Redis 和 IO 多路复用
最近在看 UNIX 网络编程并研究了一下 Redis 的实现,感觉 Redis 的源代码十分适合阅读和分析,其中 I/O 多路复用(mutiplexing)部分的实现非常干净和优雅,在这里想对这部分的内容进行简单的整理。
几种 I/O 模型
为什么 Redis 中要使用 I/O 多路复用这种技术呢?
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的, 但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
Blocking I/O
先来看一下传统的阻塞 I/O 模型到底是如何工作的:当使用 read 或者 write 对某一个文件描述符(File Descriptor 以下简称 FD)进行读写时,如果当前 FD 不可读或不可写,整个 Redis 服务就不会对其它的操作作出响应,导致整个服务不可用。
这也就是传统意义上的,也就是我们在编程中使用最多的阻塞模型:
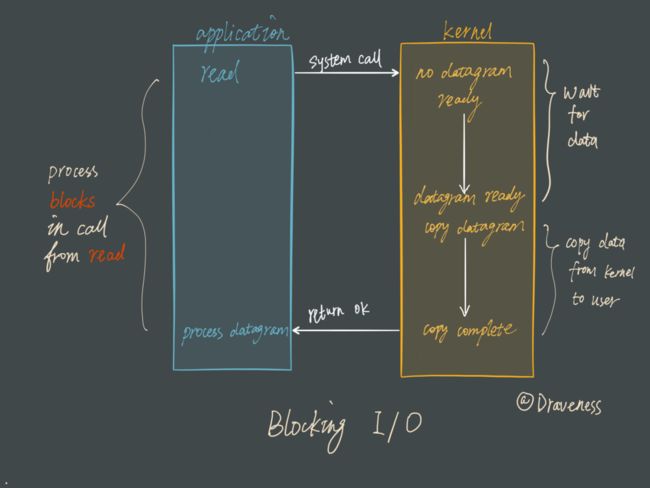
阻塞模型虽然开发中非常常见也非常易于理解,但是由于它会影响其他 FD 对应的服务,所以在需要处理多个客户端任务的时候,往往都不会使用阻塞模型。
I/O 多路复用
虽然还有很多其它的 I/O 模型,但是在这里都不会具体介绍。
阻塞式的 I/O 模型并不能满足这里的需求,我们需要一种效率更高的 I/O 模型来支撑 Redis 的多个客户(redis-cli),这里涉及的就是 I/O 多路复用模型了:
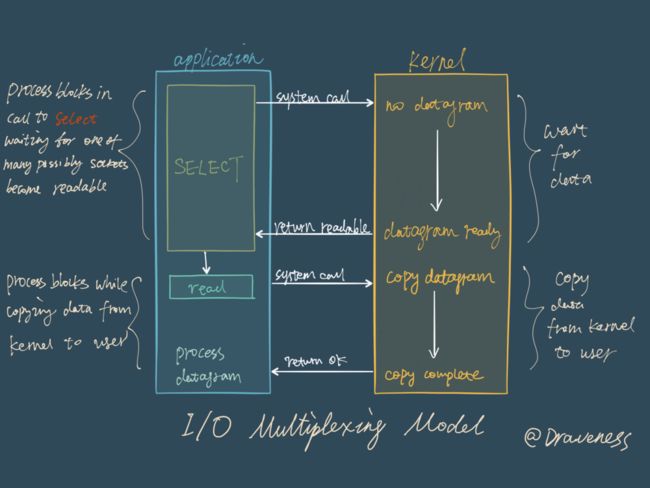
在 I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。
Reactor 设计模式
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)

文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。
I/O 多路复用模块
I/O 多路复用模块封装了底层的 select、epoll、avport 以及 kqueue 这些 I/O 多路复用函数,为上层提供了相同的接口。
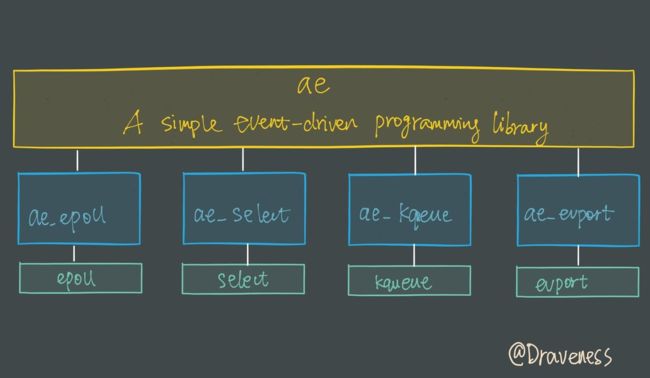
简要了解该模块的功能,整个 I/O 多路复用模块抹平了不同平台上 I/O 多路复用函数的差异性,提供了相同的接口.
子模块的选择
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口;在 Redis 中,我们通过宏定义的使用,合理的选择不同的子模块
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:

Redis 会优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 O(n),并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
总结
Redis 对于 I/O 多路复用模块的设计非常简洁,通过宏保证了 I/O 多路复用模块在不同平台上都有着优异的性能,将不同的 I/O 多路复用函数封装成相同的 API 提供给上层使用。
整个模块使 Redis 能以单进程运行的同时服务成千上万个文件描述符,避免了由于多进程应用的引入导致代码实现复杂度的提升,减少了出错的可能性。
问答
Redis为什么是单线程 ?
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽。(以上主要来自官方FAQ)既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求,参见:How fast is Redis?(https://link.zhihu.com/?target=https%3A//redis.io/topics/benchmarks)如果万一CPU成为你的Redis瓶颈了,或者,你就是不想让服务器其他核闲置,那怎么办?
那也很简单,你多起几个Redis进程就好了。Redis是keyvalue数据库,又不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。redis-cluster可以帮你做的更好。单线程模型
Redis客户端对服务端的每次调用都经历了发送命令,执行命令,返回结果三个过程。其中执行命令阶段,由于Redis是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个队列中,然后逐个被执行。并且多个客户端发送的命令的执行顺序是不确定的。但是可以确定的是不会有两条命令被同时执行,不会产生并发问题,这就是Redis的单线程基本模型。单线程模型每秒万级别处理能力的原因
(1)纯内存访问。 数据存放在内存中,内存的响应时间大约是 100纳秒 ,这是Redis每秒万亿级别访问的重要基础。
(2)非阻塞I/O ,Redis采用epoll做为I/O多路复用技术的实现 ,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了时间,不在I/O上浪费过多的时间。
(3)单线程 避免了线程切换和竞态产生的消耗 。
(4)Redis采用单线程模型,每条命令执行如果占用大量时间, 会造成其他线程阻塞,对于Redis这种高性能服务是致命的,所以Redis是面向高速执行的数据库。
内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。 epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性, 绝不在io上浪费一点时间
这3个条件不是相互独立的,特别是第一条,如果请求都是耗时的,采用单线程吞吐量及性能可想而知了。应该说redis为特殊的场景选择了合适的技术方案。
参考:
https://draveness.me/redis-io-multiplexing
https://blog.csdn.net/sunhuiliang85/article/details/73656830