Spark(六)————python API的调用以及几种模式的配置
1、python操作hbase
1.1 配置
0.启动hbase集群
如果时钟不同步,采用下面的方式进行同步处理。
$>su root
$>xcall.sh "ntpdate asia.pool.ntp.org"1.启动hbase的thriftserver,满足和第三方应用通信。
$>hbase-daemon.sh start thrift22.查看webui
http://s201:9095/ //webui端口
//9090 rpc端口3.下载windows下thrift的编译器,不需要安装,仅仅是个工具。
thrift-0.10.0.exe4.下载并安装thrift的python模块.
4.1)下载文件
thrift-0.10.0.tar.gz
4.2)tar开文件
4.3)进入目录
cmd>cd thrift-0.10.0\lib\py
cmd>setup.py install将thrift的pyhon文件放入python的site-package目录下
5.找到hbase中的hbase.thrift文件进行编译,产生python文件。
6.使用以下命令进行编译
cmd>thrift-0.10.0.exe -o ./out -gen py hbase.thrift7.创建idea的下的新模块,复制上面编译生成python文件到idea下(在out目录下,文件名称是hbase)。
1.2 编程python代码
本地模式下python操作
移除spark/conf/core-site.xml | hdfs-site.xml | hive-site.xml文件
[scala]
val rdd = sc.makeRDD(1 to 10)
rdd.map(e=>(e,1))
[python]
arr = [1,2,3,4]
rdd = sc.parellize(arr);
rdd.map(lambda e : (e,1))pyhon操作Hbase
#!/usr/bin/python
# -*-coding:utf-8-*-
import os
#导入thrift的python模块
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
#导入自己编译生成的hbase python模块
from mythrift.hbase import THBaseService
from mythrift.hbase.ttypes import *
#创建socket连接到s1:9090
transport=TSocket.TSocket("s1",9090)
transport=TTransport.TBufferedTransport(transport)
protocol=TBinaryProtocol.TBinaryProtocol(transport)
client=THBaseService.Client(protocol)
#打开传输端口
transport.open()
#put操作
table=b'ns1:t1'
row=b'row1'
v1=TColumnValue(b'f1',b'id',b'101')
v2=TColumnValue(b'f1',b'name',b'tomas')
v3=TColumnValue(b'f1',b'age',b'12')
vals=[v1,v2,v3]
put=TPut(row,vals)
client.put(table,put)
print("okkkk!")
#get操作
table=b'ns1:t1'
rowkey=b'row1'
col_id=TColumn(b'f1',b'id')
col_name=TColumn(b'f1',b'name')
col_age=TColumn(b'f1',b'age')
cols=[col_id,col_name,col_age]
get=TGet(rowkey,cols)
res=client.get(table,get)
print(bytes.decode(res.columnValues[0].value))
print(bytes.decode(res.columnValues[0].qualifier))
print(bytes.decode(res.columnValues[0].family))
print(res.columnValues[0].timestamp)
#删除
table=b'ns1:t1'
rowkey=b'row1'
col_id=TColumn(b'f1',b'id')
col_name=TColumn(b'f1',b'name')
col_age=TColumn(b'f1',b'age')
cols=[col_id,col_name,col_age]
#构造删除对象
delete=TDelete(rowkey,cols)
res=client.deleteSingle(table,delete)
#扫描
table = b'ns1:calllogs'
startRow = b'00,15778423030,20170208043827,0,17731088562,570'
stopRow = b'17,15338595369,20170410132142,0,15732648446,512'
dur = TColumn(b"f1", b"callDuration")
time = TColumn(b"f1", b"callTime")
caller = TColumn(b"f1", b"caller")
callee = TColumn(b"f1", b"callee")
cols = [dur, time,caller,callee]
scan = TScan(startRow=startRow,stopRow=stopRow,columns=cols)
r = client.getScannerResults(table,scan,100);
for x in r:
print("============")
