早期c语言编译器不会对代码进行优化,因此使用register关键字修饰变量是很好的补充,大大提高的速度。
c++中依然支持register关键字,但是c++编译器也有自己的优化方式,即某些变量不用register关键字进行修饰,编译器也会将多次连续使用的变量优化放入寄存器中,例如入for循环的循环变量i(频繁使用)。
c++中也可以对register修饰的变量取地址,不过c++编译器发现程序中需要取register关键字修饰的变量的地址时,register关键字的声明将变得无效。
五、const
const 是constant的缩写,本意是不变的,不易改变的意思。
const 在C++中是用来修饰内置类型变量,自定义对象,成员函数,返回值,函数参数。
1、const修饰普通类型的变量
如下:
const int a = 7;
int b = a; //it's right
a = 8; // it's wrong,
a被定义为一个常量,并且可以将a赋值给b,但是不能给a再次赋值。对一个常量赋值是违法的事情,因为a被编译器认为是一个常量,其值不允许修改。
接着看如下的操作:
#include
using namespace std;
int main(void)
{
const int a = 7;
int *p = (int*)&a;
*p = 8;
cout< 对于 const 修饰的变量a,我们取变量的地址并转换赋值给指向int的指针,然后利用*p = 8; 重新对变量a地址内的值赋值,然后输出查看a的值。
从调试窗口看到a的值被改变为8,但是输出的结果仍然是7。从结果中看到,编译器认为a的值为一开始定义的7,所以对const a的操作就会产生上面的情况。所以千万不要轻易对const变量设法赋值,这会产生意想不到的行为。
如果不想让编译器察觉到上面到对const的操作,我们可以在const前面加上volatile关键字。volatile关键字跟const对应相反,是易变的,容易改变的意思。防止编译器优化,保证内存可见性,编译器也就不会改变对a变量的操作。
#include
using namespace std;
int main(void)
{
volatile const int a = 7;
int *p = (int*)&a;
*p = 8;
cout< 输出结果如我们期望的是8。
2、const 修饰指针变量
const 修饰指针变量有以下三种情况:
-
const 修饰指针指向的内容,则内容为不可变量。
-
const 修饰指针,则指针为不可变量。
-
const 修饰指针和指针指向的内容,则指针和指针指向的内容都为不可变量。
A:对于修饰指针指向的内容
const int *p = 8; //则指针指向的内容8不可改变。
简称**左定值**,因为**const位于\*号的左边**。
B:对于修饰指针
int a = 8;
int* const p = &a;
*p = 9; //it’s right
int b = 7;
p = &b; //it’s wrong
//对于const指针p其指向的内存地址不能够被改变,但其内容可以改变。
简称右定向。因为const位于*号的右边。
C:对于修饰指针和指针指向的内容,则是A和B的合并
int a = 8;
const int * const p = &a;
//这时,const p的指向的内容和指向的内存地址都已固定,不可改变。
对于A,B,C三种情况,根据const位于*号的位置不同,我总结三句话便于记忆的话,
“左定值,右定向,const修饰不变量”。
3、const参数传递和函数返回值。
对于const修饰函数参数可以分为三种情况:
- A:值传递的const修饰传递,一般这种情况不需要const修饰,因为函数会自动产生临时变量复制实参值。
#include
using namespace std;
void Cpf(const int a)
{
cout< - B:当const参数为指针时,可以防止指针被意外篡改。
#include
using namespace std;
void Cpf(int *const a)
{
cout<<*a<<" ";
*a = 9;
}
int main(void)
{
int a = 8;
Cpf(&a);
cout< - C:自定义类型的参数传递,需要临时对象复制参数,对于临时对象的构造,需要调用构造函数,比较浪费时间,因此我们采取const外加引用传递的方法。并且对于一般的int ,double等内置类型,我们不采用引用的传递方式。
#include
using namespace std;
class Test
{
public:
Test(){}
Test(int _m):_cm(_m){}
int get_cm()const
{
return _cm;
}
private:
int _cm;
};
void Cmf(const Test& _tt)
{
cout<<_tt.get_cm();
}
int main(void)
{
Test t(8);
Cmf(t);
system("pause");
return 0;
}
//结果输出 8
对于const修饰函数的返回值
Const修饰返回值分三种情况:
- A:const修饰内置类型的返回值,修饰与不修饰返回值作用一样。
#include
using namespace std;
const int Cmf()
{
return 1;
}
int Cpf()
{
return 0;
}
int main(void)
{
int _m = Cmf();
int _n = Cpf();
cout<<_m<<" "<<_n;
system("pause");
return 0;
}
-
B:const 修饰自定义类型的作为返回值,此时返回的值不能作为左值使用,既不能被赋值,也不能被修改。
-
C: const 修饰返回的指针或者引用,是否返回一个指向const的指针,取决于我们想让用户干什么。
4、const修饰类成员函数
const 修饰类成员函数,其目的是防止成员函数修改被调用对象的值,如果我们不想修改一个调用对象的值,所有的成员函数都应当声明为const成员函数。注意:const关键字不能与static关键字同时使用,因为static关键字修饰静态成员函数,静态成员函数不含有this指针,即不能实例化,const成员函数必须具体到某一实例。
下面的get_cm()const;函数用到了const成员函数
#include
using namespace std;
class Test
{
public:
Test(){}
Test(int _m):_cm(_m){}
int get_cm()const
{
return _cm;
}
private:
int _cm;
};
void Cmf(const Test& _tt)
{
cout<<_tt.get_cm();//相当于传入的参数不希望被修改
}
int main(void)
{ Test t(8);
Cmf(t);
system("pause");
return 0;
}
如果get_cm()去掉const修饰,则Cmf传递的const _tt即使没有改变对象的值,编译器也认为函数会改变对象的值,所以我们尽量按照要求将所有的不需要改变对象内容的函数都作为const成员函数。
如果有个成员函数想修改对象中的某一个成员怎么办?这时我们可以使用mutable关键字修饰这个成员,mutable的意思也是易变的,容易改变的意思,被mutable关键字修饰的成员可以处于不断变化中,如下面的例子。
#include
using namespace std;
class Test
{
public:
Test(int _m,int _t):_cm(_m),_ct(_t){}
void Kf()const
{
++_cm; //it's wrong
++_ct; //it's right
}
private:
int _cm;
mutable int _ct;//表示修饰易变的变量
};
int main(void)
{
Test t(8,7);
return 0;
}
这里我们在**Kf()const**中通过**++_ct;**修改**_ct**的值,但是通过**++_cm**修改**_cm**则会报错。因为**++_cm**没有用**mutable修饰**。
六、volatile
1、如何理解呢?
volatile可理解为防止编译器优化,保持内存可见性;即确保本条指令不会因编译器的优化而省略,且要求每次直接读值。
相当于假设我程序中有一个变量被register修饰,建议编译器优化,则该变量将存储于寄存器中,程序执行效率更快;
这时若加上volatile关键字修饰变量,则编译器将不会优化,直接从内存取值。
精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。
例如以下代码:
#include
using namespace std;
int main()
{
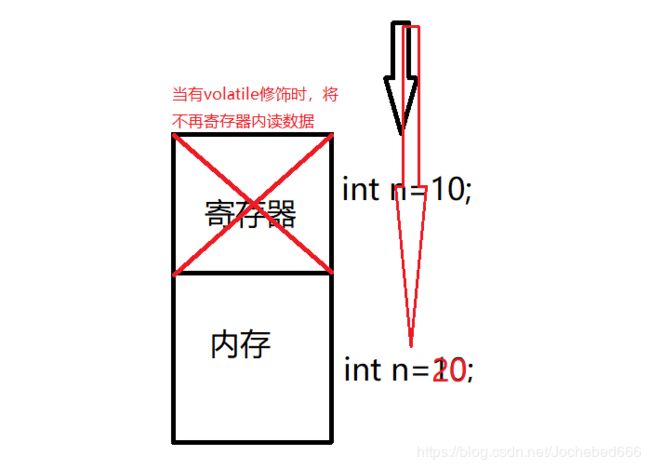
const int n = 10;
int p = (int)&n;
*p = 20;
cout< 输出结果为:

这个怎么解释呢?
-
在编译期间,编译器可能对代码进行优化
-
当编译器看到此处的n被const修饰,从语义上来讲,n是不期望被修改的
-
所以优化的时候把n的值存放到寄存器中,以提高访问的效率(当变量是“易变的”,编译器一般都不会考虑将变量放入寄存器中,而是内存,而这里的n被看做“不易被改变的”,随编译器考虑将其放入寄存器中进行优化)
-
只要以后使用n的地方都去寄存器中取,即使n在内存中的值发生变化,寄存器也不受影响,所以输出的n的值为10
加上volatile后:
#include
using namespace std;
int main()
{
volatile const int n = 10;
int *p = (int*)&n;
*p = 20;
cout< 运行结果为:

2、volatile将会用来修饰以下这些变量
-
并行设备的硬件寄存器(如:状态寄存器)
(一个变量可被const和volatile同时修饰,例如一个只读的状态寄存器)
-
一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
(一个指针可被volatile修饰,例如当一个中断服务子程序修改一个指向一个buffer的指针时)
-
多线程应用中被几个任务共享的变量
3、当要求使用volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。
例如:
volatile int i=10;
int a=i;
//...
//其他代码,并未明确告诉编译器,对i进行过操作
int b=i;
volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i 的地址中读取,因而编译器生成的汇编代码会重新从 i 的地址读取数据放在b中。而优化做法是,由于编译器发现两次从 i 读数据的代码之间的代码没有对 i 进行过操作,它会自动把上次读的数据放在b中。而不是重新从 i 里面读。这样一来,如果 i 是一个寄存器变量或者表示一个端口数据就容易出错,所以说volatile可以保证对特殊地址的稳定访问。
七、extern
1、基本解释
extern可以置于变量或者函数前,以表示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。此外extern也可用来进行链接指定。
也就是说extern有两个作用,第一,当它与"C"一起连用时,如: *extern “C” void fun(int a, int b);则告诉编译器在编译fun这个函数名时按着C的规则去翻译相应的函数名而不是C++的,C++的规则在翻译这个函数名时会把fun这个名字变得面目全非,可能是fun@aBc_int_int#%$*也可能是别的,这要看编译器的"脾气"了(不同的编译器采用的方法不一样),为什么这么做呢,因为C++支持函数的重载啊,在这里不去过多的论述这个问题,如果你有兴趣可以去网上搜索,相信你可以得到满意的解释!