print(bytes.decode(x.columnValues[0].qualifier))
print(bytes.decode(x.columnValues[0].family))
print(x.columnValues[0].timestamp)
print(bytes.decode(x.columnValues[0].value))
#关闭端口
transport.close()改造爬虫,使用hbase存放网页
1.创建hbase表pages
$hbase>create 'ns1:pages','f1'2.PageDao
#!/usr/bin/python
# -*-coding:utf-8-*-
import os
#导入thrift的python模块
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
#导入自己编译生成的hbase python模块
from mythrift.hbase import THBaseService
from mythrift.hbase.ttypes import *
from mythrift.hbase.ttypes import TResult
import base64
#创建socket连接到s1:9090
transport=TSocket.TSocket('s1',9090)
transport=TTransport.TBufferedTransport(transport)
protocol=TBinaryProtocol.TBinaryProtocol(transport)
client=THBaseService.Client(protocol)
#定义函数保存网页
def savePage(url,page):
#打开传输串口
transport.open()
#对url进行base64编码,形成bytes,作为rowkey
urlBase64Bytes=base64.encodebytes(url.encode('utf-8'))
#put操作
table=b'ns1:pages'
rowkey=urlBase64Bytes
v1=TColumnValue(b'f1',b'page',page)#创建page列
vals=[v1]
put=TPut(rowkey,vals)
client.put(table,put)#将数据存入table
transport.close()
#判断网页是否存在
def exists(url):
transport.open()
#对url进行base64编码,形成bytes,作为rowkey
urlBase64Bytes=base64.encodebytes(url.encode('utf-8'))
table=b'ns1:pages'
rowkey=urlBase64Bytes
col_page=TColumn(b'f1',b'page')
cols=[col_page]
get=TGet(rowkey,cols)
res=client.get(table,get)
transport.close()
return res.row is not NoneCraw
#!/usr/bin/python
# -*-coding:utf-8-*-
import urllib.request
import os
import re
import PageDao
#下载网页的方法
def download(url):
#判断当前的网页是否已经下载
resp=urllib.request.urlopen(url)
pageBytes=resp.read()
resp.close
if not PageDao.exists(url):
PageDao.savePage(url,pageBytes)
try:
#解析网页的内容
pageStr=pageBytes.decode("utf-8")
#解析href地址
pattern=u'
res=re.finditer(pattern,pageStr)
for r in res:
addr=r.group(1)
print(addr)
if addr.startswith("//"):
addr=addr.replace("//","http://")
#判断网页中是否包含自己的地址
if addr.startswith("http://") and url !=addr and (not PageDao.exists(addr)):
download(url)
except Exception as e:
print(e)
print(pageBytes.decode("gbk",errors='ignore'))
return
download("http://jd.com") 2、python实现spark数据分析
2.1 安装gnome-desktop,以便数据以图表展示
a)挂载CentOS-7-x86_64-DVD-1511.iso到光驱。
$>sudo mount /dev/cdrom /mnt/cdromb)本地安装gnome-desktop-xxx.rpm
$>sudo yum localinstall gnome-desktop-xxx.rpmc)或联网安装GNOME Desktop
$>sudo yum groupinstall "GNOME Desktop"d)修改centos的启动模式
$>sudo systemctl set-default graphical.targete)查看启动模式
$>sudo systemctl get-defaultf)启动桌面系统
$>sudo startxg)安装完成桌面系统后,如果出现read-only filesystem的错误.
$>sudo mount -o remount rw /2.2 centosX11 + putty实现远程访问centos的桌面程序
1.配置centos x11转发服务.
[/etc/ssh/sshd_config]
...
X11Forwarding yes
...2.重启sshd服务
$>sudo service sshd restart3.安装windows的Xming-6-9-0-31-setup.exe软件。
D:\downloads\tool\Mtputty\Xming-6-9-0-31-setup.exe4.启动Xming服务器
5.配置putty
mtputty -> s201 -> run putty config -> SSH -> X11 -> enable X11 forwarding -> save
display:localhost:06.验证,启动s201,输入firefox,在windows窗口中显式firefox浏览器。
2.3 编码实现
#导入sql
from pyspark.sql import Row
import matplotlib.pyplot as plt
import numpy as np
import pylab as P
plt.rcdefaults()
dataDir ="file:///home/centos/ml-data/ml-1m/users.dat"
lines = sc.textFile(dataDir)
splitLines = lines.map(lambda l: l.split("::"))
usersRDD = splitLines.map(lambda p: Row(id=p[0],gender=p[1],age=int(p[2]), occupation=p[3], zipcode=p[4]))
usersDF = spark.createDataFrame(usersRDD)
usersDF.createOrReplaceTempView("users")
usersDF.show()
#生成直方图
ageDF = spark.sql("SELECT age FROM users")
ageList = ageDF.rdd.map(lambda p: p.age).collect()
ageDF.describe().show()
plt.hist(ageList)
plt.title("Age distribution of the users\n")
plt.xlabel("Age")
plt.ylabel("Number of users")
plt.show(block=False)
#密度图
from scipy.stats import gaussian_kde
density = gaussian_kde(ageList)
xAxisValues = np.linspace(0,100,1000)
density.covariance_factor = lambda : .5
density._compute_covariance()
plt.title("Age density plot of the users\n")
plt.xlabel("Age")
plt.ylabel("Density")
plt.plot(xAxisValues, density(xAxisValues))
plt.show(block=False)
#生成嵌套子图
plt.subplot(121)
plt.hist(ageList)
plt.title("Age distribution of the users\n")
plt.xlabel("Age")
plt.ylabel("Number of users")
plt.subplot(122)
plt.title("Summary of distribution\n")
plt.xlabel("Age")
plt.boxplot(ageList, vert=False)
plt.show(block=False)
#柱状图
occ10 = spark.sql("SELECT occupation, count(occupation) as usercount FROM users GROUP BY occupation ORDER BY usercount DESC LIMIT 10")
occ10.show()
occTuple = occ10.rdd.map(lambda p:(p.occupation,p.usercount)).collect()
occList, countList = zip(*occTuple)
occList
y_pos = np.arange(len(occList))
plt.barh(y_pos, countList, align='center', alpha=0.4)
plt.yticks(y_pos, occList)
plt.xlabel('Number of users')
plt.title('Top 10 user types\n')
plt.gcf().subplots_adjust(left=0.15)
plt.show(block=False)
#堆栈条形图
occGender = spark.sql("SELECT occupation, gender FROM users")
occGender.show()
occCrossTab = occGender.stat.crosstab("occupation","gender")
occupationsCrossTuple = occCrossTab.rdd.map(lambda p:(p.occupation_gender,p.M, p.F)).collect()
occList, mList, fList = zip(*occupationsCrossTuple)
N = len(occList)
ind = np.arange(N)
width = 0.75
p1 = plt.bar(ind, mList, width, color='r')
p2 = plt.bar(ind, fList, width, color='y', bottom=mList)
plt.ylabel('Count')
plt.title('Gender distribution by occupation\n')
plt.xticks(ind + width/2., occList, rotation=90)
plt.legend((p1[0], p2[0]), ('Male', 'Female'))
plt.gcf().subplots_adjust(bottom=0.25)
plt.show(block=False)
#饼图
occupationsBottom10 = spark.sql("SELECT occupation,count(occupation) as usercount FROM users GROUP BY occupation ORDER BY usercount LIMIT 10")
occupationsBottom10Tuple = occupationsBottom10.rdd.map(lambda p:(p.occupation,p.usercount)).collect()
occupationsBottom10List, countBottom10List =zip(*occupationsBottom10Tuple)
explode = (0, 0.3, 0.2, 0.15,0.1,0,0,0,0,0.1)
plt.pie(countBottom10List, explode=explode,labels=occupationsBottom10List, autopct='%1.1f%%', shadow=True,startangle=90)
plt.title('Bottom 10 user types\n')
plt.show(block=False)3、Spark集群部署模式
Spark集群有以下几种部署模式:
1.local
2.standalone
3.mesos
4.yarnSpark闭包处理
运行job时,spark将rdd打碎变换成task,每个task由一个executor执行。执行之前,spark会进行task的闭包(closure)计算。闭包是指针对executor可见的变量和方法,以备在rdd的foreach中进行计算。闭包就是串行化后并发送给每个executor.