第二,当extern不与"C"在一起修饰变量或函数时,如在头文件中: extern int g_Int; 它的作用就是声明函数或全局变量的作用范围的关键字,其声明的函数和变量可以在本模块活其他模块中使用,记住它是一个声明不是定义!也就是说B模块(编译单元)要是引用模块(编译单元)A中定义的全局变量或函数时,它只要包含A模块的头文件即可,在编译阶段,模块B虽然找不到该函数或变量,但它不会报错,它会在连接时从模块A生成的目标代码中找到此函数。
2、extern 变量
在一个源文件里定义了一个数组:char a[6];在另外一个文件里用下列语句进行了声明:extern char *a;请问,这样可以吗?
答案与分析:
-
不可以,程序运行时会告诉你非法访问。原因在于,指向类型 T 的指针并不等价于类型 T 的数组。extern char *a声明的是一个指针变量而不是字符数组,因此与实际的定义不同,从而造成运行时非法访问。应该将声明改为extern char a[ ]。
-
例子分析如下,如果a[] = “abcd”,则外部变量a=0x61626364 (abcd的ASCII码值),*a显然没有意义,显然a指向的空间(0x61626364)没有意义,易出现非法内存访问。
-
这提示我们,在使用extern时候要严格对应声明时的格式,在实际编程中,这样的错误屡见不鲜。
-
extern用在变量声明中常常有这样一个作用,你在
*.c文件中声明了一个全局的变量,这个全局的变量如果要被引用,就放在*.h中并用extern来声明。
3 、单方面修改extern 函数原型
当函数提供方单方面修改函数原型时,如果使用方不知情继续沿用原来的extern申明,这样编译时编译器不会报错。但是在运行过程中,因为少了或者多了输入参数,往往会照成系统错误,这种情况应该如何解决?
答案与分析:
目前业界针对这种情况的处理没有一个很完美的方案,通常的做法是提供方在自己的xxx_pub.h中提供对外部接口的声明,然后调用方include该头文件,从而省去extern这一步,以避免这种错误。宝剑有双锋,对extern的应用,不同的场合应该选择不同的做法。
4、extern “C”
在C++环境下使用C函数的时候,常常会出现编译器无法找到obj模块中的C函数定义,从而导致链接失败的情况,应该如何解决这种情况呢?
答案与分析:
C++语言在编译的时候为了解决函数的多态问题,会将函数名和参数联合起来生成一个中间的函数名称,而C语言则不会,因此会造成链接时找不到对应函数的情况,此时C函数就需要用extern “C”进行链接指定,这告诉编译器,请保持我的名称,不要给我生成用于链接的中间函数名。
下面是一个标准的写法:
//在.h文件的头上
#ifdef __cplusplus
#if __cplusplus
extern "C"{
#endif
#endif /* __cplusplus */
…
…
//.h文件结束的地方
#ifdef __cplusplus
#if __cplusplus
}
#endif
#endif /* __cplusplus */
####5、extern 函数声明
常常见extern放在函数的前面成为函数声明的一部分,那么,C语言的关键字extern在函数的声明中起什么作用?
答案与分析:
如果函数的声明中带有关键字extern,仅仅是暗示这个函数可能在别的源文件里定义,没有其它作用。即下述两个函数声明没有明显的区别:
extern int f();
int f();
当然,这样的用处还是有的,就是在程序中取代 #include "*.h"来声明函数,在一些复杂的项目中,我比较习惯在所有的函数声明前添加extern修饰。关于这样做的原因和利弊可见下面的这个例子:用extern修饰的全局变量
- 在test1.h中有下列声明:
#ifndef TEST1H
#define TEST1H
extern char g_str[]; // 声明全局变量g_str
void fun1();
#endif
- 在test1.cpp中
#include "test1.h"
char g_str[] = "123456"; // 定义全局变量g_str
void fun1() { cout << g_str << endl; }
- 以上是test1模块, 它的编译和连接都可以通过,如果我们还有test2模块也想使用g_str,只需要在原文件中引用就可以了
#include "test1.h"
void fun2()
{
cout << g_str << endl;
}
以上test1和test2可以同时编译连接通过,如果你感兴趣的话可以用 ultraEdit打开test1.obj,你可以在里面找到"123456"这个字符串,但是你却不能在 test2.obj里面找到,这是因为**g_str是整个工程的全局变量,**在内存中只存在一份,test2.obj这个编译单元不需要再有一份了,不然会在连接时报告重复定义这个错误!
- 有些人喜欢把全局变量的声明和定义放在一起,这样可以防止忘记了定义,如把上面test1.h改为
extern char g_str[] = "123456"; // 这个时候相当于没有extern
然后把 test1.cpp中的g_str的定义去掉,这个时候再编译连接test1和test2两个模块时,会报连接错误,这是因为你把全局变量g_str的定义放在了头文件之后,test1.cpp这个模块包含了 test1.h所以定义了一次g_str,而test2.cpp也包含了 test1.h所以再一次定义了g_str,这个时候连接器在连接test1和test2时发现两个g_str。如果你非要把g_str的定义放在 test1.h中的话,那么就把test2的代码中 #include "test1.h"去掉 换成:
extern char g_str[];
void fun2() { cout << g_str << endl; }
这个时候编译器就知道g_str是引自于外部的一个编译模块了,不会在本模块中再重复定义一个出来,但是我想说这样做非常糟糕,因为你由于无法在test2.cpp中使用 #include "test1.h",那么 test1.h中声明的其他函数你也无法使用了,除非也用都用extern修饰,这样的话你光声明的函数就要一大串,而且头文件的作用就是要给外部提供接口使用的,所以请记住,只在头文件中做声明,真理总是这么简单。
6、extern 和 static
-
extern 表明该变量在别的地方已经定义过了,在这里要使用那个变量.
-
static 表示静态的变量,分配内存的时候, 存储在静态区,不存储在栈上面.
static 作用范围是内部连接的关系, 和extern有点相反.它和对象本身是分开存储的,extern也是分开存储的,但是extern可以被其他的对象用extern 引用,而static 不可以,只允许对象本身用它. 具体差别首先,static与extern是一对“水火不容”的家伙,也就是说extern和static不能同时修饰一个变量;其次,static修饰的全局变量声明与定义同时进行,也就是说当你在头文件中使用static声明了全局变量后,它也同时被定义了;最后,static修饰全局变量的作用域只能是本身的编译单元,也就是说它的“全局”只对本编译单元有效,其他编译单元则看不到它,如:
(1) test1.h:#ifndef TEST1H #define TEST1H static char g_str[] = "123456"; void fun1(); #endif (2) test1.cpp:
#include "test1.h" void fun1() { cout << g_str << endl; } (3) test2.cpp
#include "test1.h" void fun2() { cout << g_str << endl; } 以上两个编译单元可以连接成功, 当你打开test1.obj时,你可以在它里面找到字符串"123456",同时你也可以在test2.obj中找到它们,它们之所以可以连接成功而没有报重复定义的错误是因为虽然它们有相同的内容,但是存储的物理地址并不一样,就像是两个不同变量赋了相同的值一样,而这两个变量分别作用于它们各自的编译单元。 也许你比较较真,自己偷偷的跟踪调试上面的代码,结果你发现两个编译单元(test1,test2)的g_str的内存地址相同,于是你下结论static修饰的变量也可以作用于其他模块,但是我要告诉你,那是你的编译器在欺骗你,大多数编译器都对代码都有优化功能,以达到生成的目标程序更节省内存,执行效率更高,当编译器在连接各个编译单元的时候,它会把相同内容的内存只拷贝一份,比如上面的"123456", 位于两个编译单元中的变量都是同样的内容,那么在连接的时候它在内存中就只会存在一份了,如果你把上面的代码改成下面的样子,你马上就可以拆穿编译器的谎言:
(1) test1.cpp:#include "test1.h" void fun1() { g_str[0] = ''a''; cout << g_str << endl; }(2) test2.cpp
#include "test1.h" void fun2() { cout << g_str << endl; } (3)
void main(){ fun1(); // a23456 fun2(); // 123456 } 这个时候你在跟踪代码时,就会发现两个编译单元中的g_str地址并不相同,因为你在一处修改了它,所以编译器被强行的恢复内存的原貌,在内存中存在了两份拷贝给两个模块中的变量使用。正是因为static有以上的特性,所以一般定义static全局变量时,都把它放在原文件中而不是头文件,这样就不会给其他模块造成不必要的信息污染,同样记住这个原则吧!
7、extern 和const
C++中const修饰的全局常量据有跟static相同的特性,即它们只能作用于本编译模块中,但是const可以与extern连用来声明该常量可以作用于其他编译模块中, 如*extern const char g_str[];*然后在原文件中别忘了定义: const char g_str[] = “123456”;
所以当const单独使用时它就与static相同,而当与extern一起合作的时候,它的特性就跟extern的一样了!所以对const我没有什么可以过多的描述,我只是想提醒你,const char g_str = “123456”* 与 *const char g_str[] =“123465”*是不同的, 前面那个const 修饰的是char *而不是g_str,它的g_str并不是常量,它被看做是一个定义了的全局变量(可以被其他编译单元使用), 所以如果你像让char* g_str遵守const的全局常量的规则,最好这么定义const char* const g_str="123456"。
八、sizeof
可参考:我的博客-sizeof总结 以及 有趣的sizeof和strlen
- 首先应该明确sizeof是一个C语言关键字而不是一个函数,用于计算数据空间的字节数,其计算发生在编译时刻,sizeof的值在编译时就已确定,括号中的表达式是不会执行的
- 在C++中,对于一个类或结构体,即使为空,编译器仍给其一个空间,大小为1个字节
- 类中static成员变量属于类域,不算入对象中
- 若类中有virtual函数,类的对象中包含了一个指向虚函数表的指针
1、与strlen()比较
strlen()计算字符数组的字符数,以"\0"为结束判断,不计算为’\0’的数组元素。
而sizeof计算数据(包括数组、变量、类型、结构体等)所占内存空间,用字节数表示。
2、指针与静态数组的sizeof操作
指针均可看为变量类型的一种。所有指针变量的sizeof 操作结果均为4。
注意:
int *p;
sizeof(p)=4;
但sizeof(*p)相当于sizeof(int);
对于静态数组,sizeof可直接计算数组大小;
例:
int a[10];
char b[]="hello";
//sizeof(a)等于4*10=40;
//sizeof(b)等于6;
注意:
数组做型参时,数组名称当作指针使用!!