local模式下,所有spark程序运行在同一JVM中,共享对象,counter是可以累加的。原因是所有executor指向的是同一个引用。
cluster模式下,不可以,counter是闭包处理的。每个节点对driver上的counter是不可见的。只能看到自己内部串行化的counter副本。

3.1 Spark应用的部署模式
spark-submit --class xxx xx.jar --deploy-mode (client | cluster)
--deploy-mode 指定是否部署driver程序在worker节点上还是在client主机上。
[client模式]
driver运行在client主机上。client可以不在cluster中。
[cluster模式]
driver程序提交给spark cluster的某个worker节点来执行。worker是cluster中的一员。导出的jar需要放置到所有worker节点都可见的位置(如hdfs)才可以。
不论哪种方式,rdd的运算都在worker执行3.2 Spark集群的运行方式
主要是cluster manager的区别。
local
[standalone]
使用SparkMaster进程作为管理节点.
[mesos]
使用mesos的master作为管理节点。
[yarn]
使用hadoop的ResourceManager作为master节点。不用spark的master.不需要启动spark-master节点。worker节点也不需要启动。它不是用的hadoop的MR,spark的RDD是以线程的方式运行在hadoop的进程内。
确保HADOOP_CONF_DIR和YARN_CONF_DIR环境变量指向了包含了hadoop配置文件的目录。这些文件确保向hdfs写入数据并且连接到yarn的resourcemanager.这些配置分发到yarn集群,确保所有节点的配置是一致的。配置中设置的所有属性确保所有节点都能找到。
在yarn上运行spark应用,可以采用两种部署模式。cluster:driver运行在appmaster进程中。client:driver运行在client进程中,AppMaster只用于请求资源。
yarn模式 :--master yarn(yarn-site.xml)
standalone : --master spark://s2001:7077
mesos : --master mesos//xxx:xxx
spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] [app options]
//yarn + cluster模式
spark-submit --class com.it18zhang.spark.scala.DeployModeTest --master yarn --deploy-mode cluster hdfs://mycluster/user/centos/SparkDemo1-1.0-SNAPSHOT.jar
//yarn + cluster模式
spark-submit --class com.it18zhang.spark.scala.DeployModeTest --master yarn --deploy-mode client SparkDemo1-1.0-SNAPSHOT.jar 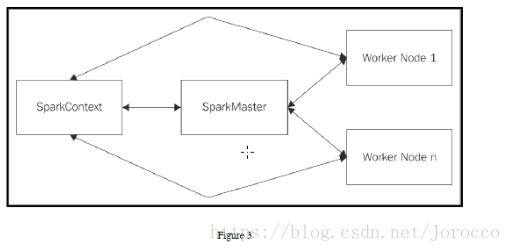
standalone模式
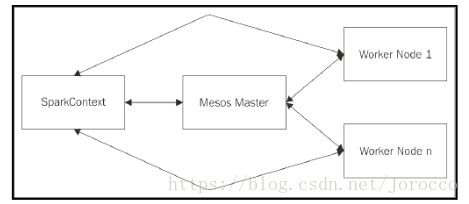
mesos模式

yarn模式
3.3 Spark启动脚本分析
sbin/start-all.sh --> sbin/start-master.sh --> sbin/start-config.sh --> export HADOOP_CONF_DIR=...