void fun(char p[])
{
//sizeof(p)等于4
}
经典问题:
double* (*a)[3][6];
cout<问题解析:a是一个很奇怪的定义,他表示一个指向
double*[3][6]类型数组的指针。既然是指针,所以sizeof(a)就是4
既然a是执行 double*[3][6]类型的指针,*a就表示一个double*[3][6]的多维数组类型,因此sizeof(*a)=3*6*sizeof(double*)=72 。同样的,**a表示一个double*[6]类型的数组,所以sizeof(**a)=6*sizeof(double*)=24。***a就表示其中的一个元素,也就是double*了,所以sizeof(***a)=4。至于a,就是一个double了,所以sizeof(a)=sizeof(double)=8。
3、格式的写法
sizeof操作符,对变量或对象可以不加括号,但若是类型,须加括号。
4、使用sizeof时string的注意事项
string s="hello";
sizeof(s)等于string类的大小,sizeof(s.c_str())得到的是与字符串长度。
5、union 与struct的空间计算
总体上遵循两个原则:
- 整体空间是 占用空间最大的成员(的类型)所占字节数的整倍数
- 数据对齐原则----内存按结构成员的先后顺序排列,当排到该成员变量时,其前面已摆放的空间大小必须是该成员类型大小的整倍数,如果不够则补齐,以此向后类推……
注意:
数组按照单个变量一个一个的摆放,而不是看成整体。如果成员中有自定义的类、结构体,也要注意数组问题。
例:
因为对齐问题使结构体的sizeof变得比较复杂,看下面的例子:(默认对齐方式下)
struct s1
{
char a;
double b;
int c;
char d;
};
struct s2
{
char a;
char b;
int c;
double d;
};
cout< 同样是两个char类型,一个int类型,一个double类型,但是因为对齐问题,导致他们的大小不同。计算结构体大小可以采用元素摆放法,我举例子说明一下:首先,CPU判断结构体的对界,根据上一节的结论,s1和s2的对界都取最大的元素类型,也就是double类型的对界8。然后开始摆放每个元素。
对于s1,首先把a放到8的对界,假定是0,此时下一个空闲的地址是1,但是下一个元素d是double类型,要放到8的对界上,离1最接近的地址是8了,所以d被放在了8,此时下一个空闲地址变成了16,下一个元素c的对界是4,16可以满足,所以c放在了16,此时下一个空闲地址变成了20,下一个元素d需要对界1,也正好落在对界上,所以d放在了20,结构体在地址21处结束。由于s1的大小需要是8的倍数,所以21-23的空间被保留,s1的大小变成了24。
对于s2,首先把a放到8的对界,假定是0,此时下一个空闲地址是1,下一个元素的对界也是1,所以b摆放在1,下一个空闲地址变成了2;下一个元素c的对界是4,所以取离2最近的地址4摆放c,下一个空闲地址变成了8,下一个元素d的对界是8,所以d摆放在8,所有元素摆放完毕,结构体在15处结束,占用总空间为16,正好是8的倍数。
这里有个陷阱,对于结构体中的结构体成员,不要认为它的对齐方式就是他的大小,看下面的例子:
struct s1
{
char a[8];
};
struct s2
{
double d;
};
struct s3
{
s1 s;
char a;
};
struct s4
{
s2 s;
char a;
};
cout< s1和s2大小虽然都是8,但是s1的对齐方式是1,s2是8(double),所以在s3和s4中才有这样的差异。
所以,在自己定义结构体的时候,如果空间紧张的话,最好考虑对齐因素来排列结构体里的元素。
补充:不要让double干扰你的位域
在结构体和类中,可以使用位域来规定某个成员所能占用的空间,所以使用位域能在一定程度上节省结构体占用的空间。不过考虑下面的代码:
struct s1
{
int i: 8;
int j: 4;
double b;
int a:3;
};
struct s2
{
int i;
int j;
double b;
int a;
};
struct s3
{
int i;
int j;
int a;
double b;
};
struct s4
{
int i: 8;
int j: 4;
int a:3;
double b;
};
cout< 可以看到,有double存在会干涉到位域,所以使用位域的的时候,最好把float类型和double类型放在程序的开始或者最后。
相关常数:
| sizeof int | 4 |
|---|---|
| sizeof short | 2 |
| sizeof long | 4 |
| sizeof float | 4 |
| sizeof double | 8 |
| sizeof char | 1 |
| sizeof p | 4 |
| sizeof WORD | 2 |
| sizeof DWORD | 4 |
九、new和delete
在 C++ 中,你也许经常使用 new 和 delete 来动态申请和释放内存,但你可曾想过以下问题呢?
-
new 和 delete 是函数吗?
-
new [] 和 delete [] 又是什么?什么时候用它们?
-
你知道 operator new 和 operator delete 吗?
-
为什么 new [] 出来的数组有时可以用 delete 释放有时又不行?
-
…
接下来一一进行说明:
1、new 和 delete 到底是什么?
如果找工作的同学看一些面试的书,我相信都会遇到这样的题:sizeof 不是函数,然后举出一堆的理由来证明 sizeof 不是函数。在这里,和 sizeof 类似,new 和 delete 也不是函数,它们都是 C++ 定义的关键字,通过特定的语法可以组成表达式。和 sizeof 不同的是,sizeof 在编译时候就可以确定其返回值,new 和 delete 背后的机制则比较复杂。继续往下之前,请你想想你认为 new 应该要做些什么?也许你第一反应是,new 不就和 C 语言中的 malloc 函数一样嘛,就用来动态申请空间的。你答对了一半,看看下面语句:
string *ps = new string("hello world");
你就可以看出 new 和 malloc 还是有点不同的,malloc 申请完空间之后不会对内存进行必要的初始化,而 new 可以。所以 new expression 背后要做的事情不是你想象的那么简单。在我用实例来解释 new 背后的机制之前,你需要知道 operator new 和 operator delete 是什么玩意。
2、operator new 和 operator delete
这两个其实是 C++ 语言标准库的库函数,原型分别如下:
void *operator new(size_t); //allocate an object
void *operator delete(void *); //free an object
void *operator new[](size_t); //allocate an array
void *operator delete[](void *); //free an array
后面两个你可以先不看,后面再介绍。前面两个均是 C++ 标准库函数,你可能会觉得这是函数吗?请不要怀疑,这就是函数!C++ Primer 一书上说这不是重载 new 和 delete 表达式(如 operator= 就是重载 = 操作符),因为 new 和 delete 是不允许重载的。但我还没搞清楚为什么要用 operator new 和 operator delete 来命名,比较费解。我们只要知道它们的意思就可以了,这两个函数和 C 语言中的 malloc 和 free 函数有点像了,都是用来申请和释放内存的,并且 operator new 申请内存之后不对内存进行初始化,直接返回申请内存的指针。
我们可以直接在我们的程序中使用这几个函数。
3、new 和 delete 背后机制
知道上面两个函数之后,我们用一个实例来解释 new 和 delete 背后的机制:
我们不用简单的 C++ 内置类型来举例,使用复杂一点的类类型,定义一个类 A:
class A
{
public:
A(int v) : var(v)
{
fopen_s(&file, "test", "r");
}
~A()
{
fclose(file);
}
private:
int var;
FILE *file;
};
很简单,类 A 中有两个私有成员,有一个构造函数和一个析构函数,构造函数中初始化私有变量 var 以及打开一个文件,析构函数关闭打开的文件。
我们使用
class A *pA = new A(10);
来创建一个类的对象,返回其指针 pA。如下图所示 new 背后完成的工作:
简单总结一下:
-
首先需要调用上面提到的 operator new 标准库函数,传入的参数为 class A 的大小,这里为 8 个字节,至于为什么是 8 个字节,你可以看看《深入 C++ 对象模型》一书,这里不做多解释。这样函数返回的是分配内存的起始地址,这里假设是 0x007da290。
-
上面分配的内存是未初始化的,也是未类型化的,第二步就在这一块原始的内存上对类对象进行初始化,调用的是相应的构造函数,这里是调用
A:A(10);这个函数,从图中也可以看到对这块申请的内存进行了初始化,var=10, file 指向打开的文件。 -
最后一步就是返回新分配并构造好的对象的指针,这里 pA 就指向 0x007da290 这块内存,pA 的类型为类 A 对象的指针。
所有这三步,你都可以通过反汇编找到相应的汇编代码,在这里我就不列出了。
好了,那么 delete 都干了什么呢?还是接着上面的例子,如果这时想释放掉申请的类的对象怎么办?当然我们可以使用下面的语句来完成:
delete pA;
delete 所做的事情如下图所示:
delete 就做了两件事情:
-
调用 pA 指向对象的析构函数,对打开的文件进行关闭。
-
通过上面提到的标准库函数 operator delete 来释放该对象的内存,传入函数的参数为 pA 的值,也就是 0x007d290。
好了,解释完了 new 和 delete 背后所做的事情了,是不是觉得也很简单?不就多了一个构造函数和析构函数的调用嘛。
4、如何申请和释放一个数组?
我们经常要用到动态分配一个数组,也许是这样的:
string *psa = new string[10]; //array of 10 empty strings
int *pia = new int[10]; //array of 10 uninitialized ints
上面在申请一个数组时都用到了 new [] 这个表达式来完成,按照我们上面讲到的 new 和 delete 知识,第一个数组是 string 类型,分配了保存对象的内存空间之后,将调用 string 类型的默认构造函数依次初始化数组中每个元素;第二个是申请具有内置类型的数组,分配了存储 10 个 int 对象的内存空间,但并没有初始化。
如果我们想释放空间了,可以用下面两条语句:
delete [] psa;
delete [] pia;
都用到 delete [] 表达式,注意这地方的 [] 一般情况下不能漏掉!我们也可以想象这两个语句分别干了什么:第一个对 10 个 string 对象分别调用析构函数,然后再释放掉为对象分配的所有内存空间;第二个因为是内置类型不存在析构函数,直接释放为 10 个 int 型分配的所有内存空间。
这里对于第一种情况就有一个问题了:我们如何知道 psa 指向对象的数组的大小?怎么知道调用几次析构函数?
这个问题直接导致我们需要在 new [] 一个对象数组时,需要保存数组的维度,C++ 的做法是在分配数组空间时多分配了 4 个字节的大小,专门保存数组的大小,在 delete [] 时就可以取出这个保存的数,就知道了需要调用析构函数多少次了。
还是用图来说明比较清楚,我们定义了一个类 A,但不具体描述类的内容,这个类中有显示的构造函数、析构函数等。那么 当我们调用
class A *pAa = new A[3];
时需要做的事情如下:
从这个图中我们可以看到申请时在数组对象的上面还多分配了 4 个字节用来保存数组的大小,但是最终返回的是对象数组的指针,而不是所有分配空间的起始地址。
这样的话,释放就很简单了:
delete []pAa;
这里要注意的两点是:
- 调用析构函数的次数是从数组对象指针前面的 4 个字节中取出;
- 传入
operator delete[]函数的参数不是数组对象的指针 pAa,而是 pAa 的值减 4。
5、为什么 new/delete 、new []/delete[] 要配对使用?
其实说了这么多,还没到我写这篇文章的最原始意图。从上面解释的你应该懂了 new/delete、new[]/delete[] 的工作原理了,因为它们之间有差别,所以需要配对使用。但偏偏问题不是这么简单,这也是我遇到的问题,如下这段代码:
int *pia = new int[10];
delete []pia;
这肯定是没问题的,但如果把 delete []pia; 换成 delete pia; 的话,会出问题吗?
这就涉及到上面一节没提到的问题了。上面我提到了在 new [] 时多分配 4 个字节的缘由,因为析构时需要知道数组的大小,但如果不调用析构函数呢(如内置类型,这里的 int 数组)?我们在 new [] 时就没必要多分配那 4 个字节, delete [] 时直接到第二步释放为 int 数组分配的空间。如果这里使用 delete pia;那么将会调用 operator delete 函数,传入的参数是分配给数组的起始地址,所做的事情就是释放掉这块内存空间。不存在问题的。
这里说的使用 new [] 用 delete 来释放对象的提前是:对象的类型是内置类型或者是无自定义的析构函数的类类型!
我们看看如果是带有自定义析构函数的类类型,用 new [] 来创建类对象数组,而用 delete 来释放会发生什么?用上面的例子来说明:
class A *pAa = new class A[3];
delete pAa;
那么 delete pAa; 做了两件事:
-
调用一次 pAa 指向的对象的析构函数;
-
调用 operator delete(pAa); 释放内存。
显然,**这里只对数组的第一个类对象调用了析构函数**,后面的两个对象均没调用析构函数,如果类对象中申请了大量的内存需要在析构函数中释放,而你却在销毁数组对象时少调用了析构函数,这会造成内存泄漏。 上面的问题你如果说没关系的话,那么第二点就是致命的了!直接释放 pAa 指向的内存空间,这个总是会造成严重的段错误,程序必然会奔溃!因为分配的空间的起始地址是 pAa 指向的地方减去 4 个字节的地方。你应该传入参数设为那个地址! 同理,你可以分析如果使用 new 来分配,用 `delete []` 来释放会出现什么问题?是不是总会导致程序错误? 总的来说,记住一点即可:**new/delete、new[]/delete[] 要配套使用总是没错的!**
十、const_cast
const_cast是一种C++运算符,主要是用来去除复合类型中const和volatile属性(没有真正去除)。
变量本身的const属性是不能去除的,要想修改变量的值,一般是去除指针(或引用)的const属性,再进行间接修改。
用法:
const_cast(expression)
通过const_cast运算符,也只能将const type*转换为type*,将const type&转换为type&。
也就是说源类型和目标类型除了const属性不同,其他地方完全相同。
注意:
const_cast的目的并不是为了让你去修改一个本身被定义为const的值,因为这样做的后果是无法预期的。const_cast的目的是修改一些指针/引用的权限,如果我们原本无法通过这些指针/引用修改某块内存的值,现在你可以了。
十一、dynamic_cast
作为四个内部类型转换操作符之一的dynamic_cast和传统的C风格的强制类型转换有着巨大的差别。除了dynamic_cast以外的转换,其行为的都是在编译期就得以确定的,转换是否成功,并不依赖被转换的对象。而dynamic_cast则不然。在这里,不再讨论其他三种转换和C风格的转换。
首先,dynamic_cast依赖于RTTI信息,其次,在转换时,dynamic_cast会检查转换的source对象是否真的可以转换成target类型,这种检查不是语法上的,而是真实情况的检查。
先看RTTI相关部分,通常,许多编译器都是通过vtable找到对象的RTTI信息的,这也就意味着,如果基类没有虚方法,也就无法判断一个基类指针变量所指对象的真实类型,这时候,dynamic_cast只能用来做安全的转换,例如从派生类指针转换成基类指针。而这种转换其实并不需要dynamic_cast参与。
也就是说,dynamic_cast是根据RTTI记载的信息来判断类型转换是否合法的。
用法:同static_cast
dynamic_cast主要用于类层次结构中父类和子类之间指针和引用的转换,由于具有运行时类型检查,因此可以保证下行转换的安全性,何为安全性?即转换成功就返回转换后的正确类型指针,如果转换失败,则返回NULL,之所以说static_cast在下行转换时不安全,是因为即使转换失败,它也不返回NULL。
对于上行转换,dynamic_cast和static_cast是一样的。
对于下行转换,说到下行转换,有一点需要了解的是在C++中,一般是可以用父类指针指向一个子类对象,如parent* P1 = new Children(); 但这个指针只能访问父类定义的数据成员和函数,这是C++中的静态联翩,但一般不定义指向父类对象的子类类型指针,如Children* P1 = new parent;这种定义方法不符合生活习惯,在程序设计上也很麻烦。**这就解释了也说明了,在上行转换中,static_cast和dynamic_cast效果是一样的,而且都比较安全,因为向上转换的对象一般是指向子类对象的子类类型指针;而在下行转换中,由于可以定义就不同了指向子类对象的父类类型指针,同时static_cast只在编译时进行类型检查,而dynamic_cast是运行时类型检查,则需要视情况而定。**下面通过代码进行说明
class Base
{
virtual void fun(){}
};
class Derived:public Base
{
};
由于需要进行向下转换,因此需要定义一个父类类型的指针Base *P,但是由于子类继承与父类,父类指针可以指向父类对象,也可以指向子类对象,这就是重点所在。如果 P指向的确实是子类对象,则dynamic_cast和static_cast都可以转换成功,如下所示:
Base *P = new Derived();
Derived *pd1 = static_cast(P);
Derived *pd2 = dynamic_cast(P);
以上转换都能成功。
但是,如果 P 指向的不是子类对象,而是父类对象,如下所示:
Base *P = new Base;
Derived *pd3 = static_cast(P);
Derived *pd4 = dynamic_cast(P);
在以上转换中,static_cast转换在编译时不会报错,也可以返回一个子类对象指针(假想),但是这样是不安全的,在运行时可能会有问题,因为子类中包含父类中没有的数据和函数成员,这里需要理解转换的字面意思,转换是什么?转换就是把对象从一种类型转换到另一种类型,如果这时用 pd3 去访问子类中有但父类中没有的成员,就会出现访问越界的错误,导致程序崩溃。而dynamic_cast由于具有运行时类型检查功能,它能检查P的类型,由于上述转换是不合理的,所以它返回NULL。
总结
C++中层次类型转换中无非两种:上行转换和下行转换
对于上行转换,static_cast和dynamic_cast效果一样,都安全;
对于下行转换:你必须确定要转换的数据确实是目标类型的数据,即需要注意要转换的父类类型指针是否真的指向子类对象,如果是,static_cast和dynamic_cast都能成功;如果不是static_cast能返回,但是不安全,可能会出现访问越界错误,而dynamic_cast在运行时类型检查过程中,判定该过程不能转换,返回NULL。
注:虚函数对于dynamic_cast转换的作用?为何使用dynamic_cast转换类指针时,需要虚函数呢?
Dynamic_cast转换是在运行时进行转换,运行时转换就需要知道类对象的信息(继承关系等)。
如何在运行时获取到这个信息------虚函数表。
C++对象模型中,对象实例最前面的就是虚函数表指针,通过这个指针可以获取到该类对象的所有虚函数,包括父类的。
因为派生类会继承基类的虚函数表,所以通过这个虚函数表,我们就可以知道该类对象的父类,在转换的时候就可以用来判断对象有无继承关系。
所以虚函数对于正确的基类指针转换为子类指针是非常重要的。
十二、reinterpret_cast
允许将任何指针转换为任何其他指针类型。也允许将任何整数类型转换为任何指针类型以及反向转换。
语法:
reinterpret_cast < type-id > ( expression )
- 滥用 reinterpret_cast 运算符可能很容易带来风险。除非所需转换本身是低级别的,否则应使用其他强制转换运算符之一。
- reinterpret_cast 运算符可用于 char* 到 int* 或 One_class* 到 Unrelated_class* 之类的转换,这本身并不安全。
- reinterpret_cast 的结果不能安全地用于除强制转换回其原始类型以外的任何用途。在最好的情况下,其他用途也是不可移植的。
- reinterpret_cast 运算符不能丢掉 const、volatile 或 __unaligned 特性。有关移除这些特性的详细信息,请参阅 const_cast Operator。
- reinterpret_cast 运算符将 null 指针值转换为目标类型的 null 指针值。
- reinterpret_cast 的一个实际用途是在哈希函数中,即,通过让两个不同的值几乎不以相同的索引结尾的方式将值映射到索引。
#include
using namespace std;
// Returns a hash code based on an address
unsigned short Hash( void *p ) {
unsigned int val = reinterpret_cast( p );
return ( unsigned short )( val ^ (val >> 16));
}
int main() {
int a[20];
for ( int i = 0; i < 20; i++ )
cout << Hash( a + i ) << endl;
}
Output:
64641
64645
64889
64893
64881
64885
64873
64877
64865
64869
64857
64861
64849
64853
64841
64845
64833
64837
64825
64829
reinterpret_cast 允许将指针视为整数类型。结果随后将按位移位并与自身进行“异或”运算以生成唯一的索引(具有唯一性的概率非常高)。该索引随后被标准 C 样式强制转换截断为函数的返回类型。
十三、static_cast
用法:
static_cast < type-id > ( expression )
该运算符把expression转换为type-id类型,但没有运行时类型检查来保证转换的安全性,它主要有如下几种用法:
-
用于基本数据类型之间的转换,如把int转换为char,把int转换成enum,但这种转换的安全性需要开发者自己保证(这可以理解为保证数据的精度,即程序员能不能保证自己想要的程序安全),如在把int转换为char时,如果char没有足够的比特位来存放int的值(int>127或int<-127时),那么static_cast所做的只是简单的截断,及简单地把int的低8位复制到char的8位中,并直接抛弃高位。
-
把空指针转换成目标类型的空指针
-
把任何类型的表达式类型转换成void类型
-
用于类层次结构中父类和子类之间指针和引用的转换。
对于以上第(4)点,存在两种形式的转换,即上行转换(子类到父类)和下行转换(父类到子类)。对于static_cast,上行转换时安全的,而下行转换时不安全的,为什么呢?因为static_cast的转换时粗暴的,它仅根据类型转换语句中提供的信息(尖括号中的类型)来进行转换,这种转换方式对于上行转换,由于子类总是包含父类的所有数据成员和函数成员,因此从子类转换到父类的指针对象可以没有任何顾虑的访问其(指父类)的成员。而对于下行转换为什么不安全,是因为static_cast只是在编译时进行类型坚持,没有运行时的类型检查,具体原理在dynamic_cast中说明。
十四、explicit
首先, C++中的explicit关键字只能用于修饰只有一个参数的类构造函数, 它的作用是表明该构造函数是显示的, 而非隐式的, 跟它相对应的另一个关键字是implicit, 意思是隐藏的,类构造函数默认情况下即声明为implicit(隐式).