--> bin/load-spark-env.sh --> conf/spark-env.sh
sbin/start-all.sh -->sbin/start-slave.sh --> sbin/start-config.sh
--> bin/load-spark-env.sh
--> sbin/start-slave.sh
start-slave.sh --> sbin/start-config.sh
--> bin/load-spark-env.sh
修改/soft/sparl/conf/spark-env.sh
export HADOOP_CONF_DIR=/soft/hadoop/etc/hadoop
export SPARK_EXECUTOR_INSTANCES=3
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=500M
export SPARK_DRIVER_MEMORY=500M验证app的部署模式
1.启动spark集群
2.编程
import java.net.{InetAddress, Socket}
import org.apache.spark.{SparkConf, SparkContext}
/**
*
*/
object DeployModeTest {
def printInfo(str:String): Unit ={
val ip = InetAddress.getLocalHost.getHostAddress;
val sock = new Socket("192.168.231.205",8888);
val out = sock.getOutputStream;
out.write((ip + " : " + str + "\r\n").getBytes())
out.flush()
sock.close();
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("DeployModeTest")
conf.setMaster("spark://s201:7077")
val sc = new SparkContext(conf)
printInfo("hello world") ;
val rdd1 = sc.parallelize(1 to 10,3);
val rdd2 = rdd1.map(e=>{
printInfo(" map : " + e)
e * 2 ;
})
val rdd3 = rdd2.repartition(2)
val rdd4 = rdd3.map(e=>{
printInfo(" map2 : " + e)
e
})
val res = rdd4.reduce((a,b)=>{
printInfo("reduce : " + a + "," + b)
a + b ;
})
printInfo("driver : " + res + "")
}
}3.打包
jar
对于cluster部署模式,必须要将jar放置到所有worker都能够看到的地方才可以,例如hdfs。
4.复制到s201
5.提交job到spark集群。
//分发jar到所有节点的相同目录下
$>spark-submit --class com.it18zhang.spark.scala.DeployModeTest --master spark://s201:7077 --deploy-mode client SparkDemo1-1.0-SNAPSHOT.jar//上传jar到hdfs。
$>spark-submit --class com.it18zhang.spark.scala.DeployModeTest --master spark://s201:7077 --deploy-mode cluster hdfs://s201:8020/user/centos/SparkDemo1-1.0-SNAPSHOT.jar在提交作业时指定第三方类库
spark-submit ... --jars x,x,x 配置spark on yarn执行模式
1.将spark的jars文件放到hdfs上.
$>hdfs dfs -mkdir -p /user/centos/spark/jars
hdfs dfs -put 2.配置spark属性文件
[/spark/conf/spark-default.conf]
spark.yarn.jars hdfs://mycluster/user/centos/spark/jars/*3.提交作业
//yarn + cluster
spark-submit --class com.it18zhang.spark.scala.DeployModeTest --master yarn --deploy-mode cluster hdfs://mycluster/user/centos/SparkDemo1-1.0-SNAPSHOT.jar
//yarn + client
spark-submit --class com.it18zhang.spark.scala.DeployModeTest --master yarn --deploy-mode client SparkDemo1-1.0-SNAPSHOT.jar配置机架感知
和配置hadoop的机架感知一样,自己手动写一个机架感知类,然后将其加入spark的core-site.xml配置文件中。
cn.ctgu.hdfs.rackaware.MyRackAware2
[core-site.xml]
topology.node.switch.mapping.impl
cn.ctgu.hdfs.rackaware.MyRackAware2
Spark master HA模式
[描述]
只针对standalone和mesos集群部署情况。
使用zk连接多个master并存储state。
master主要负责调度。
master: SPOF
[配置]
[spark/conf/spark-env.sh]
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=s201:2181,s202:2181,s203:2181 -Dspark.deploy.zookeeper.dir=/spark"
spark.deploy.recoveryMode=ZOOKEEPER
spark.deploy.zookeeper.url=s201:2181,s202:2181,s203:2181
spark.deploy.zookeeper.dir=/spark/ha分发配置。
[启动方式]
1、直接在多个节点上启动master进程。自动从zk中添加或删除.
2、可通过指定多个master连接地址实现。
spark://host1:port1,host2:port2.