那么显示声明的构造函数和隐式声明的有什么区别呢? 我们来看下面的例子:
class CxString // 没有使用explicit关键字的类声明, 即默认为隐式声明
{
public:
char *_pstr;
int _size;
CxString(int size)
{
_size = size; // string的预设大小
_pstr = malloc(size + 1); // 分配string的内存
memset(_pstr, 0, size + 1);
}
CxString(const char *p)
{
int size = strlen(p);
_pstr = malloc(size + 1); // 分配string的内存
strcpy(_pstr, p); // 复制字符串
_size = strlen(_pstr);
}
// 析构函数这里不讨论, 省略...
};
// 下面是调用:
CxString string1(24); // 这样是OK的, 为CxString预分配24字节的大小的内存
CxString string2 = 10; // 这样是OK的, 为CxString预分配10字节的大小的内存
CxString string3; // 这样是不行的, 因为没有默认构造函数, 错误为: “CxString”: 没有合适的默认构造函数可用
CxString string4("aaaa"); // 这样是OK的
CxString string5 = "bbb"; // 这样也是OK的, 调用的是CxString(const char *p)
CxString string6 = 'c'; // 这样也是OK的, 其实调用的是CxString(int size), 且size等于'c'的ascii码
string1 = 2; // 这样也是OK的, 为CxString预分配2字节的大小的内存
string2 = 3; // 这样也是OK的, 为CxString预分配3字节的大小的内存
string3 = string1; // 这样也是OK的, 至少编译是没问题的, 但是如果析构函数里用free释放_pstr内存指针的时候可能会报错, 完整的代码必须重载运算符"=", 并在其中处理内存释放
上面的代码中, “CxString string2 = 10;” 这句为什么是可以的呢? 在C++中, 如果的构造函数只有一个参数时, 那么在编译的时候就会有一个缺省的转换操作:将该构造函数对应数据类型的数据转换为该类对象. 也就是说 “CxString string2 = 10;” 这段代码, 编译器自动将整型转换为CxString类对象, 实际上等同于下面的操作:
CxString string2(10);
//或
CxString temp(10);
CxString string2 = temp;
但是, 上面的代码中的_size代表的是字符串内存分配的大小, 那么调用的第二句 “CxString string2 = 10;” 和第六句 “CxString string6 = ‘c’;” 就显得不伦不类, 而且容易让人疑惑。有什么办法阻止这种用法呢? 答案就是使用explicit关键字。我们把上面的代码修改一下, 如下:
class CxString // 使用关键字explicit的类声明, 显示转换
{
public:
char *_pstr;
int _size;
explicit CxString(int size)
{
_size = size;
// 代码同上, 省略...
}
CxString(const char *p)
{
// 代码同上, 省略...
}
};
// 下面是调用:
CxString string1(24); // 这样是OK的
CxString string2 = 10; // 这样是不行的, 因为explicit关键字取消了隐式转换
CxString string3; // 这样是不行的, 因为没有默认构造函数
CxString string4("aaaa"); // 这样是OK的
CxString string5 = "bbb"; // 这样也是OK的, 调用的是CxString(const char *p)
CxString string6 = 'c'; // 这样是不行的, 其实调用的是CxString(int size), 且size等于'c'的ascii码, 但explicit关键字取消了隐式转换
string1 = 2; // 这样也是不行的, 因为取消了隐式转换
string2 = 3; // 这样也是不行的, 因为取消了隐式转换
string3 = string1; // 这样也是不行的, 因为取消了隐式转换, 除非类实现操作符"="的重载
explicit关键字的作用就是防止类构造函数的隐式自动转换。上面也已经说过了, explicit关键字只对有一个参数的类构造函数有效, 如果类构造函数参数大于或等于两个时, 是不会产生隐式转换的, 所以explicit关键字也就无效了。例如:
class CxString // explicit关键字在类构造函数参数大于或等于两个时无效
{
public:
char *_pstr;
int _age;
int _size;
explicit CxString(int age, int size)
{
_age = age;
_size = size;
// 代码同上, 省略...
}
CxString(const char *p)
{
// 代码同上, 省略...
}
};
// 这个时候有没有explicit关键字都是一样的
但是, 也有一个例外, 就是当除了第一个参数以外的其他参数都有默认值的时候, explicit关键字依然有效, 此时, 当调用构造函数时只传入一个参数, 等效于只有一个参数的类构造函数, 例子如下:
class CxString // 使用关键字explicit声明
{
public:
int _age;
int _size;
explicit CxString(int age, int size = 0)
{
_age = age;
_size = size;
// 代码同上, 省略...
}
CxString(const char *p)
{
// 代码同上, 省略...
}
};
// 下面是调用:
CxString string1(24); // 这样是OK的
CxString string2 = 10; // 这样是不行的, 因为explicit关键字取消了隐式转换
CxString string3; // 这样是不行的, 因为没有默认构造函数
string1 = 2; // 这样也是不行的, 因为取消了隐式转换
string2 = 3; // 这样也是不行的, 因为取消了隐式转换
string3 = string1; // 这样也是不行的, 因为取消了隐式转换, 除非类实现操作符"="的重载
以上即为C++ explicit关键字的详细介绍。
总结:
explicit关键字只需用于类内的单参数构造函数前面。由于无参数的构造函数和多参数的构造函数总是显示调用,这种情况在构造函数前加explicit无意义。
google的c++规范中提到explicit的优点是可以避免不合时宜的类型变换,缺点无。所以google约定所有单参数的构造函数都必须是显示的,只有极少数情况下拷贝构造函数可以不声明称explicit。例如作为其他类的透明包装器的类。
effective c++中说:被声明为explicit的构造函数通常比其non-explicit兄弟更受欢迎。因为它们禁止编译器执行非预期(往往也不被期望)的类型转换。除非我有一个好理由允许构造函数被用于隐式类型转换,否则我会把它声明为explicit,鼓励大家遵循相同的政策。
十五、inline
1、引入inline关键字的原因
在c/c++中,为了解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,特别的引入了inline修饰符,表示为内联函数。
栈空间就是指放置程序的局部数据(也就是函数内数据)的内存空间。
在系统下,栈空间是有限的,假如频繁大量的使用就会造成因栈空间不足而导致程序出错的问题,如,函数的死循环递归调用的最终结果就是导致栈内存空间枯竭。
下面我们来看一个例子:
#include
//函数定义为inline即:内联函数
inline char* dbtest(int a) {
return (i % 2 > 0) ? "奇" : "偶";
}
int main()
{
int i = 0;
for (i=1; i < 100; i++) {
printf("i:%d 奇偶性:%s /n", i, dbtest(i));
}
}
上面的例子就是标准的内联函数的用法,使用inline修饰带来的好处我们表面看不出来,其实,在内部的工作就是在每个for循环的内部任何调用dbtest(i)的地方都换成了(i%2>0)?”奇”:”偶”,这样就避免了频繁调用函数对栈内存重复开辟所带来的消耗。
2、inline使用限制
inline的使用是有所限制的,inline只适合函数体内代码简单的函数使用,不能包含复杂的结构控制语句例如while、switch,并且不能内联函数本身不能是直接递归函数(即,自己内部还调用自己的函数)。
3、inline仅是一个对编译器的建议
inline函数仅仅是一个对编译器的建议,所以最后能否真正内联,看编译器的意思,它如果认为函数不复杂,能在调用点展开,就会真正内联,并不是说声明了内联就会内联,声明内联只是一个建议而已。
4、建议:inline函数的定义放在头文件中
其次,因为内联函数要在调用点展开,所以编译器必须随处可见内联函数的定义,要不然就成了非内联函数的调用了。所以,这要求每个调用了内联函数的文件都出现了该内联函数的定义。
因此,将内联函数的定义放在头文件里实现是合适的,省却你为每个文件实现一次的麻烦。
声明跟定义要一致:如果在每个文件里都实现一次该内联函数的话,那么,最好保证每个定义都是一样的,否则,将会引起未定义的行为。如果不是每个文件里的定义都一样,那么,编译器展开的是哪一个,那要看具体的编译器而定。所以,最好将内联函数定义放在头文件中。
5、类中的成员函数与inline
定义在类中的成员函数缺省都是内联的,如果在类定义时就在类内给出函数定义,那当然最好。如果在类中未给出成员函数定义,而又想内联该函数的话,那在类外要加上inline,否则就认为不是内联的。
例如:
class A
{
public:void Foo(int x, int y) { } // 自动地成为内联函数
}
将成员函数的定义体放在类声明之中虽然能带来书写上的方便,但不是一种良好的编程风格,上例应该改成:
// 头文件
class A
{
public:
void Foo(int x, int y);
}
// 定义文件
inline void A::Foo(int x, int y){}
6、inline 是一种“用于实现的关键字”
关键字inline 必须与函数定义体放在一起才能使函数成为内联,仅将inline 放在函数声明前面不起任何作用。
如下风格的函数Foo 不能成为内联函数:
inline void Foo(int x, int y); // inline 仅与函数声明放在一起
void Foo(int x, int y){}
而如下风格的函数Foo 则成为内联函数:
void Foo(int x, int y);
inline void Foo(int x, int y) {} // inline 与函数定义体放在一起
所以说,inline 是一种“用于实现的关键字”,而不是一种“用于声明的关键字”。一般地,用户可以阅读函数的声明,但是看不到函数的定义。尽管在大多数教科书中内联函数的声明、定义体前面都加了inline 关键字,但我认为inline不应该出现在函数的声明中。这个细节虽然不会影响函数的功能,但是体现了高质量C++/C 程序设计风格的一个基本原则:声明与定义不可混为一谈,用户没有必要、也不应该知道函数是否需要内联。
7、慎用inline
内联能提高函数的执行效率,为什么不把所有的函数都定义成内联函数?如果所有的函数都是内联函数,还用得着“内联”这个关键字吗?
内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。
如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
以下情况不宜使用内联:
- 如果函数体内的代码比较长,使用内联将导致内存消耗代价较高。
- 如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。类的构造函数和析构函数容易让人误解成使用内联更有效。要当心构造函数和析构函数可能会隐藏一些行为,如“偷偷地”执行了基类或成员对象的构造函数和析构函数。所以不要随便地将构造函数和析构函数的定义体放在类声明中。一个好的编译器将会根据函数的定义体,自动地取消不值得的内联(这进一步说明了 inline 不应该出现在函数的声明中)。
8、总结
内联函数并不是一个增强性能的灵丹妙药。只有当函数非常短小的时候它才能得到我们想要的效果;但是,如果函数并不是很短而且在很多地方都被调用的话,那么将会使得可执行体的体积增大。
最令人烦恼的还是当编译器拒绝内联的时候。在老的实现中,结果很不尽人意,虽然在新的实现中有很大的改善,但是仍然还是不那么完善的。一些编译器能够足够的聪明来指出哪些函数可以内联哪些不能,但是大多数编译器就不那么聪明了,因此这就需要我们的经验来判断。如果内联函数不能增强性能,就避免使用它!
十六、operator
operator是C++的关键字,它和运算符一起使用,表示一个运算符函数,理解时应将operator=整体上视为一个函数名。
这是C++扩展运算符功能的方法,虽然样子古怪,但也可以理解:一方面要使运算符的使用方法与其原来一致,另一方面扩展其功能只能通过函数的方式(c++中,“功能”都是由函数实现的)。
一、为什么使用操作符重载?
对于系统的所有操作符,一般情况下,只支持基本数据类型和标准库中提供的class,对于用户自己定义的class,如果想支持基本操作,比如比较大小,判断是否相等,等等,则需要用户自己来定义关于这个操作符的具体实现。比如,判断两个人是否一样大,我们默认的规则是按照其年龄来比较,所以,在设计person 这个class的时候,我们需要考虑操作符==,而且,根据刚才的分析,比较的依据应该是age。那么为什么叫重载呢?这是因为,在编译器实现的时候,已经为我们提供了这个操作符的基本数据类型实现版本,但是现在他的操作数变成了用户定义的数据类型class,所以,需要用户自己来提供该参数版本的实现。
二、如何声明一个重载的操作符?
-
操作符重载实现为类成员函数
重载的操作符在类体中被声明,声明方式如同普通成员函数一样,只不过他的名字包含关键字**operator**,以及紧跟其后的一个c++预定义的操作符。 可以用如下的方式来声明一个预定义的==操作符:
class person{
private:
int age;
public:
person(int a){
this->age=a;
}
inline bool operator == (const person &ps) const;
};
实现方式如下:
inline bool person::operator==(const person &ps) const
{
if (this->age==ps.age)
return true;
return false;
}
调用方式如下:
int main()
{
person p1(10);
person p2(20);
if(p1==p2) cout<<"the age is equal!"< 这里,因为operator 是class person的一个成员函数,所以对象p1,p2都可以调用该函数,上面的if语句中,相当于p1调用函数,把p2作为该函数的一个参数传递给该函数,从而实现了两个对象的比较。
-
操作符重载实现为非类成员函数(全局函数)
对于全局重载操作符,代表左操作数的参数必须被显式指定。例如:
class person { public: int age; bool operator==(person const &p1 ,person const & p2); }; //满足要求,做操作数的类型被显示指定 bool person::operator==(person const &p1 ,person const & p2) { if(p1.age==p2.age) return true; return false; } int main() { person rose; person jack; rose.age=18; jack.age=23; if(rose==jack) cout<<"ok"< return 0; } -
如何决定把一个操作符重载为类成员函数还是全局名字空间的成员呢?
- 如果一个重载操作符是类成员,那么只有当与他一起使用的左操作数是该类的对象时,该操作符才会被调用。如果该操作符的左操作数必须是其他的类型,则操作符必须被重载为全局名字空间的成员。
- C++要求赋值=,下标[],调用(), 和成员指向-> 操作符必须被定义为类成员操作符。任何把这些操作符定义为名字空间成员的定义都会被标记为编译时刻错误。
- 如果有一个操作数是类类型如string类的情形那么对于对称操作符比如等于操作符最好定义为全局名字空间成员。
- 重载操作符具有以下限制:
- 只有C++预定义的操作符集中的操作符才可以被重载;

-
对于内置类型的操作符,它的预定义不能被改变,应不能为内置类型重载操作符,如,不能改变int型的操作符+的含义;
-
也不能为内置的数据类型定义其它的操作符;
-
只能重载类类型或枚举类型的操作符;
-
重载操作符不能改变它们的操作符优先级;
-
重载操作符不能改变操作数的个数;
-
除了对( )操作符外,对其他重载操作符提供缺省实参都是非法的;
- 注意点
-
后果载操操作符首先要确定它的返回值是左值,还是右值,如果是左值最返回引用,如果是右值那就直接返回值;
-
+号等这样的操作符没有对象可以容纳改变后值,对于这样的情况最好返回数值,否则只能要操作符体内创建临时对象用于容纳改变后的值,如果在堆中创建临时对象返回指针或者引用,在操作符函数体外还需要释放它,如果返回的对象而不是引用或者指针,那么效率是比较低的。如果返回的是数值,最好在该类的构造函数中增加对该类型数值的转换函数,如:返回值是int类型,那么最好有一个int类型作为参数的构造函数。
-
在增量运算符中,放上一个整数形参,就是后增量运行符,它是值返回,对于前增量没有形参,而且是引用返回,示例:
class Test
{
public:
Test(x=3){ m_value = x}
Test &operator ++(); //前增量
Test &operator ++(int);//后增量
private:
Int m_value:
};
Test &Test::operator ++()
{
m_value ++; //先增量
return *this; //返回当前对象
}
Test Test::operator ++(int)
{
Test tmp(*this); //创建临时对象
m_value ++; //再增量
return temp; //返回临时对象
}
- 因为强制转换是针对基本数据类型的,所以对类类型的转换需自定义;
- 转换运行符重载声明形式:operator 类型名();它没有返回类型,因为类型名就代表了它的返回类型,所以返回类型显得多余。
- 一般来说,转换运算符与转换构造函数(即带一个参数的构造函数)是互逆的,如有了构造函数Test(int),那么最好有一个转换运算符int()。这样就不必提供对象参数重载运算符了,如Test a1(1);Test a2(2); Test a3; a3 = a1+a2;就不需要重载+号操作符了,因为对于a1+a2的运算,系统可能会先找有没有定义针对Test的+号操作符,如果没有,它就会找有没有针对Test类转换函数参数类型的+号操作符(因为可以将+号运行结果的类型通过转换函数转换为Test对象),因为Test类有个int类型的参数,对于int类型有+操作符,所以a1+a2真正执行的是Test(int(a1) + int(a2));即Test(3);
- 对于转换运算符,还有一个需要注意的地方就是,如果A类中有以B为参数的转换函数(构造函数),那B中不能有A的转换运算符,不然就存在转换的二义性,如:
class A{A(B&){…}}; class B{ operator A(){…}};那么以下语句就会有问题:
B b; A(b);//A(b)有就可能是A的构造函数,也可以是B的转换运算符
十七、template
C++模板
模板是C++支持参数化多态的工具,使用模板可以使用户为类或者函数声明一种一般模式,使得类中的某些数据成员或者成员函数的参数、返回值取得任意类型。
模板是一种对类型进行参数化的工具;
通常有两种形式:函数模板和类模板;
函数模板针对仅参数类型不同的函数;
类模板针对仅数据成员和成员函数类型不同的类。
使用模板的目的就是能够让程序员编写与类型无关的代码。比如编写了一个交换两个整型int 类型的swap函数,这个函数就只能实现int 型,对double,字符这些类型无法实现,要实现这些类型的交换就要重新编写另一个swap函数。使用模板的目的就是要让这程序的实现与类型无关,比如一个swap模板函数,即可以实现int 型,又可以实现double型的交换。模板可以应用于函数和类。下面分别介绍。
注意:模板的声明或定义只能在全局,命名空间或类范围内进行。即不能在局部范围,函数内进行,比如不能在main函数中声明或定义一个模板。
1、函数模板通式
- 函数模板的格式:
template 返回类型 函数名(参数列表)
{
函数体
}
其中template和class是关见字,class可以用typename 关见字代替,在这里typename 和class没区别,<>括号中的参数叫模板形参,模板形参和函数形参很相像,模板形参不能为空。****一但声明了模板函数就可以用模板函数的形参名声明类中的成员变量和成员函数,即可以在该函数中使用内置类型的地方都可以使用模板形参名。模板形参需要调用该模板函数时提供的模板实参来初始化模板形参,一旦编译器确定了实际的模板实参类型就称他实例化了函数模板的一个实例。比如swap的模板函数形式为
template void swap(T& a, T& b){}
当调用这样的模板函数时类型T就会被被调用时的类型所代替,比如swap(a,b)其中a和b是int 型,这时模板函数swap中的形参T就会被int 所代替,模板函数就变为swap(int &a, int &b)。而当swap(c,d)其中c和d是double类型时,模板函数会被替换为swap(double &a, double &b),这样就实现了函数的实现与类型无关的代码。
- 注意:对于函数模板而言不存在 h(int,int) 这样的调用,不能在函数调用的参数中指定模板形参的类型,对函数模板的调用应使用实参推演来进行,即只能进行 h(2,3) 这样的调用,或者int a, b; h(a,b)。
2、类模板通式
- 类模板的格式为:
template class 类名
{ ... };
类模板和函数模板都是以template开始后接模板形参列表组成,模板形参不能为空,**一但声明了类模板就可以用类模板的形参名声明类中的成员变量和成员函数,即可以在类中使用内置类型的地方都可以使用模板形参名来声明。**比如
template class A{public: T a; T b; T hy(T c, T &d);};
在类A中声明了两个类型为T的成员变量a和b,还声明了一个返回类型为T带两个参数类型为T的函数hy。
-
类模板对象的创建:比如一个模板类A,则使用类模板创建对象的方法为A m;在类A后面跟上一个**<>尖括号并在里面填上相应的类型,这样的话类A中凡是用到模板形参的地方都会被int** 所代替。当类模板有两个模板形参时创建对象的方法为**A
-
对于类模板,模板形参的类型必须在类名后的尖括号中明确指定。比如A<2> m;用这种方法把模板形参设置为int是错误的(编译错误:error C2079: ‘a’ uses undefined class ‘A’),类模板形参不存在实参推演的问题。也就是说不能把整型值2推演为int型传递给模板形参。要把类模板形参调置为int 型必须这样指定A m。
-
在类模板外部定义成员函数的方法为:
template<模板形参列表> 函数返回类型 类名<模板形参名>::函数名(参数列表){函数体}
比如有两个模板形参T1,T2的类A中含有一个**void h()**函数,则定义该函数的语法为:
template void A::h(){}
注意:当在类外面定义类的成员时template后面的模板形参应与要定义的类的模板形参一致。
- 再次提醒注意:模板的声明或定义只能在全局,命名空间或类范围内进行。即不能在局部范围,函数内进行,比如不能在main函数中声明或定义一个模板。
3、模板的形参
有三种类型的模板形参:类型形参,非类型形参和模板形参。
- 类型形参
-
类型模板形参:类型形参由关见字class或typename后接说明符构成,如template void h(T a){};其中T就是一个类型形参,类型形参的名字由用户自已确定。模板形参表示的是一个未知的类型。模板类型形参可作为类型说明符用在模板中的任何地方,与内置类型说明符或类类型说明符的使用方式完全相同,即可以用于指定返回类型,变量声明等。
-
不能为同一个模板类型形参指定两种不同的类型,比如templatevoid h(T a, T b){},语句调用h(2, 3.2)将出错,因为该语句给同一模板形参T指定了两种类型,第一个实参2把模板形参T指定为int,而第二个实参3.2把模板形参指定为double,两种类型的形参不一致,会出错。(针对函数模板)
-
针对函数模板是正确的,但是忽略了类模板。当我们声明类对象为:A a,比如templateT g(T a, T b){},语句调用a.g(2, 3.2)在编译时不会出错,但会有警告,因为在声明类对象的时候已经将T转换为int类型,而第二个实参3.2把模板形参指定为double,在运行时,会对3.2进行强制类型转换为3。当我们声明类的对象为:A a,此时就不会有上述的警告,因为从int到double是自动类型转换。
- 非类型形参
-
非类型模板形参:模板的非类型形参也就是内置类型形参,如template
class B{};其中int a 就是非类型的模板形参。 -
非类型形参在模板定义的内部是常量值,也就是说非类型形参在模板的内部是常量。
-
**非类型模板的形参只能是整型,指针和引用,像double,String, String **这样的类型是不允许的。但是double &,double *,**对象的引用或指针是正确的。
-
调用非类型模板形参的实参必须是一个常量表达式,即他必须能在编译时计算出结果。
-
注意:任何局部对象,局部变量,局部对象的地址,局部变量的地址都不是一个常量表达式,都不能用作非类型模板形参的实参。全局指针类型,全局变量,全局对象也不是一个常量表达式,不能用作非类型模板形参的实参。
-
全局变量的地址或引用,全局对象的地址或引用const类型变量是常量表达式,可以用作非类型模板形参的实参。
-
sizeof表达式的结果是一个常量表达式,也能用作非类型模板形参的实参。
-
当模板的形参是整型时调用该模板时的实参必须是整型的,且在编译期间是常量,比如template
class A{};如果有int b,这时A 不是常量,如果const int b,这时A -
非类型形参一般不应用于函数模板中,比如有函数模板template
void h(T b){} ,若使用**h(2)**调用会出现无法为非类型形参a推演出参数的错误,对这种模板函数可以用显示模板实参来解决,如用h -
非类型模板形参的形参和实参间所允许的转换
- 允许从数组到指针,从函数到指针的转换。如:template
class A{}; int b[1]; A m;即数组到指针的转换 - const修饰符的转换。如:template
class A{}; int b; A<&b> m; 即从int *到const int *的转换。 - 提升转换。如:template class A{}; const short b=2; A m; 即从short到int 的提升转换
- 整值转换。如:template class A{}; A<3> m; 即从int 到unsigned int的转换
- 常规转换。
十八、decltype
decltype和auto都可以用来推断类型,但是二者有几处明显的差异:1.auto忽略顶层const,decltype保留顶层const;2.对引用操作,auto推断出原有类型,decltype推断出引用;3.对解引用操作,auto推断出原有类型,decltype推断出引用;4.auto推断时会实际执行,decltype不会执行,只做分析。总之在使用中过程中和const、引用和指针结合时需要特别小心。
1.基本用法
int getSize();
int main(void)
{
int tempA = 2;
/*1.dclTempA为int*/
decltype(tempA) dclTempA;
/*2.dclTempB为int,对于getSize根本没有定义,但是程序依旧正常,因为decltype只做分析,并不调用getSize,*/
decltype(getSize()) dclTempB;
return 0;
}
2.与const结合
double tempA = 3.0;
const double ctempA = 5.0;
const double ctempB = 6.0;
const double *const cptrTempA = &ctempA;
/*1.dclTempA推断为const double(保留顶层const,此处与auto不同)*/
decltype(ctempA) dclTempA = 4.1;
/*2.dclTempA为const double,不能对其赋值,编译不过*/
dclTempA = 5;
/*3.dclTempB推断为const double * const*/
decltype(cptrTempA) dclTempB = &ctempA;
/*4.输出为4(32位计算机)和5*/
cout<3.与引用结合
int tempA = 0, &refTempA = tempA;
/*1.dclTempA为引用,绑定到tempA*/
decltype(refTempA) dclTempA = tempA;
/*2.dclTempB为引用,必须绑定到变量,编译不过*/
decltype(refTempA) dclTempB = 0;
/*3.dclTempC为引用,必须初始化,编译不过*/
decltype(refTempA) dclTempC;
/*4.双层括号表示引用,dclTempD为引用,绑定到tempA*/
decltype((tempA)) dclTempD = tempA;
const int ctempA = 1, &crefTempA = ctempA;
/*5.dclTempE为常量引用,可以绑定到普通变量tempA*/
decltype(crefTempA) dclTempE = tempA;
/*6.dclTempF为常量引用,可以绑定到常量ctempA*/
decltype(crefTempA) dclTempF = ctempA;
/*7.dclTempG为常量引用,绑定到一个临时变量*/
decltype(crefTempA) dclTempG = 0;
/*8.dclTempH为常量引用,必须初始化,编译不过*/
decltype(crefTempA) dclTempH;
/*9.双层括号表示引用,dclTempI为常量引用,可以绑定到普通变量tempA*/
decltype((ctempA)) dclTempI = ctempA;
4.与指针结合
int tempA = 2;
int *ptrTempA = &tempA;
/*1.常规使用dclTempA为一个int *的指针*/
decltype(ptrTempA) dclTempA;
/*2.需要特别注意,表达式内容为解引用操作,dclTempB为一个引用,引用必须初始化,故编译不过*/
decltype(*ptrTempA) dclTempB;
十九、throw、try、catch
可参考:异常处理:try,catch,throw,finally的用法
二十、virtual
1、虚函数与运行多态
首先看一个简单的例子:
#include
using namespace std;
class Base
{
public:
virtual void show() { cout<<" In Base \n"; }
};
class Derived: public Base
{
public:
void show() { cout<<"In Derived \n"; }
};
int main(void)
{
// 基类指针指向子类对象
Base *bp = new Derived;
bp->show(); // RUN-TIME POLYMORPHISM
return 0;
}
输出结果为:
In Derived
结论: 虚函数的调用取决于指向或者引用的对象的类型,而不是指针或者引用自身的类型。
虚函数控制下的运行多态有什么用?
假如我们在公司的人事管理系统中定义了一个基类 Employee(员工),里面包含了升职、加薪等虚函数。 由于Manager(管理人员)和Engineer(工程人员)的加薪和晋升流程是不一样的,因此我们需要实现一些继承类并重写这些函数。
有了上面这些以后,到了一年一度每个人都要加薪的时候,我们只需要一个简单的操作就可以完成,如下所示:
void globalRaiseSalary(Employee *emp[], int n)
{
for (int i = 0; i < n; i++)
emp[i]->raiseSalary();
}
总结: 虚函数使得我们可以创建一个统一的基类指针列表,并且调用不同子类的函数而无需知道子类对象究竟是什么。
虚函数表与虚函数指针
程序是如何知道在运行时该调用基类还是子类的函数? 这涉及到虚函数表和虚函数指针的概念。更多可以参考《C++ 虚函数表解析》。
vtable(虚函数表): 每一个含有虚函数的类都会维护一个虚函数表,里面按照声明顺序记录了虚函数的地址。
vptr(虚函数指针): 一个指向虚函数表的指针,每个对象都会拥有这样的一个指针。
插入一个例子:
class A
{
public:
virtual void fun();
};
class B
{
public:
void fun();
};
sizeof(A) > sizeof(B) // 因为A比B多了一个虚函数指针
这个时候我们再来看刚刚那个加薪的例子,其多态调用的形式如下图所示:
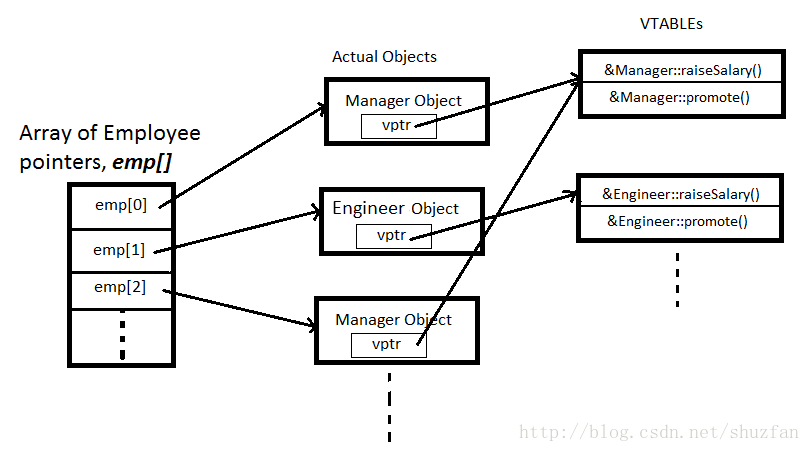
其核心要素还是我们一开始提到的结论:虚函数的调用取决于指向或者引用的对象的类型,而不是指针或者引用自身的类型。
2、虚函数中默认参数
先看下面一段代码:
#include
using namespace std;
class Base
{
public:
virtual void fun ( int x = 0 )
{
cout << "Base::fun(), x = " << x << endl;
}
};
class Derived : public Base
{
public:
// 这里的virtual关键字可以省略,因为只要基类里面被声明为虚函数,那么在子类中默认都是虚的
// 或者定义为 virtual void fun ( int x = 10)
virtual void fun ( int x )
{
cout << "Derived::fun(), x = " << x << endl;
}
};
int main()
{
Derived d1;
Base *bp = &d1;
bp->fun();
return 0;
}
上述代码的输出始终为
Derived::fun(), x = 0
解释与总结:
默认参数不包含在函数签名里。 (函数签名定义了函数的输入与输出,包括参数及参数的类型、返回值及其类型、可能会抛出或传回的exceptions、该方法在面向对象程序中的可用性方面的信息诸如public、static或prototype等关键字等)
默认参数是静态绑定的,虚函数是动态绑定的。 默认参数的使用需要看指针或者引用本身的类型,而不是对象的类型。
绝不重新定义继承而来的缺省参数(Never redefine function’s inherited default parameters value.)
3、静态函数可以声明为虚函数吗?
静态函数不可以声明为虚函数,同时也不能被const 和 volatile关键字修饰。
比如下面的声明都是错误的:
virtual static void fun() { }
static void fun() const { }
原因主要有两方面:
static成员函数不属于任何类对象或类实例,所以即使给此函数加上virutal也是没有任何意义
虚函数依靠vptr和vtable来处理。vptr是一个指针,在类的构造函数中创建生成,并且只能用this指针来访问它,静态成员函数没有this指针,所以无法访问vptr。
4、构造函数可以为虚函数吗?
构造函数不可以声明为虚函数。同时除了inline之外,构造函数不允许使用其它任何关键字。
为什么构造函数不可以为虚函数?
尽管虚函数表vtable是在编译阶段就已经建立的,但指向虚函数表的指针vptr是在运行阶段实例化对象时才产生的。 如果类含有虚函数,编译器会在构造函数中添加代码来创建vptr。 问题来了,如果构造函数是虚的,那么它需要vptr来访问vtable,可这个时候vptr还没产生。 因此,构造函数不可以为虚函数。
我们之所以使用虚函数,是因为需要在信息不全的情况下进行多态运行。而构造函数是用来初始化实例的,实例的类型必须是明确的。 因此,构造函数没有必要被声明为虚函数。
尽管构造函数不可以为虚函数,但是有些场景下我们确实需要 “Virtual Copy Constructor”。 “虚复制构造函数”的说法并不严谨,其只是一个实现了对象复制的功能的类内函数。 举一个应用场景,比如剪切板功能。 复制内容作为基类,但派生类可能包含文字、图片、视频等等。 我们只有在程序运行的时候才知道我们需要复制的具体是什么类型的数据。 实现方法如下:
class Base
{
public:
Base() {};
virtual ~Base() {};
virtual Base* Clone() {return new Base(*this);}
};
class Derived
{
public:
Derived() {};
virtual ~Derived() {};
virtual Base* Clone() {return new Derived(*this);}
};
调用方法如下:
Derived d;
Base* p = d.clone(); //p实际指向的是一个继承类对象,并且该对象和d完全一样,这就实现了copy
delete p;
下面着重解释下 return new Derived(*this)这句话。
“this”是待被复制的对象的地址,“*this”相当于解地址引用。 所以“*this”的类型是 “Derived &”,是待被复制的对象的引用。 所以上面这句话的意思是: 先用new开一块空间,然后用copy构造函数 Derived(const Derived &)来初始化这块内存。 由于用户没有定义copy构造函数,因此调用编译器产生的默认copy构造函数。
5、析构函数可以为虚函数吗?
析构函数可以声明为虚函数。如果我们需要删除一个指向派生类的基类指针时,应该把析构函数声明为虚函数。 事实上,只要一个类有可能会被其它类所继承, 就应该声明虚析构函数(哪怕该析构函数不执行任何操作)。
看下面的例子:
#include
using namespace std;
class base {
public:
base()
{ cout<<"Constructing base \n";
// virtual ~base()
~base()
{ cout<<"Destructing base \n"; }
};
class derived: public base {
public:
derived()
{ cout<<"Constructing derived \n"; }
~derived()
{ cout<<"Destructing derived \n"; }
};
int main(void)
{
derived *d = new derived();
base *b = d;
delete b;
getchar();
return 0;
}
可能的输出结果如下(不同编译器可能有差别):
Constructing base
Constructing derived
Destructing base
可见,继承类的析构函数没有被调用,delete时只根据指针类型调用了基类的析构函数。 正确的操作是,基类和继承类的析构函数都应该被调用,解决方法是将基类的析构函数声明为虚函数。
6、虚函数可以为私有函数吗?
虚函数可以被私有化,但有一些细节需要注意。
#include
using namespace std;
class Derived;
class Base {
private:
virtual void fun() { cout << "Base Fun"; }
friend int main();
};
class Derived: public Base {
public:
void fun() { cout << "Derived Fun"; }
};
int main()
{
Base *ptr = new Derived;
ptr->fun();
return 0;
}
输出结果为:
Derived fun()
基类指针指向继承类对象,则调用继承类对象的函数;
int main()必须声明为Base类的友元,否则编译失败。 编译器报错: ptr无法访问私有函数。 当然,把基类声明为public, 继承类为private,该问题就不存在了。
7、虚函数可以被内联吗?
通常类成员函数都会被编译器考虑是否进行内联。 但通过基类指针或者引用调用的虚函数必定不能被内联。 当然,实体对象调用虚函数或者静态调用时可以被内联,虚析构函数的静态调用也一定会被内联展开。 (参考《虚函数什么情况下会内联》)
#include
using namespace std;
class Base
{
public:
virtual void who()
{
cout << "I am Base\n";
}
};
class Derived: public Base
{
public:
void who()
{
cout << "I am Derived\n";
}
};
int main()
{
Base b;
b.who(); // 内联调用
Base *ptr = new Derived();
ptr->who(); // 通过基类指针调用,一定不会进行内联
return 0;
}
7、纯虚函数与抽象类
纯虚函数: 在基类中声明但不定义的虚函数,但要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加“=0”,如virtual void funtion1()=0;
抽象类: 含有纯虚函数的类为抽象类。
下面是一个简单的抽象类的例子;
#include
using namespace std;
class Base
{
int x;
public:
virtual void fun() = 0;
int getX() { return x; }
};
// 继承并重写基类声明的纯虚函数,如果没有重写,则该继承类也为抽象类
class Derived: public Base
{
int y;
public:
void fun() { cout << "fun() called"; }
};
int main(void)
{
Derived d;
d.fun();
return 0;
}
纯虚函数的特点以及用途总结如下
必须在继承类中重新声明该函数(实现可以为空),否则继承类仍为抽象类,程序无法编译通过;
派生类仅仅只是继承纯虚函数的接口,因此使用纯虚函数可以规范接口形式。
声明纯虚函数的基类无法实例化对象。 在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。为了解决上述问题,引入了纯虚函数,编译器要求在派生类中必须予以重写以实现多态性。
纯虚函数的声明就是在告诉子类的设计者,“你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。
可以使用指针或者引用指向抽象类性,比如下面的代码:
#include
using namespace std;
class Base
{
public:
virtual void show() = 0;
};
class Derived: public Base
{
public:
void show() { cout << "In Derived \n"; }
};
int main(void)
{
Base *bp = new Derived();
bp->show();
return 0;
}
抽象类可以拥有构造函数。示例如下:
#include
using namespace std;
// An abstract class with constructor
class Base
protected:
int x;
public:
virtual void fun() = 0;
Base(int i) { x = i; }
};
class Derived: public Base
{
int y;
public:
Derived(int i, int j):Base(i) { y = j; }
void fun() { cout << "x = " << x << ", y = " << y; }
};
int main(void)
{
Derived d(4, 5);
d.fun();
return 0;
}
析构函数被声明为纯虚函数是一种特例,允许其有具体实现。 (有些时候,想要使一个类成为抽象类,但刚好又没有任何纯虚函数。最简单的方法就是声明一个纯虚析构函数。)
#include
class Base
{
public:
virtual ~Base()=0; // 纯虚析构函数
};
Base::~Base()
{
std::cout << "Pure virtual destructor is called";
}
class Derived : public Base
{
public:
~Derived()
{
std::cout << "~Derived() is executed\n";
}
};
int main()
{
Base *b = new Derived();
delete b;
return 0;
}